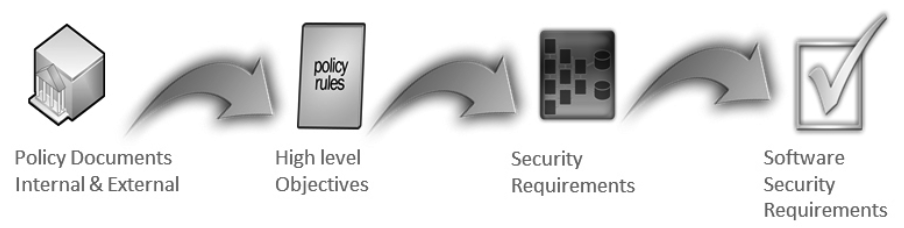
The policy decomposition is the process of breaking down high level policy requirements into security objectives and eventually protection needs and secure software requirements.
Policies involving protecting data could be decomposed in confidentiality requirements.
Policies involving protecting data from unauthorized alteration can be decomposed in integrity requirement.
Policies associated with determining access can be decomposed into availability requirements.
Data Classification and Categorization
Data classification is a risk management tool, with the objective to reduce the costs associated with protecting data.
Types of data :
structured – the most common form of structured data is that stored in the DB; other forms of structured data, XML, JSON test files, log files.
unstructured – the rest of data that is not structured; data that is not easily parsed and parsed.
Data states :
data at rest.
data in transit – data being transmitted from one location to another.
date being created.
data being changed or deleted.
Data labeling
Data classification/labelling is the conscious effort to assign labels (a level of sensitivity) to information (data) assets, based on potential impact to confidentiality, integrity and availability (CIA).
The main objective of data classification is to lower the cost of data protection
and maximize the return on investment when data is protected.
Data ownership:
Data Owner – (also called information owner or business owner) is a management employee responsible for ensuring that specific data is protected. Data owners determine data sensitivity labels and the frequency of data backup. The Data Owner is responsible for ensuring that data is protected. A user who “owns” data has read/write access to objects.
Data Custodian – provides hands-on protection of assets such as data. They perform data backups and restoration, patch systems, configure antivirus software, etc. The Custodians follow detailed orders; they do not make critical decisions on how data is protected.
Requirements
Role and user definitions
objects – items that a user (subject) interacts with in the operation of a system.
subjects – an active entity on a data system. Most examples of subjects involve people accessing data files. However, running computer programs are subjects as well. A Dynamic Link Library file or a Perl script that updates database files with new information is also a subject.
actions – permitted events that a subject can perform on an associated object.
The subjects represent who, the objects represents what and actions represent the how of the subject-object-activity relationship. A subject-object matrix is used to identify allowable actions between subjects and objects based on use cases.
Once use cases are enumerated with subjects (roles) and the objects (components) are defined, a subject-object matrix can be developed. A subject-object matrix is a two-dimensional representation of roles and components.
Functional requirements
Functional requirements describe how the software is expected to function. They begin as business requirements and are translated into functional requirements.
Uses cases are a technique for determining functional requirements in developer-friendly terms. Use case modeling is meant to model only the most significant system behavior or the most complex ones and not all of it and so should not be considered as a substitute for requirements specification documentation.
From use cases, misuse cases can be developed. Misuse cases, also known as abuse cases help identify security requirements by modeling negative scenarios.
Time of Check/Time of Use (TOCTOU) attacks are also called race conditions: an attacker attempts to alter a condition after it has been checked by the operating system, but before it is used. The term race condition comes from the idea of two events or signals that are racing to influence an activity.
Some of the common templates that can be used for use and misuse case
The RTM is a grid that assists the development team in tracking and managing requirements and implementation details.
A generic RTM is a table of information that lists the business requirements in the left most column, the functional requirements that address the business requirements are in the next column. Next to the functional requirements are the testing requirements. From a software assurance perspective, a generic RTM can be modified to include security requirements as well. This is a template example of RTM diagram: Requirements Traceability Matrix Template
Chapter 3: Introduction to Software Security Touchpoints
This is an introductory chapter for the second part of the book. A very brief description is made for every security touch point.
Each one of the touchpoints are applied on a specific artifact and each touchpoints represents either a destructive or constructive activity. Based on the author experience, the ideal order based on effectiveness in which the touch points should be implemented is the following one:
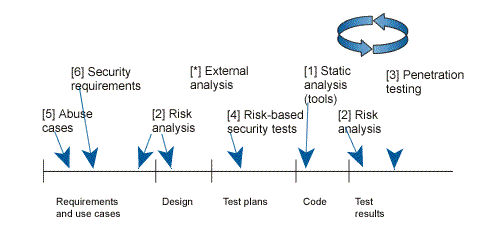
Another idea to mention that is worth mentioning is that the author propose to add the securty aspects as soon as possible in the software development cycle;moving left as much as possible (see the next figure that pictures the applicability of the touchpoints in the development cycle); for example it’s much better to integrate security in the requirements or architecture and design (using the risk analysis and abuse cases touchpoints) rather than waiting for the penetration testing to find the problems.
Security touchpoints
Chapter 4: Code review with a tool
For the author the code review is essential in finding security problems early in the process. The tools (the static analysis tools) can help the user to make a better job, but the user should also try to understand the output from the tool; it’s very important to not just expect that the tool will find all the security problems with no further analysis.
In the chapter a few tools (commercial or not) are named, like CQual, xg++, BOON, RATS, Fortify (which have his own paragraph) but the most important part is the list of key characteristics that a good analysis tool should have and some of the characteristics to avoid.
The key characteristics of a static analysis tool:
be designed for security
support multi tiers architecture
be extensible
be useful for security analysts and developers
support existing development processes
The key characteristics of a static analysis tool to avoid:
too many false positives
spotty integration with the IDE
single-minded support for C language
Chapter 5: Architectural Risk Analysis
Around 50% of the security problems are the result of design flows, so performing an architecture risk analysis at design level is an important part of a solid software security program.
In the beginning of the chapter the author present very briefly some existing security risk analysis methodologies: STRIDE (Microsoft), OCTAVE (Operational Critical Threat, Asset and Vulnerability Evaluation), COBIT (Control Objectives for Information and Related Technologies).
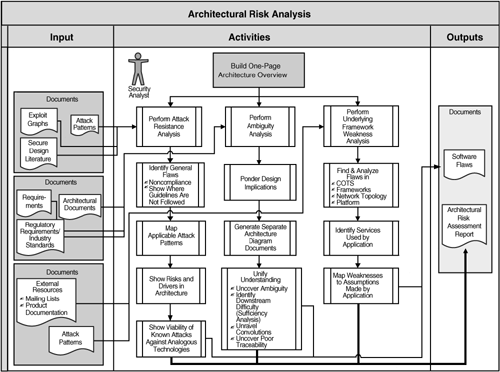
In the last part of the chapter the author present the Cigital way of making architectural risk analysis. The process has 3 steps:
attack resistance analysis – have as goal to define how the system should behave against known attacks.
ambiguity analysis – have as goal to discover new types of attacks or risks, so it relies heavily on the experience of the persons performing the analysis.
weakness analysis – have as goal to understand end asses the impact of external software dependencies.
Process diagram for architectural risk analysis
Chapter 6: Software Penetration Testing
The chapter starts by presenting how the penetration testing is done today. For the author, the penetration tests are misused and are used as a “feel-good exercise in pretend security”. The main problem is that the penetration tests results cannot guarantee that the system is secured after all the found vulnerabilities had been fixed and the findings are treated as a final list of issues to be fixed.
So, for the author the penetration tests are best suited to probing (live like) configuration problems and other environmental factors that deeply impact software security. Another idea is to use the architectural risk analysis as a driver for the penetration tests (the risk analysis could point to more weak part(s) of the system, or can give some attack angles). Another idea, is to treat the findings as a representative sample of faults in the system and all the findings should be incorporated back into the development cycle.
Chapter 7: Risk-Based Security Testing
Security testing should start as the feature or component/unit level and (as the penetration testing) should use the items from the architectural risk analysis to identify risks. Also the security testing should continue at system level and should be directed at properties of the integrated software system. Basically all the tests types that exist today (unit tests, integration tests) should also have a security component and a security mindset applied.
The security testing should involve two approaches:
functional security testing: testing security mechanism to ensure that their functionality is properly implemented (kind of white hat philosophy).
adversarial security testing: tests that are simulating the attacker’s approach (kind of black hat philosophy).
For the author the penetration tests represents a outside->in type of approach, the security testing represents an inside->out approach focusing on the software products “guts”.
Chapter 8: Abuse Case Development
The abuse case development is done in the requirements phase and it is intimately linked to the requirements and use cases. The basic idea is that as we define requirements that suppose to express how the system should behave under a correct usage, we should also define how the system should behave if it’s abused.
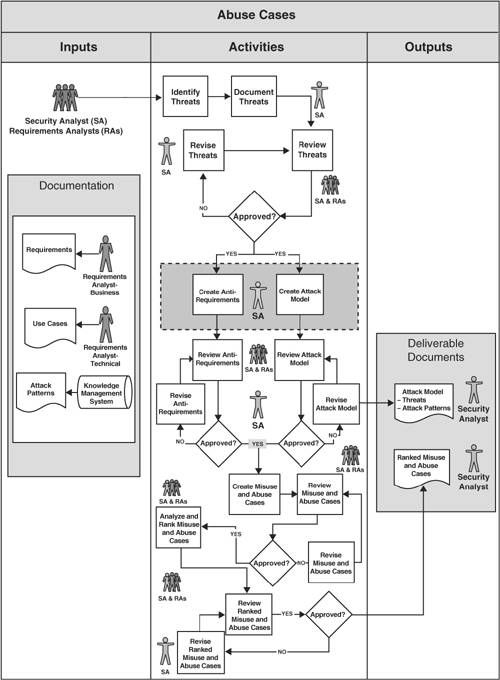
This is the process that is proposed by the author to build abuse cases.
Diagram for building abuse cases
The abuse cases are creating using two sources, the anti-requirements (things that you don’t want your software to do) and attack models, which are known attacks or attack types that can apply to your system. Once they are done, the abuse cases can be used as entry point for security testing and especially for the architectural risk analysis.
The main idea is that the security operations peoples and software developers should work together and each category can (and should) learn from the other (category).
The security operation peoples have the security mindset and can use this mindset and their experience in some of the touchpoints presented previously; mainly abuse cased, security testing, architectural risk analysis and penetration testing.
This chapter lands out the landscape for the entire book; the author presents his view on the today challenges in having secure holes free software.
In the today world, the software is everywhere, from microwaves oven to nuclear power-stations, so the “old view” of seeing the software applications as “black boxes” than can be protected using firewalls and IDS/IPS it’s not valid anymore.
And just to make the problem even harder, the computing systems and the software applications are more and more interconnected must be extensible and have more and more complex features.
The author propose a taxonomy of the security problems that can be affected the software applications:
defect: a defect is a problem that may lie dormant in software only to surface in a fielded system with major consequences.
bug: an implementation-level software problem; only fairy simple implementations errors. A large panel of tools are capable to detect a range of implementation bugs.
flaw: a problem at a deeper level; a flow is something that can be present at the code level but it can be also present or absent at the design level. What is very important to remark is that the automated technologies to detect design-level flows do not yet exist, through manual risk-analysis can identity flows.
risk: flaws and bugs lead to risk. Risk capture the chance that a flaw or a bug will impact the purpose of a software.
In order to solve the problem of the software security, the author propose a cultural shift based on three pillars: applied risk management, software security touchpoints and knowledge.
Pillar 1 Applied Risk Management
For the author under the risk management names there 2 different parts; the application of risk analysis at the architectural level (also known as threat modeling or security design analysis or architectural risk analysis) and tracking and mitigating risks as a full life-cycle activity (the author call this approach, the risk management framework – RMF).
Pillar 2 Software security Touchpoints.
Touchpoint it’s just a fancy word for “best practices”. Today there are best practices for design and coding of software system and as the security became a property of a software system, then best practices should also be used to tackle the security problems.Here are the (seven) touch points and where exactly are applied in the development process.
Security Touchpoints
The idea is to introduce as deeply as possible the touch points in the development process. The part 2 of the book is dedicated to the touchpoints.
Pillar 3 Knowledge
For the author the knowledge management and training should play a central role in encapsulation and sharing the security knowledge.The software security knowledge can be organized into seven knowledge catalogs:
principles
guideline
rules
vulnerabilities
exploits
attack patterns
historical risks
How to build the security knowledge is treated in the part 3 of the book.
Chapter 2: A risk management framework
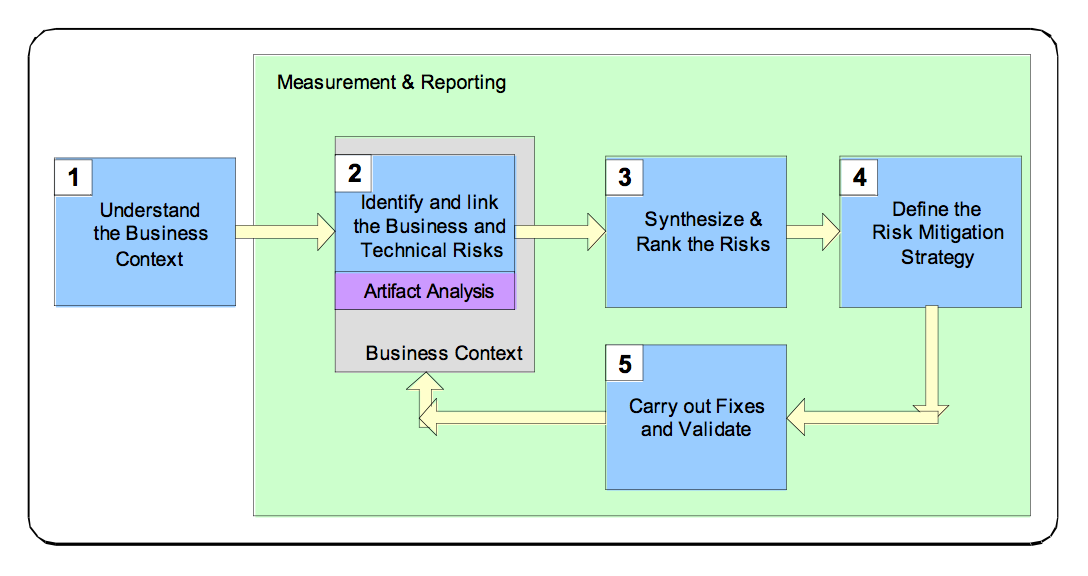
This chapter presents in more details a framework to mitigate the risks as a full lifecycle activity; the author calls this framework the RMF (risk Management Framework).
The purpose of the RMF is to allow a consistent and repeatable expert-driven approach to risk management but the main goal is to find, rank, track and understand the software security risks and how these security risks can affect the critical business decisions.
Risk Management Analysis steps
The RMF consists of five steps:
understand the business context The goal of this step is describe the business goals in order to understand the types of software risks to care about.
identify the business and technical risks. Business risk identification helps to define and steer the use of particular technological methods for measuring and mitigating software risk.The technical risks should be identified and mapped (through business risk) to business goals.
synthesize and rank the risks. The ranking of the risks should take in account which business goals are the most important, which business goals are immediately threatened and how the technical risks will impact the business.
define a risk mitigation strategy. Once the risks have been identified, the mitigation strategy should take into account cost, implementation time, likelihood of success and the impact
carry out required fixes and validate that they are correct. This step represents the execution of the risk mitigation strategy; some metrics should be defined to measure the progress against risks, open risks remaining.
Even if the framework steps are presented sequentially, in practice the steps can overlap and can occur in parallel with standards software development activities. Actually the RMF can be applied at several different level; project level, software lifecycle phase level, requirement analysis, use case analysis level.


You must be logged in to post a comment.