This is a review of the The Tangled Web: A Guide to Securing Modern Web Applications book.
(My) Conclusion
This books makes a great job explaining how the “bricks” of the Internet (HTTP, HTML, WWW, Cookies, Script Languages) are working (or not) from the security point of view. Also a very systematic coverage of the browser (in)security is done even if some of the information it starts to be outdated. The book audience is for web developers that are interested in inner workings of the browsers in order to write more secure code.
Chapter 1 Security in the world of web applications
This goal of this chapter is to set the scene for the rest of book. The main ideas are around the fact that security is non-algorithmic problem and the best ways to tackle security problems are very empirical (learning from mistakes, develop tools to detect and correct problems, and plan to have everything compromised).
Another part of the chapter is dedicated to the history of the web because for the author is very important to understand the history behind the well known “bricks” of the Internet (HTTP, HTML, WWW) in order to understand why they are completely broken from the security point of view. For a long time the Internet standards evolutions were dominated by vendors or stakeholders who did not care much about the long-term prospects of technology; see the Wikipedia Browser Wars page for a few examples.
Part I Anatomy of the web (Chapters 2 to 8)
The first part of the book is about the buildings blocks of the web: the HTTP protocol, the HTML language, the CSS, the scripting languages (JavaScript, VBScript) and the external browser plug-ins (Flash, SilverLight). For each of these building blocks, the author presents how are implemented and how are working (or not) in different browsers, what are the standards that supposed to drive the development and how these standards are very often incomplete or oblivious of security requirements.
In this part of the book the author speaks only briefly about the security features, knowing that the second part if the book supposed to be focused on security.
Part II Browser security features (Chapter 9 to 15)
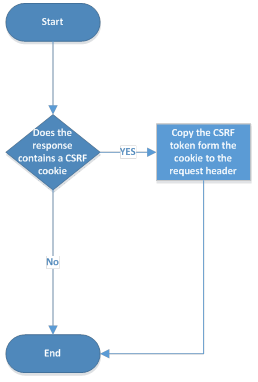
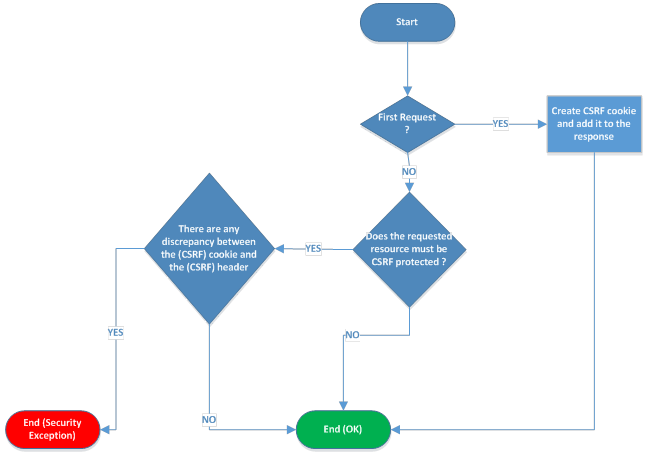
The first security feature presented is the SOP (Same Policy Origin), which is also the most important mechanism to protect against hostile applications. The SOP behaviour is presented for the DOM documents, for XMLHttpRequest, for WebStorage and how the security policies for cookies could also impact the SOP.
A less known topic that is treated is the SOP inheritance; how the SOP is applied to pseudo-urls like about:, javascript: and data:. The conclusion is that each browser are treating the SOP inheritance on different ways (which can be incompatible) and it is preferable to create new frames or windows by pointing them to a server-suplied blank page with a definite origin.
Another less known browser features (that can affect the security) are deeply explained; the way the browsers are recognizing the content of the response (a.k.a content sniffing), the navigation to sensitive URI schemes like “javascript:”, “vbscript:”, “file:”, “about:”, “res:” and the way the browsers are protecting itself against rogue scripts (in the case of the rogue scripts protection the author is pointing the inefficiently of the protections).
The last part is about different mechanisms that browsers are using in order to give special privileges to some specific web sites; the explained mechanisms are the form-based password managers, the hard-coded domain names and the Internet Explorer Zone model.
Part III Glimpse of things to come (Chapter 16 to 17)
This part is about the developments done by the industry to enhance the security of the browsers,
For the author there are two ways that the browser security could evolve; extend the existing frameworks/s or try to restrict the existing framework/s by creating new boundaries on the top of existing browser security model.
For the first alternative, the following solutions are presented: the W3C Cross-Origin Resource Sharing specification , the Microsoft response to CORS called XDomainRequest (which by the way was deprecated by Microsoft) and W3C Uniform Messaging Policy.
For the second alternative the following solutions are presented: W3C (former Mozilla) Content Security Policy , (WebKit) Sandboxed frames and Strict Transport Security.
The last part is about how the new planned APIs and features could have impact on the browser and applications security. Very briefly are explained the “Binary HTTP”, WebSocket (which was not yet a standard when the book was written), JavaScript offline applications, P2P networking.
Chapter 18 Common web vulnerabilities
The last chapter is a nomenclature of different known vulnerabilities grouped by the place where it can happen (server side, client side). For each item a brief definition is done and links are provided towards previous chapters where the item has been discussed.



You must be logged in to post a comment.