This is the review of the Secure by Design book.
(My) Conclusion
I would definitively add this book to the list of (software) security books that every software engineer should read (see “5 (software) security books that every (software) developer should read”) and I would put it on the first place. This book does not treat software security in a classic way but from software design point of view. The main idea of the book is that a good software design will drastically improve the application security posture.
For me this book could be seen as an extension of the Domain-Driven Design: Tackling Complexity in the Heart of Software book but applied to software security. The main audience of the book is any software engineer and security professionals that are working with the development teams to help them to have a better security posture.
1: Why Design Matters for Security
The fist chapter explains why when developing software centered on design, security will become a natural part of the development process instead of being perceived as a forced requirement.
The traditional approach to software security have e few shortcomings; the user have to explicitly think about security and it have to be knowledgeable in different security topics. On the other side driving security through design can have the following advantages:
- Software design is central to the interest and competence of most developers.
- By focusing on design, business and security concerns gain equal priority in the view of both business experts and developers.
- By choosing good design constructs, non-security experts are able to write secure code.
- By focusing on good domain design, many security bugs are solved implicitly.
2: Intermission: The anti-Hamlet
This chapter (which is based on a real case) presents an example of how a flaw in designing a model of an bookstore e-shop application negatively impacted the business.
The mistake done in the model was to represent the quantity of items from a shopping card as an integer, so the users of the application could add negative numbers of items so at the end the customers could receive money from the bookstore.
3: Core concepts of Domain-Driven Design
The chapter starts with the definition of the Domain Driven Design (DDD) and describing what are the qualities of a domain model to be effective:
- Be simple so you focus on the essentials.
- Be strict so it can be a foundation for writing code.
- Capture deep understanding to make the system truly useful and helpful.
- Be the best choice from a pragmatic viewpoint.
- Provide you with a language you can use when you talk about the system.
The main notions from DDD that can be beneficial in the context of a more robust model are:
Entities
Entities are objects representing a thread of continuity and identity, going through a lifecycle, though their attributes may change.
Entities are one type of model objects that have some distinct properties. What makes
an entity special is that:
- It has an identity that defines it and makes it distinguishable from others.
- It has an identity that’s consistent during its life cycle.
- It can contain other objects, such as other entities or value objects (see further for a value object definition).
- It’s responsible for the coordination of operations on the objects it owns.
Value Objects
Value objects are objects describing or computing some characteristics of a thing.The key characteristics of a value object are as follows:
- It has no identity that defines it, but rather it’s defined by its value.
- It’s immutable.
- It should form a conceptual whole.
- It can reference entities.
- It explicitly defines and enforces important constraints.
- It can be used as an attribute of entities and other value objects.
- It can be short-lived.
Aggregates
An aggregate is a conceptual boundary used to group parts of the model together. The purpose of this grouping is to treat the aggregate as a unit. The key characteristics of a aggregates are:
- Every aggregate has a boundary and a root.
- The root is a single, specific entity contained in the aggregate.
- The root is the only member of the aggregate that objects outside the boundary
can hold references to.
- Objects within the aggregate can hold references to other aggregates.
Bounding context
Multiple models are in play on a large project; it’s possible to have two or more models having the same concepts but with different semantics. In the case of different models, there is a need to define explicitly the scope of a particular model as a bounded part of a software system. A bounded context delimits the applicability of a particular model.
Data crossing a semantic boundary is of special interest from a security perspective because this is where the meaning of a concept could implicitly change.
4: Code constructs promoting security
Problems areas addressed and the proposed constructs:
| Problem |
Section |
| Security problems involving data integrity and availability |
Immutable objects |
| Security problems involving illegal input and state |
Design by Contract |
| Security problems involving input validation |
(Input) Validation |
Immutable objects
Immutable objects are safe to share between threads and open up high data availability which is an important aspect when protecting a system against denial of service attacks. Immutable object could protect against security problems involving availability of a system.
Mutable objects, on the other hand, are designed for change, which can lead to illegal updates and modifications. Immutable objects will enforce the integrity of the data of an application.
Design by Contract
Design By Contract (see Meyer, Bertrand: Applying “Design by Contract”) is an approach for designing software that uses preconditions and post-conditions to document (or programmatically assert) the change in state caused by a piece of a program. Thinking about design in terms of preconditions and contracts helps you clarify which part of a design takes on which responsibility.
Many security problems arise because one part of the system assumes another part takes responsibility for something when, in fact, that part assumes the opposite.
The authors are presenting some example of checking preconditions for method arguments and constructors. The goal is to fail if the contract is not met and the program is not using the classes in a way they were designed to be used. The program has lost control of what’s happening, and the safest thing to do is to stop as fast as possible.
(Input) Validation
In the case of input validation the authors are going through a framework that tries to separate the different kinds of (input) validation. The list presented also suggests a good order in which to do the different kinds of validation. Cheap operations like checking the length of data come early in the list, and more expensive operations that require calling the database come later. If one the steps is failing then the entire validation process must fail.
Different validation steps:
- Origin – Is the data from a legitimate sender?
- Origin checks can be done by checking the origin IP or requiring an access token
- Size – Is the size of the data in line with the context on which the data is used?
- Lexical content – Does it contain the right characters and encoding?
- When checking the lexical content of data, the important part is the content not the structure so, the data is scanned to see that it contains the expected characters and the expected encoding.
- Syntax – Is the format right?
- Semantics – Does the data make sense from the business point of view?
5: Domain primitives
Problems areas addressed:
| Problem |
Section |
Security issues caused by inexact, error-prone, and
ambiguous code |
Domain primitives |
| Security problems due to leakage of sensitive data |
Read-once objects |
Domain primitives
Domain primitives are similar to value objects in Domain-Driven Design. Key difference is and they must be enforced at the point of creation. Also the usage of language primitives or generic types (including null ) are forbidden to represent concepts in the domain model because it could caused inexact, error-prone, and ambiguous code.
At the creation of the domain primitives the different validation steps could be applied as explained into the previous chapter; see (Input) Validation section of chapter 4: Code constructs promoting security
A typical example of a domain primitive is a quantity (see the example from the chapter 2: Intermission: The anti-Hamlet) that should not be defined as a primitive type (a float or an int) but as a distinguish type that will contains all the necessary logic for creation of valid (from the domain point of view) instances of quantity type.
For example in the context of a book shop a quantity which is negative or a not an integer greater is not valid from the business domain point of view.
Read-once objects
A read-once object is an object designed to be read once (or a limited number of times). This object usually represents a value or concept in your domain that’s considered to be sensitive (for example, passport numbers, credit card numbers, or passwords). The main purpose of the read-once object is to facilitate detection of unintentional use of the data it encapsulates.
Here’s a list of the key aspects of a read-once object:
- Its main purpose is to facilitate detection of unintentional use.
- It represents a sensitive value or concept.
- It’s often a domain primitive.
- Its value can be read once, and once only.
- It prevents serialization of sensitive data.
- It prevents sub-classing and extension.
6: Ensuring integrity of state
This chapter it’s about the integrity of the DDD entities objects.Entities contains the state that represents the business rules so it is important that a newly created entity follow the business rules.
The first goal is to have entities already consisted at the creation time. This can be done forcing the object creation through a constructor with all mandatory attributes and optional attributes set via method calls. This works very well for simple business rules; for more complex business rules the usage of the Builder pattern is advised.
The second goal is to keep the entities consistency after the creations time during the usage of the entities by other software components. The main idea is to share only final attributes (that cannot be changed), not share mutable objects and use immutable domain primitives.
In the case of attributes containing collections, should not expose a collection but rather expose a useful property of the collection (for example to add an item into a collection, add a method that receive as parameter the item to be added). Collection can be protected by exposing an non modifiable version (see Collections.unmodifiableCollection)
7: Reducing complexity of state
This chapter is extending the discussion from the previous chapter and it presents how to handle DDD entities objects that can have multiple states. For example an entity representing an order can have a few valid states like “paid”, “shipped”, “lost” or “delivered”. Keeping the state of entities controlled becomes hard when entities become complex, especially when there are lots of states with complex transitions between them.
The authors are proposing 3 patterns to handle the entities state complexity:
- Entity state object
- The proposal is to have entity state be explicitly designed and implemented as a class of its own. With this approach, the state object is used as a delegated helper object for the entity. Every call to the entity is first checked with the state object. This approach makes it easier to grasp what states the entity can have.
- Entity Snapshot
- The pattern consist of generating immutable objects called snapshots from the an entity. The clients will use the snapshots for the read only operations. For changing the state of the underlying entity, the clients will have to use a domain service to which they’ll have to send updates.
- A drawback of this approach is that it violates some of the ideas of object orientation, especially the guideline to keep data and its accompanying behavior close together, preferably in the same class.
- From the security point of view this pattern it improves the integrity because because the snapshot is immutable so there’s no risk at all of the representation mutating to a foul state.
- Entity relay
- This pattern is to be used in the case when the entity have a big number of possible states with a complex graph of changing states. The basic idea of entity relay is to split the entity’s lifespan into phases, and let each entity represent its own phase. When a phase is over, the entity goes away, and another kind of entity takes over—like a relay race.
8: Leveraging your delivery pipeline for security
The chapter treats different test strategies that could be applied in order to have a better security posture.
For the unit tests, the authors propose to divide the tests into:
- normal testing – Verifies that the design accepts input that clearly passes the domain rules
- boundary testing – Verifies that only structurally correct input is accepted. Examples of boundary checks are length, size, and quantity,
- invalid input testing – Verifies that the design doesn’t break when invalid input is handled. Empty data structures, null, and strange characters are often considered invalid input.
- extreme input testing – Verifies that the design doesn’t break when extreme input is handled. For example, such input might include a string of 40 million characters.
Other topics covered are :
- testing of feature toggles that can cause security vulnerabilities. A good rule of thumb is to create a test for every existing toggle and should test all possible combinations using automated tests.
- testing of the availability of the application by simulating DOS attacks.
9: Handling failures securely
The chapter treats different topics around handling failures and program exceptions.
It’s a good practice to separate business exceptions and technical exceptions. For business exception the best practice is to create exception having a business meaning.
As a practice to avoid, shouldn’t intermix technical and business exceptions using the same type and never include business data in technical exceptions, regardless of whether it’s sensitive or not.
Another interesting idea is to not handle business failures as exceptions. A failure should be modeled as a possible result of a performed operation in the same way a success is. By designing failures as unexceptional outcomes, it’s possible to avoid the problems that come from using exceptions including ambiguity between domain and technical exceptions, and inadvertently leaking sensitive information.
Resilience and responsiveness are attributes of a system that are improving the system availability. To achieve this attributes the authors are presenting 2 patterns:
- circuit breaker pattern – Circuit Breaker allows graceful handling of failed remote services. It’s especially useful when all parts of an application are highly decoupled from each other, and failure of one component doesn’t mean the other parts will stop working.
- bulkhead pattern – The Bulkhead pattern is a type of application design that is tolerant of failure. In a bulkhead architecture, elements of an application are isolated into pools so that if one fails, the others will continue to function.
10: Benefits of cloud thinking
This chapter is treating design concepts to be used for achieving a better security posture in the context of cloud deployments.
The most important concept it’s the “The three R’s of enterprise security“. The methodology of three Rs is: Rotate, Repave and Repair and it offers a simple approach towards greater security of cloud deployments.
The basic idea is to be proactive than be reactive as seen in traditional enterprise security. Speed is of essence. The longer a deployment stays in a given configuration, the greater is the opportunity for threats to exploit any vulnerabilities.
- Rotate: Rotate secrets every few minutes or hours. Rotating secrets doesn’t improve the security of the secrets themselves, but it’s an
effective way of reducing the time during which a leaked secret can be misused.
- Repave: Repave servers and applications every few hours.Recreating all servers and containers and the applications running on them from a known good state every few hours is an effective way of making it hard for malicious software to spread through the system.
- Repair: Repair vulnerable software as soon as possible after a patch is available. This goes for both operating systems and applications third party dependencies. The reason for repairing as often as you can is that for every new version of the software, something will have changed so an attacker constantly needs to find new ways to break it.
11: Intermission: An insurance policy for free
This chapter is very similar with the chapter 2, Intermission: The anti-Hamlet. It presents a real case (of an insurance company) that migrated a monolithic application to a micro-service application.
Due to this migration, the application was split into 2 different micro-services handled by 2 different teams. Having 2 independent teams handling different parts of the application and some functional changes in one of the micro-services will have as impact that the notion of Payment will have different meanings for the 2 micro-services. This miss-match will generate some subtle bugs even if none of the 2 systems were not broken.
12: Guidance in legacy code
This chapter is a kind of review of all the practices described in previous chapters that are applicable to legacy code.
It treats about the usage of domain primitives (see chapter 5 Domain primitives) to replace ambiguous parameters in APIs which are a common source of security bugs, the usage of read-once objects (see chapter 5 Domain primitives) which limits the number of times a sensitive values can be accessed allowing it to detect unintentional access, the usage of security tests that are testing look for invalid and extreme inputs (see chapter 8 Leveraging your delivery pipeline for security)
13: Guidance in micro-services
This chapter is very similar with the previous one but the context is the new approach of writing applications using micro-services.
Implementing security for a micro-service architecture is more difficult that in a case of a monolithic architecture because of the loose coupling of micro-services.
Splitting a monolithic application to different micro-services is rather a difficult task but a good design principle is to think of each service as a bounded context (see chapter 3 Core concepts of Domain-Driven Design for definition of bounded context).
Analyzing confidentiality, integrity, availability, and traceability across all services and data sensitivity is more difficult than in a case of classical architecture. The only way to treat this security topics in a complete way is to have a broader view of the entire applications and not only on a subset of the micro-services.
14: A final world: Don’t forget about security!
The entire book was talking about how to not think about security, but still getting a good security posture anyway. This chapter speaks about how important is to think and learn about the security anyway and it gives advises that could be found in more “classical” security books:
- Should use code security reviews as a recurring part of secure development lifecycle (SDLC)
- It is important to invest in tooling that provides quick access to information about security vulnerabilities across the technological entire stack.
- Penetration tests should be done recurrently and the feedback from this tests should be used as an opportunity to improve the application design.
- Having a team and processes to handle security incidents and the security incident mechanism should focus on learning to become more resistant to attacks.
.

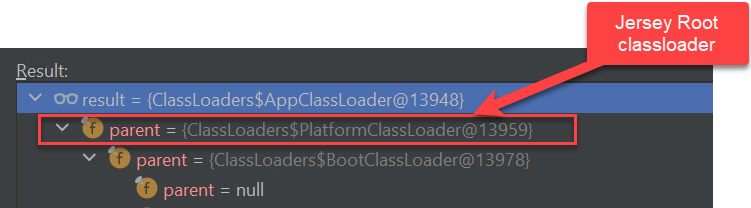
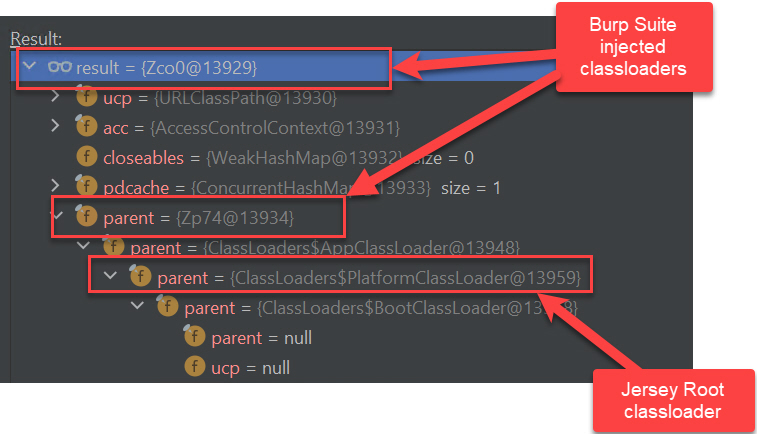
 The goal of this ticket is to present the different technological components of WebAssembly in comparison with the Java technological stack.
The goal of this ticket is to present the different technological components of WebAssembly in comparison with the Java technological stack.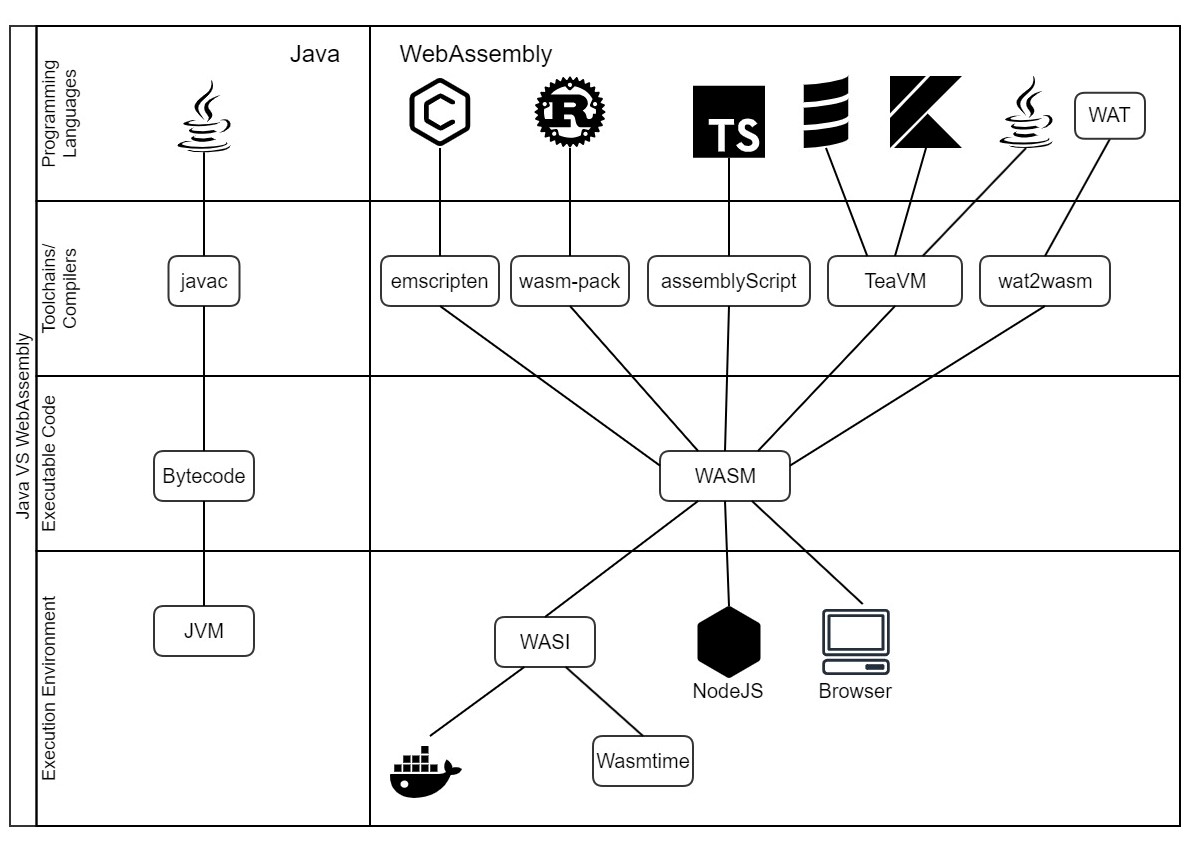





You must be logged in to post a comment.