The goal of this ticket is to explain how to create an extension for the Burp Suite Professional taking as implementation example the “Reverse Tabnabbing” attack.
“Reverse Tabnabbing” is an attack where an (evil) page linked from the (victim) target page is able to rewrite that page, such as by replacing it with a phishing site. The cause of this attack is the capacity of a new opened page to act on parent page’s content or location.
The attack vectors are the HTML links and JavaScript window.open function so to mitigate the vulnerability you have to add the attribute value: rel="noopener noreferrer" to all the HTML links and for JavaScriptadd add the values noopener,noreferrer in the windowFeatures parameter of the window.openfunction. For more details about the mitigation please check the OWASP HTML Security Check.
Basic steps for (any Burp) extension writing
The first step is to add to create an empty (Java) project and add into your classpath the Burp Extensibility API (the javadoc of the API can be found here). If you are using Maven then the easiest way is to add this dependency into your pom.xml file:
In order to find the Tabnabbing vulnerability we must scan/parse the HTML responses (coming from the server), so the extension must extend the Burp scanner capabilities.
The interface that must be extended is IScannerCheck interface. The BurpExtender class (from the previous paragraph) must register the custom scanner, so the BurpExtender code will look something like this (where ScannerCheck is the class that extends the IScannerCheck interface):
public class BurpExtender implements IBurpExtender {
@Override
public void registerExtenderCallbacks(
final IBurpExtenderCallbacks iBurpExtenderCallbacks) {
// set our extension name
iBurpExtenderCallbacks.setExtensionName("(Reverse) Tabnabbing checks.");
// register the custom scanner
iBurpExtenderCallbacks.registerScannerCheck(
new ScannerCheck(iBurpExtenderCallbacks.getHelpers()));
}
}
Let’s look closer to the methods offered by the IScannerCheck interface:
consolidateDuplicateIssues – this method is called by Burp engine to decide whether the issues found for the same url are duplicates.
doActiveScan – this method is called by the scanner for each insertion point scanned. In the context of Tabnabbing extension this method will not be implemented.
doPassiveScan – this method is invoked for each request/response pair that is scanned. The extension will implement this method to find the Tabnabbing vulnerability. The complete signature of the method is the following one: List<IScanIssue> doPassiveScan(IHttpRequestResponse baseRequestResponse). The method receives as parameter an IHttpRequestResponse instance which contains all the information about the HTTP request and HTTP response. In the context of the Tabnabbing extension we will need to check the HTTP response.
Parse the HTTP response and check for Tabnabbing vulnerability
As seen in the previous chapter the Burp runtime gives access to the HTTP requests and responses. In our case we will need to access the HTTP response using the method IHttpRequestResponse#getResponse. This method returns a byte array (byte[]) representing the HTTP response as HTML.
In order to find the Tabnabbing vulnerability we must parse the HTML represented by the HTML response. Unfortunately, there is nothing in the API offered by Burp for parsing HTML.
The most efficient solution that I found to parse HTML was to create few classes and interfaces that are implementing the observer pattern (see the next class diagram ):
The most important elements are :
IByteReader interface – this interface represents the Subject (or Observable) from the Observer pattern. This interface has methods for attach and notify the observers.
HTMLAnchorReaderObserver class – this class implements the IByteReaderObserver interface and is capable to find the HTML anchor tag and check if it is vulnerable to Tabnabbing problem.
JSWindowsOpenReaderObserver class – this class implements the IByteReaderObserver interface and is capable to find the window.open function call and check if it is vulnerable to Tabnabbing problem.
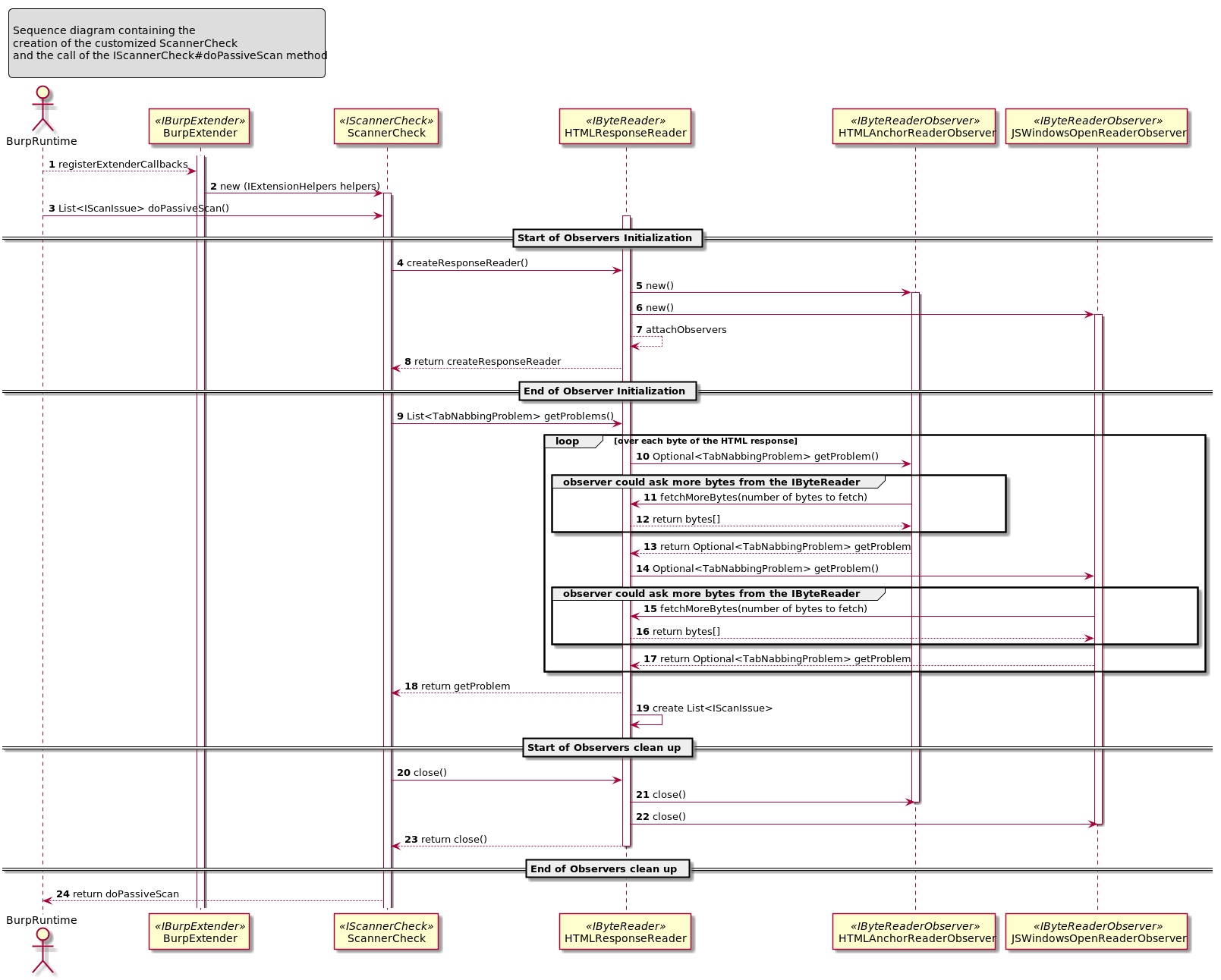
The following sequence diagram try to explains how the classes are interacting together in order to find the Tabnabbing vulnerability.
Final words
If you want to download the code or try the extension you can find all you need on github repository: tabnabbing-burp-extension.
If you are interested about some metrics about the code you can the sonarcloud.io: tabnnabing project.
own normal dataset – public ; accessing 3 days of the sites from Alexa 1000
Used the pro ids product to capture different logs:
connection.log/s
ssl.log/s
x509.log/s
All this logs will be aggregated in order to create ssl aggregations and then generate a ssl-connect-units (each ssl-connect-unit represents a SSL connection). Each ssl-connect-unit have a source IP, destination IP, destination port, protocol and other 40 features (properties) like number of packages, number of bytes, number of different certificates, ratio of established and not established states .
A data set was created from all this ssl-connection-units and machine learning algorithms have been used against this dataset.
(ML) Algorithms used
XGBoost (Extreme Gradient Boosting)
Random forest
Neural network
svm
After using all this ML algorithms the features that have been identified as the most important ones to detect malware traffic:
The talk was about malware brute force attacks of WordPress web sites which is the most used CMS product.
historical overview of the brute-force malware
2009 – first distributed brute force attack against WordPress
2013 – firstDisco also isntalled backdoors in the system
2014 – Mayhem
2015 – Aetra
2015 – CMS Catcher
2015- Troldeshkey
2017 – Stantinko
multiple cloud severs, all using same Fail2ban jail.
How can make the different servers communicate.
In security operations most of the workflows are manual despite of multitude of solutions.
Different scenarios on which the automation could help a lot:
firewall role propagation scenario
drop propagation scenario
prevent known threats scenario
capture threat activity scenario
How to do the orchestration: using Adaptive Network Protocol (ANP)
developed so that nodes can share event information with each other
This books makes a great job explaining how the “bricks” of the Internet (HTTP, HTML, WWW, Cookies, Script Languages) are working (or not) from the security point of view. Also a very systematic coverage of the browser (in)security is done even if some of the information it starts to be outdated. The book audience is for web developers that are interested in inner workings of the browsers in order to write more secure code.
Chapter 1 Security in the world of web applications
This goal of this chapter is to set the scene for the rest of book. The main ideas are around the fact that security is non-algorithmic problem and the best ways to tackle security problems are very empirical (learning from mistakes, develop tools to detect and correct problems, and plan to have everything compromised).
Another part of the chapter is dedicated to the history of the web because for the author is very important to understand the history behind the well known “bricks” of the Internet (HTTP, HTML, WWW) in order to understand why they are completely broken from the security point of view. For a long time the Internet standards evolutions were dominated by vendors or stakeholders who did not care much about the long-term prospects of technology; see the Wikipedia Browser Wars page for a few examples.
Part I Anatomy of the web (Chapters 2 to 8)
The first part of the book is about the buildings blocks of the web: the HTTP protocol, the HTML language, the CSS, the scripting languages (JavaScript, VBScript) and the external browser plug-ins (Flash, SilverLight). For each of these building blocks, the author presents how are implemented and how are working (or not) in different browsers, what are the standards that supposed to drive the development and how these standards are very often incomplete or oblivious of security requirements.
In this part of the book the author speaks only briefly about the security features, knowing that the second part if the book supposed to be focused on security.
Part II Browser security features (Chapter 9 to 15)
The first security feature presented is the SOP (Same Policy Origin), which is also the most important mechanism to protect against hostile applications. The SOP behaviour is presented for the DOM documents, for XMLHttpRequest, for WebStorage and how the security policies for cookies could also impact the SOP.
A less known topic that is treated is the SOP inheritance; how the SOP is applied to pseudo-urls like about:, javascript: and data:. The conclusion is that each browser are treating the SOP inheritance on different ways (which can be incompatible) and it is preferable to create new frames or windows by pointing them to a server-suplied blank page with a definite origin.
Another less known browser features (that can affect the security) are deeply explained; the way the browsers are recognizing the content of the response (a.k.a content sniffing), the navigation to sensitive URI schemes like “javascript:”, “vbscript:”, “file:”, “about:”,“res:” and the way the browsers are protecting itself against rogue scripts (in the case of the rogue scripts protection the author is pointing the inefficiently of the protections).
The last part is about different mechanisms that browsers are using in order to give special privileges to some specific web sites; the explained mechanisms are the form-based password managers, the hard-coded domain names and the Internet Explorer Zone model.
Part III Glimpse of things to come (Chapter 16 to 17)
This part is about the developments done by the industry to enhance the security of the browsers,
For the author there are two ways that the browser security could evolve; extend the existing frameworks/s or try to restrict the existing framework/s by creating new boundaries on the top of existing browser security model.
For the second alternative the following solutions are presented: W3C (former Mozilla) Content Security Policy , (WebKit) Sandboxed frames and Strict Transport Security.
The last part is about how the new planned APIs and features could have impact on the browser and applications security. Very briefly are explained the “Binary HTTP”, WebSocket (which was not yet a standard when the book was written), JavaScript offline applications, P2P networking.
Chapter 18 Common web vulnerabilities
The last chapter is a nomenclature of different known vulnerabilities grouped by the place where it can happen (server side, client side). For each item a brief definition is done and links are provided towards previous chapters where the item has been discussed.
I will start with the conclusion because it’s maybe the most important part of this review.
For me this is a must read book if you want to write more robust (web and non web) applications in Java, it covers a very large panel of topics from the basics of securing a web application using HTTP/S response headers to handling the encryption of sensitive informations in the right way.
Chapter 1: Web Application Security Basics
This chapter is an introduction to the security of web application and it can be split in 2 different types of items.
The first type of items is what I would call “low-hanging fruits” or how you could improve the security of your application with a very small effort:
The use of HTTP/S POST request method is advised over the use of HTTP/S GET. In the case of POST the parameters are embedded in the request body, so the parameters are not stored and visible in the browser history and if used over HTTPS are opaques to a possible attacker.
The use of the HTTP/S response headers:
Cache-Control – directive that instructs the browser how should cache the data.
X-Frame-Options – response header that can be used to indicate whether or not a browser should be allowed to render a page in a <frame>, <iframe> or <object> . Sites can use this to avoid clickjacking attacks, by ensuring that their content is not embedded into other sites.
X-XSS-Protection – response header that can help stop some XSS atacks (this is implemented and recognized only by Microsoft IE products).
The second types of items are more complex topics like the input validation and security controls. For this items the authors just scratch the surface because all of this items will be treated in more details in the future chapters of the book.
Chapter 2: Authentication and Session Management
This chapter is about how a secure authentication feature should work; under the authentication topic is included the login process, session management, password storage and the identity federation.
The first part is presenting the general workflow of login and session management (see next picture) and for every step of the workflow some dos and don’t are described.
login and session management workflow
The second part of the chapter is about common attacks on the authentication and for each kind of attack a solution to mitigated is also presented. This part of the chapter is strongly inspired from the OWASP Session Management Cheat Sheet which is rather normal because one of the authors (Jim Manico) is the project manager of the OWASP Cheat Sheet Series.
Even if you are not implementing an authentication framework for you application, you could still find good advices that can be applied to other web applications; like the use of the use of the secured and http-only attributes for cookies and the increase of the session ID length.
Chapter 3: Access Control
The chapter is about the advantages and pitfalls of implementing an authorization framework and can be split in three parts.
The first part describes the goal of an authorization framework and defines some core terms:
subject : the service making the request
subject attributes : the attributes that defines the service making the request.
group : basic organizational structure
role : a functional abstraction that uniquely describe system collaborators with similar or unique duties.
object : data being operating on.
object attributes : the attributes that defines the type of object being operating on.
access control rules : decision that need to be made to determine if a subject is allowed to access an object.
policy enforcement point : the place in code where the access control check is made.
policy decision point : the engine that takes the subject, subject attributes, object, object attributes and evaluates them to make an access control decision.
policy administration point : administrative entry in the access control system.
The second part of the chapter describes some access control (positive) patterns and anti-patterns.
Some of the (positive) access control patterns: have a centralized policy enforcement point and policy decision point (not spread through the entire code), all the authorization decisions should be taken on server-side only (never trust the client), the changes in the access control rules should be done dynamically (should not be necessary to recompile or restart/redeploy the application).
For the anti-patterns, some of then are just opposite of the (positive) patterns : hard-coded policy (opposite of “changes in the access control rules should be done dynamically”), adding the access control manually to every endpoint (opposite of have a centralized policy enforcement point and policy decision point)
Others anti-patterns are around the idea of never trusting the client: do not use request data to make access control policy decisions and fail open (the control access framework should cope with wrong or missing parameters coming from the client).
The third part of the chapter is about different approaches (actually two) to implement an access control framework. The most used approach is RBAC (Role Based Access Control) and is implemented by some well knows Java access control frameworks like Apache Shiro and Spring Security. The most important limitation of RBAC is the difficulty of implementing data-specific/contextual access control. The use of ABAC (Attribute Based Access Control) paradigm can solve the data-specific/contextual access control but there are no mature frameworks on the market implementing this.
Chapter 4: Cross-Site Scripting Defense
This chapter is about the most common vulnerability found across the web and have two parts; the presentation of different types of cross-site scripting (XSS) and the way to defend against it.
XSS is a type of attack that consists in including untrusted data into the victim (web) browser. There are three types of XSS:
reflected XSS (non persistent) – the attacker tampers the HTTP request to submit malicious JavaScript code.Reflected attacks are delivered to victims via e-mail messages, or on some other web site. When a user clicks on a malicious link, submitting a specially crafted form the injected code travels to the vulnerable web site, which reflects the attack back to the user’s browser. The browser then executes the code because it came from a “trusted” server.
stored XSS (persistent XSS) – the malicious script is stored on the server hosting the vulnerable web application (usually in the database) and it is served later to other users of the web application when the users are loading the vulnerable page. In this case the victim does not require to take any attacker-initiated action.
DOM-based XSS – the attack payload is executed as a result of modifying the DOM “environment” in the victim’s browser.
For the defense techniques the big picture is that the input validation and output encoding should fix (almost) all the problems but very often various factors needs to be considered when deciding the defense technique.
Chapter 5: Cross-Site Request Forgery Defense and Clickjacking
The chapter dedicated to the Cross-Site Request Forgery (CSRF) have the same structure as the previous chapter (dedicated to the XSS); the first part defines the CSRF and how it works and the second part defines mitigations strategies.
CSRF is an attack that can be used to force the victim to trigger unwanted actions on a web application in which they’re currently authenticated.
CSRF and XSS can be related in the sense that a XSS vulnerability could be used in order to embed a CSRF attack in the victim web site but most importantly a XSS vulnerability can be used to avoid the CSRF defenses; XSS can be used to read any (CSRF) tokens from any page or a XSS vulneariblity can be used to access cookies not having the HTTPOnly flag.
The following mitigations techniques are presented:
synchronizer token pattern – an anti-CSRF token is created and stored in the user session and in a hidden field on subsequent form submits. At every submit the server checks the token from the session matches the one submitted from the form. Tomcat 6+ implements this pattern; for more infos please see CSRF Protection Filter.
double-cookie submit pattern – when a user authenticates to a site, the site should generate a (cryptographically strong) pseudo-random value and set it as a cookie on the user’s machine separate from the session id. The site does not have to save this value in any way, thus avoiding server side state. The site then requires that every transaction request include this random value as a hidden form value (or other request parameter). A cross origin attacker cannot read any data sent from the server or modify cookie values, per the same-origin policy. The AngularJS framework implements this pattern out of the box; see Cross Site Request Forgery (XSRF) Protection
challenge/response pattern – the solution consists in forcing the user a value known only to him in order to complete the action.
Chapter 6: Protecting Sensitive Data
This chapter is articulated around three topics; how to protect (sensitive) data in transit, how to protect (sensitive) data at rest and the generation of secure random numbers.
How to protect the data in transit
The standard way to protect data in transit is by use of cryptographic protocol Transport Layer Security (TLS). In the case of web applications all the low level details are handled by the web server/application server and by the client browser but if you need a secure communications channel programmatically you can use the Java Secure Sockets Extension (JSSE). The authors recommendations for the cipher suites is to use the JSSE defaults.
Another topic treated by the authors is about the certificate and key management in Java. The notions of trustore and keystore are very well explained and examples about how to use the keytool tool are provided. Last but not least examples about how to manipulate the trustores and keystores programmatically are also provided.
How to protect data at rest
The goal is how to securely store the data but in a reversible way, so the data must be wrapped in protection when is stored and the protection must be unwrapped later when it is used.
For this kind of scenarios, the authors are focusing on Keyczar which is a (open source) framework created by Google Security Team having as goal to make it easier and safer the use cryptography for the developers. The developers should not be able to inadvertently expose key material, use weak key lengths or deprecated algorithms, or improperly use cryptographic modes.
Examples are provided about how to use Keyczar for encryption (symmetric and asymmetric) and for signing purposes.
Generation of secure random numbers
Last topic of the chapter is about the Java support for the generation of secure random numbers like the optimal way of using the java.security.SecureRandom (knowing that the implementation depends on the underlying platform) and the new cryptographic features of Java8 (enhance of the revocation certificate checking, TLS Server name indication extension).
Chapter 7: SQL Injection and other injection attacks
This chapter is dedicated to the injections attacks; the sql injection being treated in more details that the other types of injection.
SQL injection
The sql injection mechanism and the usual defenses are very well explained. What is interesting is that the authors are proposing solutions to limit the impact of SQL injections when the “classical” solution of query parametrization cannot be applied (in the case of legacy applications for example): the use of input validation, the use of database permissions and the verification of the number of results.
Other types of injections
XML injection, JSON-Based injection and command injection are very briefly presented and the main takeaways are the following ones:
use a safe parser (like JSON.parse) when parsing untrusted JSON
when received untrusted XML, an XML schema should be applied to ensure proper XML structure.
when XML query language (XPath) is intermixed with untrusted data, query parametrization or encoding is necessary.
Chapter 8: Safe File Upload and File I/O
The chapter speaks about how to safety treat files coming from external sources and to protect against attacks like file path injection, null byte injection, quota overloaded Dos.
The main takeaways are the following ones: validate the filenames (reject filenames containing dangerous characters like “/” or “\”), setting a per-user upload quota, save the file to a non-accessible directory, create a filename reference map to link the actual file name to a machine generated name and use this generated file name.
Chapter 9: Logging, Error Handling and Intrusion Detection
Logging
What should be be logged: what happened, who did it, when it happened, what data have been modified, and what should not be logged: sensitive information like sessions IDs, personal informations.
Some logging frameworks for security are presented like OWASP ESAPI Logging and Logback. If you are interested in more details about the security logging you can check OWASP Logging Cheat Sheet.
Error Handling
On the error handling the main idea is to not leak to the external world stacktraces that could give valuable information about your application/infrastructure to an attacker. It is possible to prevent this by registering to the application level static pages for each type of error code or by exception type.
Intrusion Detection
The last part of the chapter is about techniques to help monitor end detect and defend against different types of attacks. Besides the “craft yourself” solutions, the authors also re presenting the OWASP AppSensor application.
Chapter 10: Secure Software Development Lifecycle
The last chapter is about the SSDLC (Secure Software Development Life Cycle) and how the security could be included in each steps of development cycle. For me this chapter is not the best one but if you are interested about this topic I highly recommend the Software Security: Building Security in book (you can read my own review of the book here, here and here).
CISSP Boxed Set – This box set contains a study guide and a book with practice exams. I used the study guide only punctually for specific topics and I found it very complete. I tried at the beginning the use it as the main source of information but the main problem is the huge quantity of information (1400 pages).
Practice Exams
McGraw-Hill Education CISSP Practice Exams – Free practice exams offered by Shon Harris. The practice exams are covering all the domains and I found it quite challenging. For me, if you are able to answer correctly to these questions then you are fully prepared for the real exam.
McGraw-Hill Education CISSP Podcasts – The podcasts are covering all the domains and are of quite good (audio) quality. If you don’t have the time to listen everything then you could choose the listen only the review podcasts containing only the most important information.
 The goal of this ticket is to explain how to create an extension for the Burp Suite Professional taking as implementation example the “Reverse Tabnabbing” attack.
The goal of this ticket is to explain how to create an extension for the Burp Suite Professional taking as implementation example the “Reverse Tabnabbing” attack.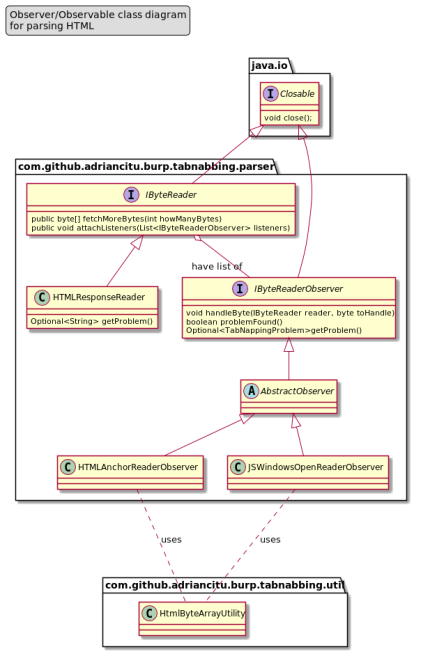





You must be logged in to post a comment.