Crée des nœuds et les attachent au VFS pour un des fichiers générés par le framework Volatility.
Utilisation :
volatility –file pathToFile
Accessible par IHM :
Oui
Accessible par shell :
Oui
Lien vers la documentation :
Pas d’informations disponibles sur le site de DFF.
Modules DFF qui modifient les contenu du VFS
Nom :
carvergui
Description :
Cherche des fichiers utilisant des patterns prédéfinis ou des patterns définis par l’utilisateur. La recherche peut être par type de fichier et/ou la présence d’un pattern dans le header ou footer du fichier.
Utilisation :
Accessible par IHM :
Oui
Accessible par shell :
Non
Lien vers la documentation :
Pas d’informations disponibles sur le site de DFF.
Nom :
find
Description :
Cherche des fichiers utilisant un regexp Python.
Utilisation :
Accessible par IHM :
Oui
Accessible par shell :
Oui
Lien vers la documentation :
Pas d’informations disponibles sur le site de DFF.
Nom :
carver
Description :
Même fonctionnalité que le module « carvergui » mais pour le shell
Utilisation :
Accessible par IHM :
Non
Accessible par shell :
Oui
Lien vers la documentation :
Pas d’informations disponibles sur le site de DFF.
Nom :
carverui
Description :
?
Utilisation :
Accessible par IHM :
Non
Accessible par shell :
Oui
Lien vers la documentation :
Pas d’informations disponibles sur le site de DFF.
Pas d’informations disponibles sur le site de DFF.
Nom :
K800i
Description :
Permet de browser le contenu d’un téléphone k800i.
Utilisation :
Accessible par IHM :
Oui
Accessible par shell :
Oui
Lien vers la documentation :
Pas d’informations disponibles sur le site de DFF.
Nom :
K800i-Recover
Description :
Permet de récupérer une version précédente du système de fichiers d’un téléphone k800i.
Utilisation :
Accessible par IHM :
Oui
Accessible par shell :
Oui
Lien vers la documentation :
Pas d’informations disponibles sur le site de DFF.
Nom :
timeline
Description :
Isole des données concernant un nœud isolé dans un intervalle de temps spécifique.
Utilisation :
Accessible par IHM :
Oui
Accessible par shell :
Non
Lien vers la documentation :
Pas d’informations disponible sur le site de DFF.
Nom :
fileschart
Description :
Affiche des statistiques graphiques sur un nœud et ses enfants. Il est conçu pour indiquer quelle proportion de chaque type de données est stockée dans le nœud.
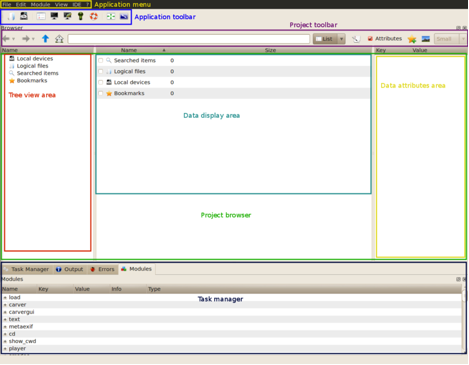
L’interface graphique de DFF est développée utilisant le framework PyQt qui est un framework graphique multi-plateformes donc DFF est capable de fonctionner sur plusieurs plateformes : Linix, FreeBSD, Windows(XP, Vista), MacOS. L’interface principale est composée de 4 zones principales :
« Application menus » – Les menus de l’application. Pour la définition détaillée de tous les menus, veuillez consulter la page suivante du wiki DFF.
« Application toolbar » – La barre d’outils est utilisée pour effectuer des actions telles que l’ajout d’un container des données ou d’un disc en DFF, ou l’ouverture de vues graphiques. Pour la définition détaillée de la barre d’outils, veuillez consulter la page suivante du wiki DFF.
« Project Browser » – La zone où les résultats des analyses seront affichés. Il peut être comparé à un navigateur de fichiers sur un système d’exploitation. Pour la définition détaillée du « project bowser », veuillez consulter la page suivante du wiki DFF.
« Project Toolbar » Cette zone serve à modifier l’affichage des résultats d’analyse et de naviguer dans les résultats de l’analyse.
« Task Manager » – Zone qui montre l’historique des tâches exécutées, les messages d’erreurs et d’information générés par l’exécution des différents modules et la liste des modules qui peuvent être utilisés, avec la liste des paramètres, qu’ils peuvent prendre en entrée. Pour la définition détaillée du « task manager », veuillez consulter la page suivante du wiki DFF.
L’interface graphique de DFF
Cas pratique IHM (chercher des fichiers d’images dans un container EWF)
Ce cas pratique a comme but de charger un container de données EWF et de chercher des fichiers de type JPG.
Les étapes du cas pratique sont les suivantes :
charger le container des données ;
monter le système de fichiers contenu dans le container ;
chercher des fichiers d’images sur le système de fichiers ;
sauver les fichiers retrouvés sur le disque.
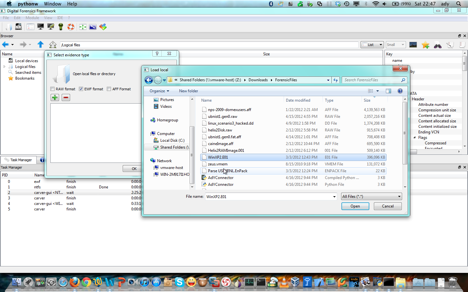
Charger le container de données
Dans le menu File-> « Open evidence file(s) » ou dans la barre d’outils click sur l’icône . Ensuite on choisit le container de données a charger (voir la figure suivante).
Chargement d’un container de données dans l’IHM de DFF
Même si c’est n’est pas visible, l’IHM de DFF a utilisé le module ewf pour créer n VFS.
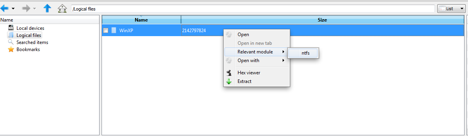
Monter le système de fichiers contenu dans le container
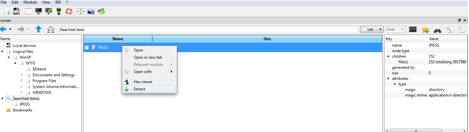
Une fois le container chargé, il faut monter le système de fichiers. DFF est capable de savoir que le container chargé contient un système de fichiers NTFS et vas automatiquement utiliser le module ntfs. Pour appliquer le module ntfs sur le container il faut aller dans le « Data display area » et faire un click droit ensuite choisir l’option « Relevant module » (voir la figure suivante). On voit ensuite apparaitre l’arborescence du disque après le traitement par le module NTFS.
Chargement d’un système de fichiers NTFS dans l’IHM de DFF
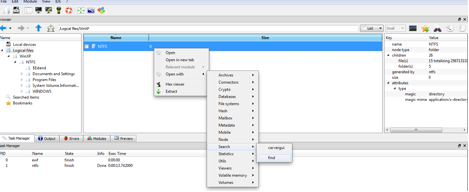
Chercher des fichiers d’images sur le système de fichiers
Une fois le système de fichiers chargé, on peut naviguer sur ce système de fichiers ou on peut appliquer des modules pour récupérer d’informations. On appliquera le module find sur le nœud NTFS (voir figure suivante) :
L’utilisation du module “find” sur un noeud NTFS
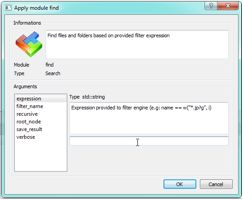
Le module find accepte quelques paramètres comme le nom du filtre (ce nom sera utilisé pour créer un nouveau nœud dans le VFS contenant les résultats de la recherche), si la recherche est récursive ou pas, l’expression utilisée pour rechercher des fichiers (dans notre cas l’expression sera name == w(“*.jp?g”, i)).
Les paramètres du module “find”
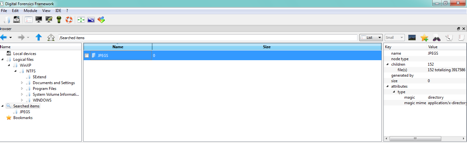
Le module find a trouvé des fichiers et a stocké les résultats dans le nouveau nœud du VFS nommé comme le nom du filtre. Ce nouveau nœud est attaché au noeud « Searched Items » (voir la figure suivante).
Le résultats de l’exécution du module “find”
Sauver les fichiers retrouvés sur le disque
La dernière étape consiste à extraire les résultats trouvés a l’étape précédente sur le disque. Pour transformer un nœud du VFS en fichier (physique) sur le disque, il faut utiliser le module extract.
L’utilisation du module “extract”
L’interface en ligne de commande de DFF
A part l’interface graphique, DFF a aussi une interface en ligne de commande (CLI). Il y a deux façons de démarrer l’interface en ligne de commande :
a partir de l’IHM de DFF en cliquant sur l’icône (shell) dans la barre d ‘outils
en exécutant la commande dff.py à partir d’une console.
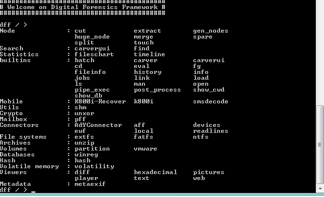
L’utilisation de l’interface en ligne de commande suit le même patron de conception (‘’pattern’’) que l’utilisation de l’IHM. Dans la figure suivante, on peut voir tous les modules disponibles à partir de la ligne de commande.
L’interface en ligne de commande de DFF
Les scripts sont une des nouvelles fonctionnalités de la version 1.2 de DFF. Les scripts sont des fichiers contenant des commandes shell DFF et peuvent être exécutés utilisant la ligne de commande suivante dff.py –b leFichierDeScript.
Cas pratique scripting (chercher des fichiers d’images dans un container EWF)
On prend le même cas pratique que celui utilisé pour illustrer l’utilisation de l’IHM. Le script qui exécute les mêmes actions que celles de l’IHM est le suivant :
#charger le container de données utilisant le module ewf ewf WinXP2.E01#monter le système de fichiers utilisant le module ntfsntfs WinXP#utiliser le module find pour chercher des fichiersfind /WinXP/NTFS --filter_name jpg_images --recursive --save_result
--expression 'name==w("*.jp?g",i)'
#utiliser le module extract pour stocker sur disque les images
#retrouvées par le module find extract --recursive --files Searched\ items/jpg_images --syspath ./
L’idée des scripts DFF semble être très bonne, pourtant dans la version actuelle, l’implémentation ne semble pas totalement achevée. Parmi les principaux défauts de cette implémentation, le plus évident est le fait de ne pas pouvoir récupérer le code de retour de l’exécution d’une commande (module). La deuxième faiblesse est l’absence totale d’instructions conditionnelles et des boucles. Ces deux défauts rendent impossible la création et l’exploitation des scripts automatiques pour la plateforme DFF.
Le produit commercial DFF Live
Depuis le mois de Juin 2012, ArxSys commercialise un produit basé sur DFF, appelé « DFF Live » [DFFLIVE]. DFF Live est livré sur une clé USB et est présenté comme un laboratoire d’investigation digitale nomade.
D’après la société ArxSys, le produit « DFF Live » a des fonctionnalités d’investigation numérique des systèmes vivants (liste de connexions réseaux, extraction des fichiers de temporaires, collection des données volatiles) et des fonctionnalités d’investigation numérique a froid (analyse des différents systèmes des fichiers, analyse des journaux d’évènements Windows, récupération des données cachées et supprimées).
Conclusion
Le framework DFF est un produit assez nouveau, mais pourtant il commence à avoir une certaine reconnaissance internationale. Le produit est présent dans certaines distributions numériques comme DEFT, BackTrack et SAN SIFT. DFF est facile à installer et l’interface graphique est ergonomique et facile a utiliser. Techniquement parlant, DFF a certains atouts : il est multi-plateformes, la notion de système de fichiers virtuel (VFS) rend la compréhension du framework plus facile, la possibilité d’étendre les fonctionnalités de base par l’ajout des modules écrits en Python. Par contre, DFF manque cruellement d’une documentation claire et précise, surtout pour les développeurs (il n’y a pas de documentation de l’api Python concernant le VFS).
Digital Forensic Framework [DFF] est un logiciel open source développé par ArxSys[ARXSYS]. C’est un nouvel arrivant dans le monde des logiciels d’investigation numérique. Il se veut être multiplateforme, automatisable, portable et modulaire.
DFF est un outil d’analyse et présentation de données et il est capable d’extraire, analyser et mettre en corrélation des traces suspectes et des données de différents fichiers, provenant d’acquisitions de supports numériques, tels que les disques durs, la mémoire vive ou les téléphones cellulaires. Il peut également être utilisé pour récupérer des données supprimées.
Écrit en Python et C++, il est multi-plateforme, hautement modulaire et personnalisable. L’interface graphique est développée avec PyQt [PYQT]. L’interfaçage et les transformations entre Python et C++ sont obtenus grâce à Swig [SWIG].
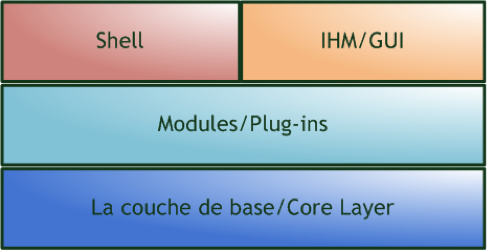
DFF est divisé en quatre différentes couches logicielles (voir la figure suivante), communiquant entre elles par une interface de programmation applicative (API) : la couche de base (Core Layer), les modules, l’interface utilisateur et le shell.
Les couches logicielles de DFF
La couche de base de DFF
Cette couche peut être considérée comme le cœur du framework. Elle fait l’interface avec le système d’exploitation et est utilisée pour charger et exécuter les modules. L’exécution des modules est automatique car la couche de base est conçue pour savoir quel module est requis et ensuite l’exécuter. Cette couche offre également aux modules la possibilité de renvoyer les données analysées sous la forme de nœuds (dans un arbre).
L’espace mémoire où ces nœuds sont créés est appelé un Système de Fichiers Virtuel (VFS pour Virtual File System). Chaque nœud peut être généré par un module différent et avoir des attributs spécifiques. Ce mécanisme permet à la couche de base de générer des rapports en mettant en corrélation toutes les données en provenance des modules, tout en restant indépendant des modules eux-mêmes. Même si un module plante après la création des nœuds, la couche de base sera en mesure d’exploiter ces nœuds. Les modules étant conçus pour l’investigation numérique, ils permettent aussi de révéler les données non allouées et cachées.
DFF offre aux utilisateurs une vue arborescente des données analysées. Par exemple, si un système de fichiers NTFS est analysé, tout son contenu sera visible dans l’interface graphique DFF, sous la forme d’un arbre: chaque répertoire contenant des fichiers et des répertoires, eux-mêmes contenant des fichiers et des répertoires, et ainsi de suite. DFF agit plus ou moins comme un navigateur de fichiers sur n’importe quel système d’exploitation. Dans DFF ces fichiers et répertoires sont appelés nœuds. Les nœuds sont créés par des modules suite à une analyse des données.
Les nœuds sont stockés dans un espace mémoire appelé VFS (Virtual File System). Le VFS peut être vu comme un système de fichiers en lecture seule utilisés par DFF pour stocker les nœuds. Lorsque DFF est lancé, une et une seule instance de VFS est créée ; dans d’autres termes, VFD est un singleton.
Les VFS contient la liste de tous les nœuds et chacun des nœuds contient un pointeur vers le nœud de son parent (ou NULL pour le nœud racine) et une liste de pointeurs vers ses enfants (le cas échéant).
Un nœud peut représenter pratiquement n’importe quel type de données. Une fois qu’il est créé, il devrait être ajouté au VFS afin qu’il puisse être visible dans l’interface graphique ou shell. Les deux caractéristiques importantes d’un nœud sont son nom et sa taille Si rien n’est défini, les valeurs par défaut sont une chaîne vide pour le nom et 0 octet pour la taille.
Mais ces informations pourraient ne pas suffire. Nous avons dit qu’un nœud peut représenter n’importe quel type de données. Si l’on prend comme exemple, un fichier d’un système de fichiers, le nœud aura un nom et une taille (donnés par le système de fichiers) mais aussi beaucoup d’autres informations telles que les métadonnées, les pointeurs pour indiquer la position de son contenu sur le système de fichiers, etc.
Dans DFF, ces informations supplémentaires sont appelées des attributs étendus. Ces attributs sont composés d’une liste de paires clé/valeur, où la clé doit être une chaîne de caractères.
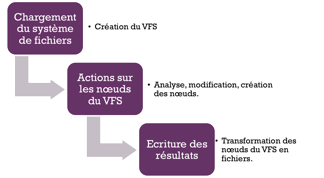
Les modules DFF
Chaque module DFF est conçu pour analyser un type spécifique de données, tels que les systèmes de mémoire RAM de fichiers, ou des cadres du réseau. Les modules créent des nœuds, les attachent au VFS, et en fonction du type de données, génèrent des informations supplémentaires telles que les indications de temps ou métadonnées d’extraction.
La version actuelle de la DFF (1.2 au moment de la rédaction du présent rapport) est livrée avec de nombreux modules qui effectuent des tâches diverses : le traitement des images mémoire des téléphones mobiles, la visualisation des films et des images, la génération des statistiques sur un nœud ou un ensemble de nœuds. Comme toutes les tâches d’analyse dans DFF sont effectuées via des modules, l’interface de programmation (API) a un grand nombre de fonctionnalités disponibles. Des modules supplémentaires peuvent être écrits en C++ ou Python.
Les modules contenus en DFF peuvent être classées en 3 catégories (voir le schéma suivant):
les modules qui chargent des systèmes de fichiers/volumes/partitions.
les modules qui actionnent sur les nœuds du VFS.
les modules qui matérialisent les nœuds du VFS en fichiers sur disque.
Classification des modules DFF
Modules qui chargent des systèmes de fichiers/volumes/partitions
Le tableau suivant liste les modules DFF.
Fonctionnalité
Module
Shell
IHM
Commentaire
Container de données
local
Oui
Oui
ewf
Oui
Oui
aff
Oui
Oui
Pas d’information disponible
device
Oui
Oui
readlines
Oui
Oui
Pas d’information disponible
Partition
partition
Oui
Oui
vmware
Oui
Oui
Système des fichiers
fat
Oui
Oui
ntfs
Oui
Oui
efs
Oui
Oui
Contenu du RAM
volatility
Oui
Oui
Pas d’information disponible
Modules qui actionnent sur les nœuds du VFS
Une fois que le système de fichiers est chargé, DFF offre une vue arborescente du système de fichiers, arborescence sur laquelle d’autres modules sont capables de travailler. Parmi les fonctionnalités offerts, on peut trouver des modules qui affichent le contenu d’un nœud (hexadecimal, diff, picture, text, web, player), des modules qui sont capables des chercher des nœuds ayant certains caractéristiques (find, carver).
Le tableau suivant liste les modules DFF.
Fonctionnalité
Module
Shell
IHM
Commentaire
Chercher
find
Oui
Oui
carver
Oui
Non
carverui
Oui
Non
Pas d’information disponible
carvergui
Non
Oui
Pas d’information disponible
Visualiser
hexadecinal
Oui
Oui
diff
Oui
Oui
pictures
Non
Oui
text
Oui
Oui
player
Non
Oui
Pas d’information disponible
web
Non
Oui
Pas d’information disponible
Archiver
unzip
Oui
Oui
Chiffrement
unxor
Oui
Oui
Base de données
Winreg
Oui
Oui
Hachage
hash
Oui
Oui
Métadonnées pour les images
metaexif
Oui
Oui
Téléphones mobiles
smsdecode
Oui
Oui
Pas d’information disponible
k800i
Oui
Oui
Pas d’information disponible
K800-i-Recover
Oui
Oui
Pas d’information disponible
Statistiques
timeline
Non
Oui
fileschart
Non
Oui
Pas d’information disponible
Modules qui matérialisent les nœuds du VFS en fichiers sur disque
La dernière étape d’une analyse avec DFF est la récupération des résultats qui consistent donc à matérialiser un ou plusieurs nœuds du VFS dans des fichiers sur disque.
Fonctionnalité
Module
Shell
IHM
Commentaire
Ecrire nœuds sur disque
extract
Oui
Oui
Pas d’information disponible
Modules définis par l’utilisateur
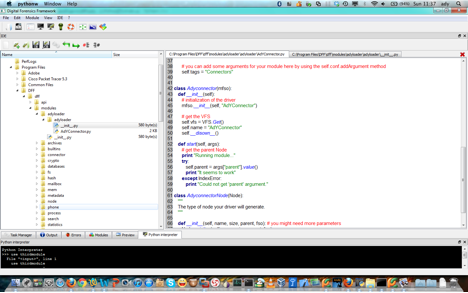
DFF offre la possibilité à l’utilisateur de créer ses propres modules utilisant l’IDE inclus dans DFF. L’IDE de DFF peut être utilisé pour générer des squelettes des scripts DFF, de modules ou de modules graphiques. Pour le lancer, vous pouvez utiliser l’icône de la barre d’outils d’application ou à partir du menu IDE -> Open.
La figure suivante présente une capture d’écran de l’IDE de DFF :
L’ide de DFF
La partie gauche est utilisée pour naviguer sur le système de fichiers et pour sélectionner le fichier à ouvrir (seuls les fichiers Python peut être ouvert). Pour ouvrir un fichier cliquez deux fois sur son nom et son contenu sera affiché.
Voici la description des différentes icônes de la barre d’outils:
New empty file : Ouvre un fichier vide dans l’IDE.
Generate skeleton : Lance l’assistant pour générer le squelette d’un nouveau module.
Open file : Ouvre un fichier existant.
Save : Sauve le fichier.
Save as : Sauve un fichier sous un nom choisi par l’utilisateur.
Load : Compile le module et le charge dynamiquement en DFF.
Undo : Annule l’action précédente.
Redo : Répete l’action precedente.
Comment : Commente la ligne sur laquelle le curseur de la souris se trouve.
Uncomment : « Dé-commente » la ligne sur laquelle le curseur de la souris se trouve.
L’IDE de DFF permet de créer très rapidement un squelette d’un module et donc facilite la tâche du développeur. Par contre, pour créer un module ayant une certaine utilité, il faut aussi connaître l’API (Python) de DFF.
Ainsi que mentionne dans le chapitre introductif, le processus d’investigation numérique peut être décomposé en trois catégories d’activités: l’acquisition, l’analyse et la présentation. La présentation de l’état de l’art des outils d’investigation numérique sera organisée autour des ces trois catégories, en distinguant entre l’état de l’art des outils d’acquisition des données et l’état de l’art des outils d’analyse et de présentation des données.
Les outils d’acquisition des données permettent d’examiner et ensuite de stocker les données dans des containers de données conçus spécialement pour l’investigation numérique. Un paragraphe sera réservé à la présentation de ces containers des données.
Les containers des données
En général, les containers de données présentes certaines fonctionnalités supplémentaires par rapport à une image brute (RAW). Ces fonctionnalités supplémentaires peuvent concerner la vérification de la cohérence interne, la compression, le cryptage.
En revanche, le format d’image RAW est essentiellement une copie bit à bit des données brutes d’un disque et ne permet pas en général de stocker des métadonnées. Cependant, il arrive que certains outils stockent les métadonnées dans des fichiers secondaires. Le format RAW a été à l’origine utilisé par l’outil Unix dd, mais il est pris en charge par la plupart des applications faisant de l’investigation numérique.
Les formats ouverts
AFF (Advanced Forensic Format)
AFF [AFF] est un format de fichier ouvert et extensible pour stocker des images de disques et des métadonnées associées. En utilisant AFF, l’utilisateur n’est pas dépendent d’un format propriétaire qui peut limiter la façon dont il ou elle peut mener son travail.
Un standard ouvert permet aux enquêteurs d’utiliser rapidement et efficacement leurs outils préférés pour recueillir des renseignements ou résoudre les incidents de sécurité.
AFF offre un design extensible et flexible :
Design extensible. AFF prend en charge la définition des métadonnées arbitraires en stockant toutes les données sous forme de noms et de paires de valeurs, appelés segments. Certains segments stockent des données du disque et d’autres stockent des métadonnées. En raison de cette conception générale, toutes les métadonnées peuvent être définies en créant simplement un nouveau nom et une paire de valeurs. Chacun des segments peut être comprimé afin de réduire la taille des images et des valeurs de hachages cryptographiques peuvent être calculées pour chaque segment pour assurer l’intégrité des données.
Design flexible. Pour plus de flexibilité, il existe trois variantes de fichiers AFF – AFF, AFD et AFM et des outils librement disponibles pour convertir facilement les fichiers d’un format a l’autre. Le format original AFF est représenté par un seul fichier, contenant des segments avec les données du disque et des métadonnées. Son contenu peut être compressé, mais il peut être assez grand puisque les données des disques durs modernes atteignent souvent 100 Go en taille. Pour faciliter le transfert, les fichiers AFF peuvent être divisés en plusieurs fichiers au format AFD. Les fichiers AFD (qui ont une taille plus reduite) peuvent être facilement manipulés sur des supports qui limitent la taille de fichiers à 2 Go, tel que par exemple le système de fichiers FAT ou DVD. Le format AFM stocke les métadonnées dans un fichier AFF et les données du disque dans un fichier séparé brut (RAW file). Ce format permet à des outils d’analyse qui prennent en charge le format RAW d’accéder aux données, mais sans perdre les métadonnées.
AFF prend en charge deux algorithmes de compression : zlib, qui est rapide et raisonnablement efficace et LZMA, qui est plus lent, mais beaucoup plus efficace. Zlib est en effet le même algorithme de compression utilisé par EnCase. En conséquence, les fichiers AFF compressés avec zlib ont à peu près la même taille que les fichiers EnCase équivalents. Les fichiers AFF peuvent être re-comprimés en utilisant l’algorithme LZMA.
AFF2.0 supporte le chiffrement des images disque. Les images cryptées ne peuvent pas être accessibles sans la clé de déchiffrement nécessaire.
AFF4
AFF4 est une refonte complète du format AFF. AFF4 est orientée vers des corpus des images très grandes. AFF4 a une architecture orientée objet, tous les objets étant adressables par leur nom qui est unique. AFF4 définit un volume comme un mécanisme de stockage qui peut stocker un segment (bits de données binaires) par son nom et le récupérer aussi par le nom. Actuellement AFF4 a deux implémentations de volume: un répertoire et un fichier Zip.
L’implémentation du volume AFF4 sur un répertoire permet de stocker les segments sous forme de fichiers plats à l’intérieur d’un répertoire régulier sur le système de fichiers. Ceci est vraiment utile si l’on veut faire une image d’un système de fichiers FAT. Il est aussi possible de monter le répertoire sur une url http (par exemple, le répertoire commence avec http://somehost/url/). Cela permet d’utiliser l’image directement depuis le web – pas besoin de télécharger le volume entier.
L ‘implémentation du volume AFF4 sur un fichier Zip stocke les segments à l’intérieur d’une archive zip. Si l’archive est trop grand (plus de 4 Go), l’extension Zip64 est utilisée.
Gfzip (Generic Forensic Zip)
Gfzip [GFZIP] vise à fournir un format de fichier ouvert « compressé » et « signé » pour des fichiers d’image disque. Gfzip utilise l’algorithme SHA256 pour vérifier l’intégrité de données au lieu de SHA1 ou MD5. Les métadonnées fournies par l’utilisateur sont incorporées dans une section spéciale dans le fichier. Une autre fonctionnalité importante de gfzip est l’utilisation de données et métadonnées signées avec des certificats x509.
Sgzip
Introduit par le produit PyFlag (un outil pour faire de l’analyse numérique) et démarré comme un projet dans le département de la défense australien, sgzip est une variante du format gzip sur lequel on peut faire des recherches. En comprimant individuellement les blocs de données, sgzip permet de faire des recherches par mots-clés sur des images sans décompresser l’image entièrement.
Les formats propriétaires
EnCase
EnCase [ENCASE] est peut-être le standard de facto pour les containers de données utilisés dans l’investigation numérique, même si c’est un format propriétaire et complètement fermé. Ce format est largement basé sur le format ASR Data’s Expert Witness Compression Format.
Non seulement le format est compressible, il est également consultable. La compression est effectuée au niveau des blocks et permet de générer et de conserver des pointers vers des fichiers, pour améliorer la vitesse de la consultation. Les images EnCase peuvent être divisées en plusieurs fichiers (par exemple, pour l’archivage sur CD ou DVD). Le format restreint le type et la quantité des métadonnées qui peuvent être associés à une image.
Les formats IDIF, IRBF, IEIF de ILook
La société ILook [ILOOK] offre trois formats d’image propriétaires : un format comprimé (IDIF), un format non-compressé (IRBF) et un format crypté (IEIF). Bien que peu de détails techniques soient divulgués publiquement, la documentation en ligne fournit quelques indications: IDIF a un support pour «la journalisation des actions de l’utilisateur”. IRBF est semblable à IDIF, sauf que les images de disque ne sont pas compressées; IEIF, quant à lui, chiffre lesdites images. Les outils d’ILook permet la transformation de chacun de ces formats en format brut (RAW files).
Il y d’autres formats propriétaires moins connues comme ProDiscover, RAID (Rapid Action Imaging Device), SMART. Le tableau suivant récapitule les principales caractéristiques des différents formats des containers des données.
Extensible (supporte le stockage demétadonnéesarbitraire)
Non-Propriétaire
Compressé & recherchable
AFF
X
X
X
EnCase
X
ILook
?
X
Gfzip
X
Sgzip
X
X
SMART
X
ProDiscover
X
X
Les principales caractéristiques des différents formats de fichiers
Les outils d’acquisition des données
Dans la création d’une image numérique d’un disque d’un système d’information, on essaye de capturer une représentation aussi exacte que possible du média source. Un bon procédé de copie d’image, génère un duplicate exacte du média source en cours d’investigation. Par duplicate exacte on comprend une copie octet par octet du support original. Le processus de création d’une image numérique ne devrait pas modifier le support d’origine, il devrait parvenir à acquérir entièrement les données du média d’origine et ne pas introduire dans l’image crée des données qui ne sont pas présents sur le média source.
Travailler avec des preuves numériques d’origine peut être très dangereux parce que l’original peut être modifié ou détruit avec une relative facilité. En accédant les medias d’origine seulement une fois, pour générer la copie numérique, nous minimisons les possibilités de modifier l’original accidentellement. Un autre avantage de travailler sur une copie est qu’en cas de modification par erreur de la copie d’image, on peut générer un duplicata exact du support d’origine.
Une autre raison d’utiliser des outils d’acquisition des données est leur capacité a fournir des informations exhaustives. L’examen d’un système de fichiers tel que présenté par le système d’exploitation n’est pas suffisant pour un processus d’investigation numérique. La plupart des volumes contiennent des données potentiellement intéressantes qui ne sont pas visibles ; on peut appeler ces données, des “données supprimées”. Il y en a plusieurs catégories de “données supprimées” :
Les fichiers supprimés sont “les plus récupérables.” En général, cela se réfère à des fichiers qui ont été effacés de façon logique du disque; le fichier n’est plus présent lorsque l’utilisateur consulte un répertoire ; le nom du fichier, la structure des métadonnées et les données du fichier sont marqués comme «libres». Cependant, les connexions entre le nom du ficher, les métadonnées respectives et le contenu du fichier sont encore intactes et la récupération du fichier consiste à enregistrer le nom du fichier et des structures pertinentes de métadonnées, puis d’extraire son contenu.
Les fichiers orphelins sont similaires à des fichiers supprimés à l’exception du lien entre le nom du fichier et les métadonnées qui n’est plus exact. Dans ce cas, la récupération de données et des métadonnées est encore possible, mais il n’y a pas de corrélation directe entre le nom du fichier et les données récupérées.
Les fichiers non affectés sont les fichiers qui ont été supprimés et leurs noms et ou métadonnées ont été réutilisés par d ‘autres fichiers. Dans ce cas, le seul moyen de récupérer les informations est par l’utilisation du « data carving ». Seules les informations qui n’ont pas été allouées a d’autres fichiers pourront etre recuperees.
Les fichiers réécrits ce sont les fichiers dont une ou plusieurs de leurs unités de données ont ete réaffectées à un autre fichier. Le rétablissement complet n’est plus possible, mais la reprise partielle peut dépendre de la mesure de l’écrasement.
Matériels
DeepSpar Disk Imager
DiskImager [DEEPSPAR] est une solution matérielle pour faire une copie bit a bit du contenu d’un disque. Les disques source et cible sont connectés a un boitier qui lui même est connecté à un ordinateur. Le boitier est capable de commander le disque source en exécutant des commandes au niveau de l’interface SATA sans passer par des appels BIOS, ce qui facilite la récupération des zones de disque corrompues.
Contrairement aux outils d’investigation numérique, le DiskImager ne crée pas une image du disque source. Au lieu de cela, il utilise des commandes et des techniques pour copier tous les secteurs du disque source directement sur le disque de destination. Le disque de destination peut ensuite être utilisé par n’importe quel logiciel de récupération de données ou d’investigation numérique pour la récupération des données.
Volatility [VOLATILITY] est une collection d’outils complètement ouverts, développés en Python sous licence GPL, pour l’extraction des données de la mémoire volatile (RAM). L’extraction de données est réalisée complètement indépendemment du système d’exploitation utilisé, mais offre la possibilité d’avoir un aperçu de l’état d’exécution du système.
Volatility fournit actuellement des capacités d’extraction des données concernant les processus en cours, les sockets réseaux ouverts, les connections réseaux ouverts, les fichiers ouverts pour chaque processus, la mémoire adressée par processus, les modules du noyau chargés.
dd (Data Dump)
La commande dd[DD] est l’outil open-source fondamental necessaire pour créer une image d’un disque. Compte tenu du fait qu’il est presque universellement présent sur n’importe quel système d’exploitation Unix, il est la base de plusieurs autres utilitaires d’acquisition des données et l’apprentissage de son fonctionnement est important à n’importe quel examinateur.
L’utilisateur peut fournir des arguments divers et des drapeaux pour modifier ce comportement simple, mais la syntaxe de base de l’outil est assez claire.
Donc, pour faire un simple clone d’un disque à l’autre, il faut utiliser l’outil de la façon suivante:
dd if=/dev/sda of=/dev/sdb bs=4096
La commande lit par tranches de 4096 octets du disque /dev/sda vers le deuxième disque (/dev/sdb).
Le clonage d’un disque est intéressant, mais d’une utilité limitée pour un examinateur. Dans la plupart des cas, nous nous intéressons à la création d’une image numérique d’un fichier qui contient l’ensemble du contenu présent sur le disque source. Cette operation est egalement tres simple à effectuer en utilisant la même syntaxe.
$ dd if=/dev/sdg of=dd.img bs=32K
60832+0 records in60832+0 records out
1993342976 bytes (2.0 GB) copied, 873.939 s, 2.3 MB/s
Les éléments clés d’intérêt dans la sortie de la console pour la commande dd sont les lignes « records in » et « records out ». A ce titre, on peut observer tout d’abord que le nombre d’enregistrements lus et écrits est le même – cela indique qu’il n’y a pas de perte des données en raison d’une défaillance du disque, de l’échec d’écriture du fichier de sortie ou bien, pour toute autre raison.
dcfldd
Le projet dcfldd[DCFLDD] est un projet dérivé du projet dd, donc ses fonctionnalités sont similaires au dd. Toutefois, dcfldd a des capacités intéressantes qui ne se retrouvent pas dans dd. La plupart des fonctionnalités tournent autour de la création des valeurs de hachage, la validation, la journalisation de l’activité et la division du fichier de sortie en plusieurs fichiers de taille fixe. Les fonctions étendues de dcfldd, ainsi que les fonctions de dd peuvent être examinées en passant l’option –help pour la commande dcfldd.
dc3dd
dc3dd[DC3DD] est conçu comme un patch appliqué à GNU dd, plutôt qu’une variante de dd, de sorte que dc3dd est capable d’intégrer les modifications apportées sur dd plus rapidement que dcfldd.
dc3dd produit un journal de hachage à la console ainsi que dans un fichier passé dans l’argument hashlog. En outre, a la fin d’une opération, l’outil présente le nombre de secteurs écrits/lus plutôt que le nombre de blocs.
ewfacquire, ewfacquirestream
Les outils ewfacquire et ewfacquirestream font partie de la bibliothèque libewf [LIBEWF]. Ils peuvent créer des fichiers dans le format EnCase, FTK Imager et SMART. ewfacquire est destiné à lire à partir de périphériques et ewfacquirestream à partir des tuyaux (pipes). Ces deux outils peuvent calculer des valeurs de hachage MD5 quand les données sont en cours d’acquisition.
NED (The Open Source Network Evidence Duplicator)
NED [NED] est un outil d’acquisition et duplication de données plutôt unique dans son genre, puisqu’il utilise un modèle client-serveur. Le serveur stocke les données envoyées pas le client, le serveur et le client en communiquant par le protocole UDP. NED a une architecture ouverte qui accepte des plugins. Les plugins sont des modules qui se branchent dans NED et entendent les fonctionnalités pendant le processus d’acquisition. NED contient déjà les plugins suivants :
« Image Store Plugin« (crée une image dd du disc client), «Hash« (calcule les empreintes des fichiers acquis)
« String Search« (la recherche par mots clés)
« Carv« (pour la recherche des fichiers effacées)
« Compress Image Store« (comprimer les images acquises)
Malgré des débuts prometteurs, le projet NED est actuellement disparu, la dernière version téléchargeable datant de 2004.
FTK Imager
Le Forensic Toolkit Imager [FTKI] est une suite d’outils d’acquisition des données commercialisées par la société AccessData. FTK Imager est capable de stocker les images de disques le format ECase, SMART, dans le format brut (raw) mais aussi dans le format ISO/CUE.
D’autres outils sont disponibles sur la plateforme Unix/Linux ; Voici une liste non-exhaustive :
Le but des outils d’analyse des données est d’identifier, extraire et analyser les artefacts générés par les outils d’acquisition de données. L’identification consiste à déterminer les fichiers actifs ou supprimés, qui sont présents dans un container de données. L’extraction consiste dans la récupération des fichiers et des métadonnées pertinents. L’analyse est le processus d’examen de l’ensemble des données, qui idéalement conduit à des résultats probants.
Gratuit
The Sleuth KIT
TSK [TSK] est une collection d’outils UNIX en ligne de commande permettant de faire de l’investigation numérique. La collection contient une vingtaine d’outils et la majeure partie des outils sont nommés de façon logique, en indiquant la couche du système de fichiers sur laquelle ils opèrent et le type de résultat obtenu.
Les préfixes des noms des outils TSK sont:
« mm-» pour les outils qui travaillent sur des volumes (media management)
« fs- » pour les outils qui travaillent sur la structure du système de fichiers
« blk-» pour les outils qui travaillent sur les blocs des données.
« i-» pour les outils qui travaillent sur les métadonnées (inodes)
« f-» pour les outils qui travaillent sur les noms des fichiers
« j-» pour les outils qui travaillent sur le système de journalisation de système de fichiers.
« img-» pour les outils qui travaillent sur les images des systèmes de fichiers.
Les suffixes communs trouvés dans les outils TSK qui indiquent la fonction attendue du l’outil
sont les suivants:
«-stat » affiche des informations générales sur l’élément interrogé ; similaire à la commande “stat” sur les systèmes Unix.
« -ls » affiche le contenu de l’élément interrogé ; similaire à la commande “ls” sur les systèmes Unix.
« -cat » extrait le contenu de l’élément interrogé ; similaire à la commande “cat” sur les systèmes Unix.
Autopsy
Autopsy[AUTOPSY] est une interface graphique web pour le The Sleuth Kit.
Scalpel
Scalpel [SCALPEL] est un utilitaire pour faire du carving qui lit une base de données des définitions d’entêtes et des pieds de page (footers) et extrait des fichiers correspondants ou des fragments des fichiers a partir des images des disques ou des fichiers raw. Scalpel est Independent du système des fichiers et est capable de travailler sur des partitions FATx, NTFS, ext2/3, HFS+.
PyFLAG
PyFLAG [PYFLAG] est un outil d’analyse basé sur le langage Python. PyFLAG est une application web, donc un utilisateur n’a besoin que d’un simple navigateur Web pour effectuer un examen.
Étant une application web utilisant une base de données, donne à PyFLAG plusieurs avantages par rapport aux outils traditionnels d’investigation numérique, qui tendent à être utilisés par un seul utilisateur sur un seul système. Une instance PyFLAG peut supporter plusieurs utilisateurs sur un seul cas ou plusieurs utilisateurs travaillant sur des cas différents en parallèle. En plus du modèle de serveur, PyFLAG a quelques autres fonctionnalités qui en font un outil intéressant pour un examinateur en utilisant des outils open source.
PyFLAG dispose d’un système de fichiers unifié virtuel (VFS) pour tous les objets en cours d’examen. PyFLAG se réfère à chacun de ces éléments des inodes. Chaque élément chargé dans la base de données du PyFLAG reçoit un inode PyFLAG, en plus des métadonnées des l’élément. Cela signifie qu’on peut charger sous la même racine virtuelle des images de système de fichiers (quelque soit leur nombre), des captures du trafic réseau, des fichiers de journalisation et même des flux de données non structurées, ces informations pouvant être traitées par la suite traitées avec PyFLAG.
Fiwalk
Fiwalk[FIWALK] est une bibliothèque et une suite de programmes connexes visant à automatiser une grande partie de l’analyse du système de fichiers initial effectué lors d’une investigation numérique. Le nom vient de “file & inode walk», qui décrit les fonctions du programme. La sortie de Fiwalk est une cartographie des systèmes de fichiers d’un disque et les fichiers contenus, y compris les métadonnées de fichiers intégrés. L’objectif du projet Fiwalk est de fournir un langage de description XML normalisé pour le contenu d’un fichier contenant des données forensiques et de permettre un traitement plus rapide des données provenant d’une investigation numérique.
Parce que Fiwalk hérite les capacités d’analyse des systèmes de fichiers de TSK, il est capable de supporter n’importe quelle partition, volume ou structure du système de fichiers que TSK est capable de lire. En plus de sa sortie standard XML, Fiwalk peut fournir une sortie dans un format texte, un format TSK ou un format CSV.
Hachoir
Hachoir [HACHOIR] est un framework générique pour la manipulation de fichiers binaires. Ecrit en Python, il est indépendant du système d’exploitation et il peut accepter beaucoup d’interfaces graphiques utilisateur (ncurses, wxWidget, Gtk +). Bien qu’il contienne quelques fonctions de modification de fichiers, il est normalement prévu pour examiner des fichiers existants en étant capable actuellement de gérer plus d’une soixante des formats de fichiers. La reconnaissance du format de fichier est basée sur les en-têtes et il dispose aussi d’un analyseur tolérant aux défauts, conçu pour gérer les fichiers tronqués ou incomplets.
Hachoir permet de “naviguer” sur tout flux binaire, de la même manière qu’on peut naviguer sur des répertoires et des fichiers. Un fichier est divisé en un arbre de champs, où le plus petit champ est un bit. Il existe d’autres types de champs: des entiers, des chaînes de bits, etc.
Hachoir est composé d’un parseur principal (hachoir-core), des divers parseurs pour différents formats de fichier (hachoir-parser) et d’autres programmes périphériques.
Commercial
Forensics Toolkit
Forensic Toolkit [FTKI] est un outil qui permet de faire une analyse numérique complète. Pour la création des images de disques, FTK contiens le FTK Imager. Pour stocker les informations, FTK utilise une base de données, qui rend le produit accessible par plusieurs utilisateurs en mode concurrent. Le FTK Case Manager permet le stockage des preuves numériques mais aussi l’indexation des preuves.
XIRAF
Xiraf [XIRAF] est un outil d’analyse de données. Xiraf indexe et rend consultable les preuves numériques par l’extraction et l’organisation de l’information qui a de la valeur pour les enquêteurs. Xiraf est capable d’indexer des fichiers de métadonnées, des enregistrements d’historique du navigateur, des clés des registres, des propriétés des documents, emails, etc. Une fois que la preuve a été indexée, les enquêteurs recherchent les éléments de preuve à travers l’interface web de XIRAF. Avec cette interface, les enquêteurs peuvent combiner des recherches utilisant des multiples dimensions comme le temps, l’emplacement et le contenu.
L’investigation numérique en est encore à ses balbutiements compte tenu de son existence relativement courte, ainsi que du rythme rapide du changement technologique. Cette situation se traduit par de nombreux défis et controverses avec lesquels les communautés juridiques et judiciaires doivent se débattre. Les défis sont nombreux. Un premier défi est lié à la vitesse de changement des technologies informatiques. Un autre défi est de trouver un consensus au sein de la communauté scientifique pour trouver et établir les bonnes pratiques d’un processus d’investigation numérique.
L’investigation numérique est à l’origine d’une collision entre deux forces apparemment irréductibles: le système juridique d’une coté qui fonctionne à un rythme relativement lent et de l’autre coté la communauté de l’investigation numérique qui est en contact avec la technologie qui avance et évolue a la vitesse de l’éclair.
Du point de vue technologique, l’investigation numérique est confrontée a deux nouvelles technologies qui soulèvent des sérieux défis: l’informatique dans les nouages (cloud computing) et les disques SSD (Solid State Drive). Dans l’état actuel, l’investigation numérique dans un de ces environnements pourrait très bien être irrécupérable pour des raisons soit techniques ou juridiques (ou les deux). Ces technologies sont en usage aujourd’hui et représentent un problème pour lequel il n’existe pas de solution facile.
L’informatique dans les nuages peut être un rêve devenu réalité pour ceux qui travaillent dans l’industrie de l’information, mais cela représente un cauchemar pour ceux qui traitent avec des preuves numériques. Les principaux défis sont de deux ordres, l’un technique et l’autre juridique. Le défi technique est lié a l’impossibilité d’accéder à distance au contenu effacé puisque il y a des fortes chances que le disque qui contenait cette information ait été déjà réutilisé pour stocker un autre contenu. Le défi juridique est lié aux juridictions multiples qui peuvent s’appliquer aux données, aux applications et/ou aux fournisseur de services dans les nouages.
Les mémoires SSD posent un défi technique lié à l’effacement des fichiers. L’écriture d’une cellule d’une mémoire SSD doit passer d’abord par le reset du contenu de la cellule, ce qui diminue fortement les performances en écriture du disc. Pour combler ce manque de performance, les cellules sont resetées lors de l’effacement des fichiers soit par le système de l’exploitation via la commande TRIM, soit directement par le contrôleur du SSD. Donc, lors de l’effacement d’un fichier, le contenu du fichier est complètement perdu, ce qui pose des problèmes lors des investigations numériques.
Dans [DUVAL] (chapitre 1.1), Duval fait un état de l’art des processus de formalisation d’investigation numérique.
La formalisation de McKemmish
Le premier model présenté est le modèle de McKemmish [KEMMISH] qui propose de décomposer l’étude de l’attaque d’un système informatique en 4 étapes :
Identification de la preuve digitale : sert a identifier les éléments pouvant contenir des indices et des preuves. Cela permet de déterminer les outils qui devront être utilisés pendant la phase d’analyse.
Préservation de la preuve digitale. Cette phase est une phase critique puisque dans certains cas les preuves digitales doivent être présentées comme pièces à conviction devant une instance judiciaire.
Analyse de la preuve digitale. Le but de cette phase est de transformer les données brutes dans une forme compréhensible par toute personne impliquée dans l’enquête.
Présentation de la preuve digitale. Le but de cette phase est de présenter les résultats aux personnes intéressées, qui ne sont pas forcément spécialistes du domaine.
McKemmish décrit aussi les quatre règles principales qui doivent être respectées par un logiciel d’analyse numérique afin que les résultats produits puissent être recevables :
Une modification minimale des données d’origine
Documentation de tout changement de la preuve digitale intervenu pendant l’analyse.
Le respect des règles de bon usage des outils pour ne pas corrompre l’ensemble de l’analyse et pour ne pas modifier la signification des données
Ne pas surestimer ses connaissances et ses capacités. Dans le cas ou l’enquêteur n’a pas les compétences pour analyser la preuve, il aura besoin soit de se mette à niveau, soit de se faire assister.
La formalisation de Mandia et Procise
Un autre modèle de formalisation est celui proposé pas Mandia et Procise dans le livre « Incident Response and Computer Forensics » [MANDIA]. Leur méthodologie comprend sept étapes majeures :
« Pre-incident preparation » : Prendre des mesures pour préparer l’organisation avant l’apparition d’un incident.
« Detection of incidents » : Identifier un potentiel incident (informatique) de sécurité.
« Initial response » : Réaliser une enquête initiale et l’enregistrement des preuves concernant l’incident, la création de l’équipe de réponse aux incidents et l’information des personnes qui ont besoin de savoir de l’existence de l’incident.
« Formulate response strategy » : Sur la base des résultats de tous les faits connus, déterminer la meilleure réponse et obtenir l’approbation de la direction de la société.
« Investigate the incident » : Effectuer une collecte complète de données. Passer en revue les données recueillies pour déterminer la cause de l’incident, le moment de sa survenance, la personne a son origine et la manière dont elle a agi et enfin, la manière dont on peut prévenir à l’avenir ce type d’incidents.
« Reporting » : Indiquer les informations relative a l’enquête d’une manière précise et utile aux décideurs.
« Resolution » : Appliquer les mesures de sécurité et des changements de procédure, et développer à long terme des correctifs pour remédier aux problèmes identifiés
Les sept composants de la réponse a un incident
La formalisation du projet CTOSE
Un troisième modèle de formalisation est celui proposé par le projet européen CTOSE (Cyber Tools On-line Search for Evidence) [CTOSE]. Dès le départ, le but du projet CTOSE a été d’élaborer un modèle de processus de référence ressemblant à des lignes directrices organisationnelles, techniques et juridiques sur la façon dont une entreprise doit procéder lorsqu’un incident informatique se produit. L’objectif de ce modèle se focalise sur l’acquisition d’éléments de preuve numérique et le processus a suivre pour améliorer la collecte, le stockage, la sécurité et l’analyse des données, de manière a ce qu’elles soient légalement admissibles dans les procédures judiciaires.
Le schéma suivant illustre les différentes composantes du projet CTOSE et explique la manière dont le modèle de référence est lié aux exigences techniques, juridiques et de présentation.
Les éléments du projet CTOSE
Le modèle ci-dessus de processus de référence comporte cinq phases liées: la phase de préparation, la phase d’exécution, la phase d’évaluation, la phase d’enquête et la phase d’apprentissage. Ce modèle de processus décrit les actions et les décisions qui doivent être menées dans le cadre d’une enquête concernant des attaques informatiques. Des informations supplémentaires, concernant notamment les rôles et responsabilités spécifiques, l’ensemble de compétences requises, listes et guides d’autres documents de référence, les outils et conseils juridiques sont également prévus pour faciliter l’action et/ou la décision a chaque phase.
Les phases du processus du modèle CTOSE
Le projet CTOSE n’est plus maintenu depuis 2004, le domaine Internet du projet (www.ctose.org) étant en vente.
La formalisation EDIP (Enhanced Digital Investigation Process)
Dans [EDIP], Baryamureeba et Tushabe proposent un modèle d’investigations informatiques basé sur 5 phases :
« Readiness Phases » : Pendant cette phase, l’enquêteur vérifie s’il est prêt à effectuer l’enquête. Cette vérification porte notamment sur la qualité des équipements et le niveau l’expérience de l’enquêteur.
« Deployment Phases » ; Cela correspond à l’arrivée sur les lieux de l’incident et aux premières observations faites par les enquêteurs.
« Physical Crime Scene Investigation Phases » : L’objectif de cette phase est de récolter et conserver toutes les preuves physiques potentielles (disques durs, disquettes, etc.) pour ensuite les analyser.
« Digital Crime Scene Investigation Phases » : L’objectif de cette phase est d’analyser les éléments de preuve récoltes pour tenter de comprendre ce qui s’est passé.
« Review Phase » : cette phase correspond au débriefing.

















You must be logged in to post a comment.