The goal of this ticket is to briefly present the most important components of the Apache Hadoop ecosystem.![]()
Apache Hadoop – software library is a framework that allows for the distributed processing of large data sets across clusters of computers using simple programming models.
The overall picture of the Hadoop technology stack is the following one:
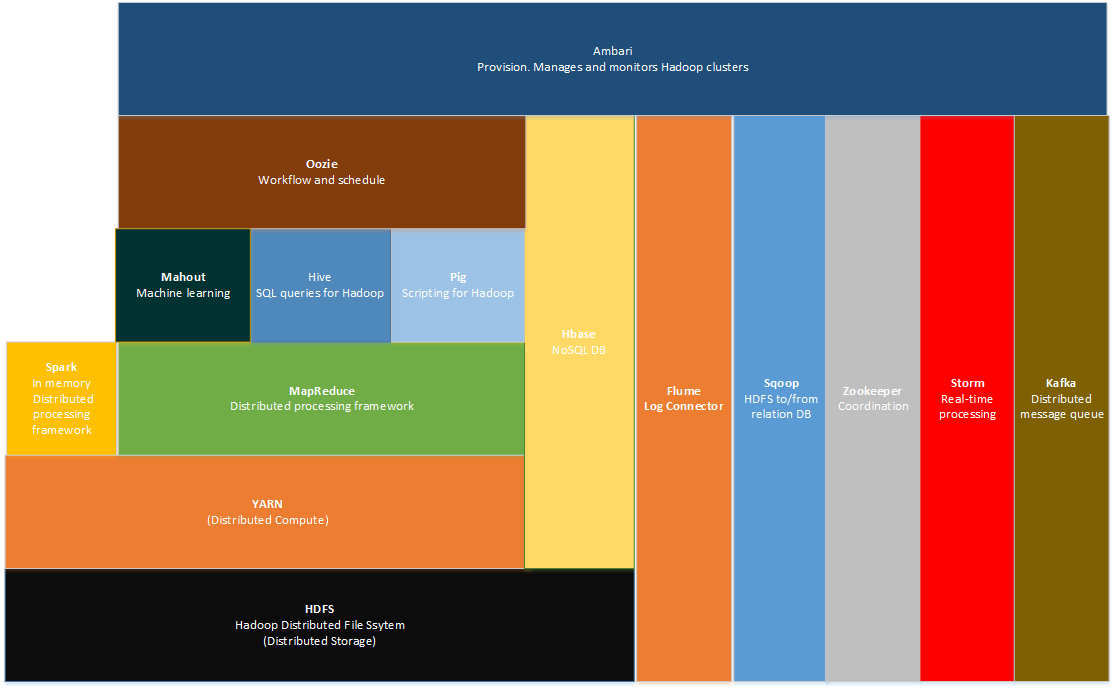
- Hadoop Distributed File System (HDFS)
- A distributed file system that provides high-throughput access to application data.
- Files are splitted and written in “blocks” across different cluster machines.
- All files “blocks” are replicated to at least 3 nodes of the cluster.
- Replication factor can be changed for each file or folder.
- HDFS architecture follows the master-slave model
- name node:
- it handles the files metadatas, names, sizes, paths.
- it knows on which date nodes each file “block” was written.
- data node
- it stores the data itself (file “blocks”) and have no concept of file.
- the writing of a file follows the following workflow:
- the client ask to the name node where it can write file/s.
- data node it answers with a list of data nodes.
- client writes the files to the data nodes.
- the data nodes are taking care of the “blocks” replication.
- name node:
- YARN
- A distributed compute and processing framework.
- YARN is moving the processes (usually Java classes) to the machine that stores the data that the process needs; this is the opposite comparing with what happens in the classical client-server architecture where the server sends the needed data to the process.
- This architecture have the following advantages:
- data can be processed on the node where it is stored.
- the process capacity of the cluster is not restricted by the transfer capacity of the network.
- Apache MapReduce
- Is a generic approach for parallel processing.
- Hides the complexity of the cluster management (fault tolerance, load balancing).
- The MapReduce jobs are written in Java language.
- Apache SQOOP
- Tool designed for efficiently transferring bulk data between HDFS and structured datastores such as relational databases.
- Ideal for importing entire tables.
- Apache Flume
- Designed for high-volume data streaming into HDFS.
- Useful for reading applications/server logs, ingesting social media content and sensors datas.
- Data flow model:
- Flume source receives an event from an external data source
- The Flume source post the event in a channel.
- the Flume Sink removes the event from the channel and stores it in HDFS (or other data source type).
- Complex data flows can be build using this data flow.
- DistCP (Distributed Copy)
- Tool included in the the Haddop distribution.
- It copies HDFS directories from one cluster to another.
- WebHDFS
- Included in the core Hadoop distribution.
- A REST API to interact with the HDFS.
- Apache Pig
- Scripting ETL language for distributed data handling (“scripting for Hadoop”).
- Pig scripts are compiled into MapReduce jobs.
- Can call user defined functions written in Java or Python.
- Is good for simple processing data operations and interactive querying especially for semi-structured data.
- Apache Hive
- Declarative analysis language similar to SQL (“SQL queries for Hadoop”).
- As Pig, the Hive SQL scripts are compiled into MapReduce jobs.
- There is a separation between data and schema; both can change separately.
- Data can be stored in HDFS (or other file systems) and metadatas can be stored in a DBMS.
- Is good to work in structured data.
If you want to see what are the differences between Pig and Hive please read Difference between Pig and Hive-The Two Key Components of Hadoop Ecosystem.
- Apache Storm
- Real-time processing engine.
- Spouts
- source of data, messages from Apache Kafka or Twitter streaming API.
- Bolts
- processing of the input streams and will produce new inputs streams.
- most of the logic goes into bolts.
- A Storm application is a Directed Acyclic Graph (DAG) of spouts and bolts.
- Apache Spark
- In-memory distributed computing framework.
- Improved performance compared to Apache MapReduce.
- Used for near real-time streaming.
- Apache Oozie
- A workflow engine and scheduler for Hadoop.
- Can call Hive and Pig scripts.
- Is good for building repeatable workflows of common Hadoop jobs.
- Is good for composing smaller jobs into larger more complex ones.
- Apache Mahout
- A library of machine learning algorithms designed for Hadoop.
- Runs the algorithms as MapReduce jobs.
- Apache HBase
- NoSQL database running on top of HDFS.
- Apache Kafka
- Distributed message queue.
- Interoperable with Apache Storm.
- Apache ZooKeeper
- Is a centralized service for maintaining configuration information.
- Can also be used outside the Hadoop ecosystem.
- Apache Ambari
- The goal is make the Hadoop cluster management simpler.

You must be logged in to post a comment.