This book is about a “new” programming paradigm called Data Oriented Programming (a.k.a. DOP). I put the word new between quotes because the underlying concepts and principles have been around for much longer in various forms and under different names.
DOP is a programming paradigm aimed at simplifying the design and implementation of software systems, where information is at the center in systems such as frontend or backend web applications and web services. Instead of designing information systems around software constructs that combine code and data (e.g., objects instantiated from classes), DOP encourages the separation of code from data.
The author don’t really explains the history of the DOP but it looks like the term was coined for the first time in the gaming industry. One significant influence on the development of data-oriented programming principles was the publication of “Game Engine Architecture” by Jason Gregory in 2009.
The term “data-oriented programming” (DOP) was popularized by Noel Llopis, a software engineer, in his blog post titled “Data-Oriented Design (Or Why You Might Be Shooting Yourself in The Foot With OOP)” published in 2010. In this blog post, Llopis introduced the concept of data-oriented design as an alternative approach to Object-Oriented Programming (OOP) for certain types of performance-critical applications, especially in the context of video games and real-time simulations.
Part 1 – Flexibility
To introduce DOP (Data-Oriented Programming), the initial section of the book commences with an illustration of a project implemented solely in OOP (Object-Oriented Programming). The aim is to demonstrate that a system developed using OOP tends to become intricate and challenging to comprehend due to the mixing of code and data within objects. Additionally, such systems pose greater difficulties when adapting to changing system requirements.
The first principle of DOPadvocates a distinct segregation between code (behavior) and data. Data is organized into data entities, while the code is housed within code modules. These code modules consist of stateless functions; this functions receive data they manipulate as an explicit argument.
The second principle of DOPis to represent application data with generic data structures. The most common generic data structures are maps (aka dictionaries) and arrays (or lists). But other generic data structures (e.g., sets, trees, and queues) can be used as well.
The third principle of DOP is that the date is immutable. Within the DOP framework, data modifications are achieved by generating new versions of the data. Although the reference to a variable can be altered to point to a fresh version of the data, the actual value of the data remains unchanged.
This concept of structural sharing enables the efficient creation of new data versions in terms of memory and computation. Instead of duplicating common data between the two versions, they are shared, leading to better memory utilization.
Part 2 – Scalability
The second part of the book delves deeper into the practical application of DOP, addressing its primary limitations from a beginner’s perspective and proposing solutions for handling these challenges:
DOP is primarily concerned with generic data structures, making it difficult to determine the specific types of data being used. In contrast, OOP allows for clear identification of data types associated with each data element.
Implementing immutable data structures with structural sharing can result in performance issues, especially for large data structures.
DOP’s reliance on in-memory data poses challenges when interacting with relational databases or other external services.
To tackle the first issue, the author introduces the fourth (and final) DOP principle: “Separate data schema from data representation.” This involves representing the data schema using JSON schemas. Various libraries are available for implementing JSON schema validators, see JSON Schema Validators.
To tackle the second concern, the author introduces the “persistent data structures”. Persistent data structures refer to data structures that allow for efficient modification and querying while preserving the previous versions of the data structure. These data structures are designed to support operations that create new versions of the structure rather than modifying the existing structure in-place.
Some examples presented in the first part of the book are re-implemented using persistent data structures in JavaScript using theImmutable.jsand in Java using Paguro.
To address Database and WebServices operations, same of the DOP principles are used. For instance, regardless of whether the data originates from a relational or non-relational database, it is depicted using generic data structures like maps or lists. These generic data structures can then be manipulated using generic functions. These functions include operations such as generating a list composed of the values from specific data fields, producing a map variant by excluding a particular data field, or grouping maps into a list based on the values of a specific data field.
Part 3 – Maintainability
The final section of the book delves into more advanced subjects, such as data validation using JSON Schema regex patterns, creating data model diagrams from JSON Schema (utilizing tools like JSON Schema Viewer or Malli), and generating unit tests based on schemas using JSON Schema Faker.
Additionally, certain topics, such as implementing polymorphism through multimethods , while not directly related to DOP, are nonetheless highly intriguing and educational.
This book is a niche subject book, to be more precise it’s about a niche tool (antivirus) used in a niche domain (endpoint security) of cybersecurity.
As his name implies, it describes how antivirus products are working and different technique to evade this antivirus products.
The book it’is not very technical (compared with a programming book) but it implies some knowledge of Windows OS architecture, Assembler and Python.
If you are new to this subject (like myself) it’s very good introduction that will give you a rather technical glimpse of the mouse and cat “game” played between the antivirus developers and malware creators.
If you are already working in the endpoint security domain you (probably) already know all the techniques presented in the book.
1.Introduction to the Security Landscape
This chapter is exploring the following topics:
definition of different malware types:
Virus: A malware type that replicates itself in the system.
Worm: A type of malware whose purpose is to spread throughout a network and infect computers connected to that network.
Rootkit: A type of malware that is found in lower levels of the operating system that tend to be highly privileged.
Downloader: A type of malware whose function is to download and run from the internet some other malicious files.
Ransomware: A type of malware whose purpose is to encrypt computer files and demand financial ransom from the user before they can access their files.
Botnet: Botnet malware causes the user to be a small part of a large network of infected computers.
Backdoor: A type of malware whose purpose is to leave open a “back door”, providing the attacker with ongoing access to the user’s computer.
PUP: An acronym that stands for potentially unwanted program, a name that includes malware whose purpose is to present undesirable content to the user, for instance, ads.
Dropper: A type of malware whose purpose is to “drop” a component of itself into the hard drive.
Scareware: A type of malware that presents false data about the computer it is installed on, so as to frighten the user into performing actions that could be malicious, such as installing fake antivirus software or even paying money for it.
Trojan: A type of malware that performs as if it were a legitimate, innocent application within the operating system.
Spyware: A type of malware whose purpose is to spy on the user and steal their information to sell it for financial gain.
definition of different protection system types:
EDR (Endpoint Detection and Response): The purpose of EDR systems is to protect the business user from malware attacks through real-time response to any type of event defined as malicious.
Firewall: A system for monitoring, blocking, and identification of network-based threats, based on a pre-defined policy.
IDS/IPS (Intrusion Detection and Protection System): IDS and IPS provide network-level security, based on generic signatures, which inspects network packets and searches for malicious patterns or malicious flow.
DLP (Data Loss Prevention): DLP’s sole purpose is to stop and report on sensitive data exfiltrated from the organization, whether on portable media (thumb drive/disk on key), email, uploading to a file server, or more.
the basics of an antivirus product. Most of the antivirus products have different types of engines:
static engine: Conducts comparisons of existing files within the operating system against a database of signatures, and in this way can identify malware.
dynamic engine: Is checking the files at runtime using API monitoring (the goal of API monitoring is to intercept API calls in the operating system and to detect the malicious ones) and sand-boxing (A sandbox is a virtual environment that is separated from the memory of the physical host computer. This allows the detection and analysis of malicious software by executing it within a virtual environment)
heuristic engine: This type of engine determines a score for each file by conducting a statistical analysis that combines the static and dynamic engine methodologies.
unpacker engine: Unpacking is the process of restoring the original malware code; the malicious code was “packed” in order to hide a malicious patterns and thus thwart signature-based detection. The unpacker engine is able to detect if a file contains a (known) unpacker code.
2.Before Research Begins
In order to evade the antivirus products you must have a good understanding about how the different antivirus program components are working. The authors are using different tools (on Windows OS only) that usually are used for malware analysis to discover the working mechanics of the AVG Antivirus.
The authors are using the following tools :
Process Explorer is a tool that will will provide us with a lot of relevant information about the processes that are running in the operating system like the file name of the processes, the percentage of the CPU resources for the processes, the amount of memory and RAM allocated to the processes. Using the Process Explorer it is possible for example to find the hook that are used by the antivirus software to conduct monitoring on every process that exists within the operating system. This hook is usually a DLL file that is injected into every process running within the operating system
Process Monitor is a tool that can be used to observe the behavior of each process in the operating system from the moment when are started until the moment are closed. Using the Process Monitor is possible for example to find the processes used by the antivirus software for specific tasks like scanning a specific file.
Autoruns is a tool that shows what programs are configured to run during system bootup or login, and when you start various built-in Windows applications. With Autoruns is possible to use filters to find for example all the antivirus software files that are loaded at the startup of the operating system.
Regshot is an open source tool that lets you take a snapshot of your registry, then compare two registry shots, before and after installing a program. In this case it is used to find all the registry changes that took place after installing the antivirus software
3.Antivirus Research Approaches
The authors are proposing two methods to bypass the antivirus software:
Find and exploit a vulnerability in the antivirus software
Find and use a detection bypass method
This chapter gives a few details about the first method; basically it presents a few vulnerabilities on different antivirus software packages that had impact on the way the antivirus was functioning:
Insufficient permissions on the static signature file. The file containing static signature had insufficient permissions meaning that any low-privileged user could modify the content of the file.
Unquoted service path. When a service is created within the Windows operating system and the executable path contains spaces and the path is not enclosed within quotation marks, the service will be susceptible to an Unquoted Service Path vulnerability. To exploit this vulnerability, an executable file must be created in a particular location in the service’s executable path, and instead of starting up the antivirus service, the service we created previously will load first and cause the antivirus to not load during operating system startup
DLL hijaking. When software wants to load a particular DLL, it uses the LoadLibraryW() Windows API call. It passes as a parameter to this function the name of the DLL it wishes to load. It is not recommended to use the LoadLibrary() function, due to the fact that it is possible to replace the original DLL with another one that has the same name, and in that way to cause the program to run our DLL instead of the originally intended DLL.
If you are interested of other types of vulnerabilities linked to the antivirus products you can look into the CVE MITRE database using the keyword antivirus.
4.Bypassing the Dynamic Engine
As explained in the first chapter the dynamic engine is checking the runtime behavior of files using API monitoring and sand-boxing. The authors are presenting two types of techniques for bypassing the dynamic engine:
Bypass using process Injection
Process injection goal is to inject a piece of code into the process memory address space of another process, give this memory address space execution permissions, and then execute the injected code. The general steps of a process injection are:
Identify a target process.
Receive a handle for the targeted process to access its process address space.
Allocate a virtual memory address space where the code will be injected and executed, and assign an execution flag if needed.
Perform code injection into the allocated memory address space of the targeted process.
Execute the injected code.
The authors are presenting three process injections techniques; there are a lot more techniques, for a non-exhaustive list you can check MITRE Pricess Injection Techniques :
DLL InjectionDLL injection is commonly performed by writing the path to a DLL in the virtual address space of the target process before loading the DLL by invoking a new thread. The write can be performed with native Windows API calls such as VirtualAllocEx and WriteProcessMemory, then invoked with CreateRemoteThread (which calls the LoadLibrary API responsible for loading the DLL).
Process hollowing Process hollowing is commonly performed by creating a process in a suspended state then unmapping/hollowing its memory, which can then be replaced with malicious code.
Process doppelganging This technique is using the Windows Transactional NTFS (TxF) API. TxF was introduced in Vista as a method to perform safe file operations.To ensure data integrity, TxF enables only one transacted handle to write to a file at a given time. Until the write handle transaction is terminated, all other handles are isolated from the writer and may only read the committed version of the file that existed at the time the handle was opened. Adversaries may abuse TxF for replacing the memory of a legitimate process, enabling the veiled execution of malicious code.
Bypass using timing-based techniques
Timing based techniques are based on the fact that antivirus vendors prefer to scan about 100,000 files in 24 minutes, with a detection rate of about 70%, over scanning the same number of files in 24 hours, with a detection rate of around 95%.
The first technique will utilize Windows API calls that cause the delay of the malware functionality, so the dynamic engine will not be able to spot the malware because it is not executed in a timely manner. A basic technique to implement this behavior is by using the sleep() function combined with the GetTickCount() function.
The usage of the sleep() function only can be detected by the antivirus static engine and then antivirus emulator (used by dynamic engine) will simulate the pass of the sleep time thus bypassing the malware defense mechanism. The usage of GetTickCount() (which returns the amount of time the operating system has been up and running) will counter this (time forward) emulation because the malware will be able to detect it.
The second technique is named by the authors the memory bombing and take advantage of the limited time that antivirus software has to dedicate to each individual file during scanning.
The pseudo-code for this technique looks like:
int main(){ char *memory_bombing = NULL; //Initialize the memory_bombing variable with a bunch of //zeroes. //At this point, the antivirus is struggling to scan the //file and forfeits memory_bombing = (char *) calloc(200000000, sizeof(char));
if(memory_bombing != NULL) { //free the memory allocated to memory_bombing free(memory_bombing); payload(); } return 0; }
The logic behind this type of bypass technique relies on the dynamic antivirus engine scanning for malicious code in newly spawned processes by allocating virtual memory so that the executed process can be scanned for malicious code in a sandboxed environment. The allocated memory is limited because antivirus engines do not want to impact the user experience so if the antivirus engine have to allocate a large amount of memory the antivirus engines will not scan the file.
5.Bypassing the Static Engine
The static engine is using file signatures to spot malicious files so, a lot of antiv-viruses are embedding the YARA tool; the chapter contains also a small introduction to YARA templates.
There are three ways to by pass the static engine:
Code Obfuscationis the process of making applications difficult or impossible to de-compile or disassemble, and make the application code more difficult to parse. The code obfuscation could defeat the ARA templates which are looking for specific strings into the files.
Encryption In this case the malicious functionality of the malware will be encrypted and appear as a harmless piece of code , meaning the antivirus software will treat it as such and will allow the malware to successfully run on the system. But before malware starts to execute its malicious functionality, it needs to decrypt its code within runtime memory. Only after the malware decrypts itself will the code be ready to begin its malicious actions. There are different encryption techniques used by the malwares:
Oligomorphic code includes several decryptors that malware can use. Each time it runs on the system, it randomly chooses a different decryptor to decrypt itself.
Polymorphic code mostly uses a polymorphic engine that usually has two roles. The first role is choosing which decryptor to use, and the second role is loading the relevant source code so that the encrypted code will match the selected decryptor.
Metamorphic code is code whose goal is to change the content of malware each time it runs, thus causing itself to mutate.
Packing A packer is a tool used to mask a malicious file. In general, packers work by taking an EXE file and obfuscating and compressing the code section (“.text” section) using a predefined algorithm. Following this, packers add a region in the file referred to as a stub, whose purpose is to unpack the software or malware in the operating system’s runtime memory and transfer the execution to the original entry point (OEP). The OEP is the entry point that was originally defined as the start of program execution before packing took place.The authors are presenting how the UPX and AsPAck packers are packaging a file and how unpacker will have to work in order to detect the content of the original file.
6.Other Antivirus Bypass Techniques
This chapter presents other bypass techniques:
Binary patching: It consists in opening/executing a binary through a debugger (the x32dbg/x64dbg in the book example), changing (on the fly) some code and then re-generating a new binary using the “Patch File” functionality of the debugger. This technique would defeat the static engine.
Timestomping; It consists in changing some metadata of a binary file like the created date. This relies on the fact that the creation date could be used for computing static signatures of different files so changing the creation date could defeat a static engine.
Junk code. Technique very similar to the Code Obfuscation technique presented in the chapter 5 Bypassing the static engine. The Junk code technique could also add empty functions, or loading non-existing files that could confuse the dynamic engine.
PowerShell. It consists in executing a payload directly from powershell; The powershell binary being a trusted file then the dynamic engine might be bypassed.
Single malicious functionality If the static and the dynamic engine are not able to decide if a file is malicious then the heuristic engine will try to compute a score for the scanned file. The heuristic engine have a detection threshold under which a scanned file will not be marked as malicious even if it contains some potentially malicious components. The goal for the malware developer/s is to find the maximum number of malicious actions that will be under the detection threshold of the heuristic engine.
7.Antivirus Bypass Techniques in Red Team Operations
This chapter is for me rather badly named; it starts by explaining what are the responsibilities and the goals of a red team and how it use the techniques presented into this book in the context of pen tests.
But, the main part if the chapter presents how a malware can check what antivirus products are installed on the endpoints that it wants to attack in order to apply the right bypass techniques, action that the authors are calling the fingerprinting of the antivirus software.
Antivirus fingerprinting can be done based on identifiable constants, such as the following: Service names (for example, WinDefend is for example the service name for Microsoft Defender), Process names (or example, AVGSvc.exe is the process name of the AVG antivirus), Domain names, Registry keys or Filesystem artifacts.
The authors are recommending the following GitHub repository ethereal-vx/Antivirus-Artifacts to find more details about Antivirus fingerprinting
8.Best Practices and Recommendations
The last chapter of the book can be split in 2 parts. The first part presents some controls that the antivirus providers could implement in order to mitigate some (not all of them) of the bypass techniques presented in previous chapters.
To mitigate the DLL hijacking vulnerability (a DLL is loaded using his name; see chapter 3 for more explanations) a proper mechanism to validate the loaded DLL module should be implemented. This validation should use not only the DLL name but also by a certificate and a signature.
To mitigate the Unquoted service path vulnerability (an executable path contains spaces and the path is not enclosed within quotation marks; see chapter 3 for more explanation) the solution is simply to wrap quotation marks around the executable path of the service.
For improving the antivirus detection the authors are proposing to use “dynamic” YARA. The goal of the “dynamic” YARA is to scan for potentially malicious strings and code at the memory level, on a dumped memory snapshot. Normally YARA is used by the static engine for file signature but in the case of “dynamic” YARA the template engine is used to look at the memory where the malware has been already de-obfuscated, unpacked, and decrypted.
Another best practice consists in the usage of Antimalware Scan Interface (AMSI) by the application developers.Windows Antimalware Scan Interface (AMSI) is an API that allows custom applications and services to integrate with any antimalware product that’s present on a machine.
The second part of the chapter contains some secure coding recommendations which can be applicable in SDLC of any type of software: Do not use old code, Input validation (of the AntiVirus UI), Read and fix the compiler warnings, Automated code testing, Use integrity validation for the static signature files download.
I would definitively add this book to the list of (software) security books that every software engineer should read (see “5 (software) security books that every (software) developer should read”) and I would put it on the first place. This book does not treat software security in a classic way but from software design point of view. The main idea of the book is that a good software design will drastically improve the application security posture.
For me this book could be seen as an extension of the Domain-Driven Design: Tackling Complexity in the Heart of Software book but applied to software security. The main audience of the book is any software engineer and security professionals that are working with the development teams to help them to have a better security posture.
1: Why Design Matters for Security
The fist chapter explains why when developing software centered on design, security will become a natural part of the development process instead of being perceived as a forced requirement.
The traditional approach to software security have e few shortcomings; the user have to explicitly think about security and it have to be knowledgeable in different security topics. On the other side driving security through design can have the following advantages:
Software design is central to the interest and competence of most developers.
By focusing on design, business and security concerns gain equal priority in the view of both business experts and developers.
By choosing good design constructs, non-security experts are able to write secure code.
By focusing on good domain design, many security bugs are solved implicitly.
2: Intermission: The anti-Hamlet
This chapter (which is based on a real case) presents an example of how a flaw in designing a model of an bookstore e-shop application negatively impacted the business.
The mistake done in the model was to represent the quantity of items from a shopping card as an integer, so the users of the application could add negative numbers of items so at the end the customers could receive money from the bookstore.
3: Core concepts of Domain-Driven Design
The chapter starts with the definition of the Domain Driven Design (DDD) and describing what are the qualities of a domain model to be effective:
Be simple so you focus on the essentials.
Be strict so it can be a foundation for writing code.
Capture deep understanding to make the system truly useful and helpful.
Be the best choice from a pragmatic viewpoint.
Provide you with a language you can use when you talk about the system.
The main notions from DDD that can be beneficial in the context of a more robust model are:
Entities
Entities are objects representing a thread of continuity and identity, going through a lifecycle, though their attributes may change.
Entities are one type of model objects that have some distinct properties. What makes
an entity special is that:
It has an identity that defines it and makes it distinguishable from others.
It has an identity that’s consistent during its life cycle.
It can contain other objects, such as other entities or value objects (see further for a value object definition).
It’s responsible for the coordination of operations on the objects it owns.
Value Objects
Value objects are objects describing or computing some characteristics of a thing.The key characteristics of a value objectare as follows:
It has no identity that defines it, but rather it’s defined by its value.
It’s immutable.
It should form a conceptual whole.
It can reference entities.
It explicitly defines and enforces important constraints.
It can be used as an attribute of entities and other value objects.
It can be short-lived.
Aggregates
An aggregate is a conceptual boundary used to group parts of the model together. The purpose of this grouping is to treat the aggregate as a unit. The key characteristics of a aggregates are:
Every aggregate has a boundary and a root.
The root is a single, specific entity contained in the aggregate.
The root is the only member of the aggregate that objects outside the boundary
can hold references to.
Objects within the aggregate can hold references to other aggregates.
Bounding context
Multiple models are in play on a large project; it’s possible to have two or more models having the same concepts but with different semantics. In the case of different models, there is a need to define explicitly the scope of a particular model as a bounded part of a software system. A bounded contextdelimits the applicability of a particular model.
Data crossing a semantic boundary is of special interest from a security perspective because this is where the meaning of a concept could implicitly change.
4: Code constructs promoting security
Problems areas addressed and the proposed constructs:
Problem
Section
Security problems involving data integrity and availability
Immutable objects
Security problems involving illegal input and state
Design by Contract
Security problems involving input validation
(Input) Validation
Immutable objects
Immutable objects are safe to share between threads and open up high data availability which is an important aspect when protecting a system against denial of service attacks. Immutable object could protect against security problems involving availability of a system.
Mutable objects, on the other hand, are designed for change, which can lead to illegal updates and modifications. Immutable objects will enforce the integrity of the data of an application.
Design by Contract
Design By Contract (see Meyer, Bertrand: Applying “Design by Contract”) is an approach for designing software that uses preconditions and post-conditions to document (or programmatically assert) the change in state caused by a piece of a program. Thinking about design in terms of preconditions and contracts helps you clarify which part of a design takes on which responsibility.
Many security problems arise because one part of the system assumes another part takes responsibility for something when, in fact, that part assumes the opposite.
The authors are presenting some example of checking preconditions for method arguments and constructors. The goal is to fail if the contract is not met and the program is not using the classes in a way they were designed to be used. The program has lost control of what’s happening, and the safest thing to do is to stop as fast as possible.
(Input) Validation
In the case of input validation the authors are going through a framework that tries to separate the different kinds of (input) validation. The list presented also suggests a good order in which to do the different kinds of validation. Cheap operations like checking the length of data come early in the list, and more expensive operations that require calling the database come later. If one the steps is failing then the entire validation process must fail.
Different validation steps:
Origin – Is the data from a legitimate sender?
Origin checks can be done by checking the origin IP or requiring an access token
Size – Is the size of the data in line with the context on which the data is used?
Lexical content – Does it contain the right characters and encoding?
When checking the lexical content of data, the important part is the content not the structure so, the data is scanned to see that it contains the expected characters and the expected encoding.
Syntax – Is the format right?
Semantics – Does the data make sense from the business point of view?
5: Domain primitives
Problems areas addressed:
Problem
Section
Security issues caused by inexact, error-prone, and
ambiguous code
Domain primitives
Security problems due to leakage of sensitive data
Read-once objects
Domain primitives
Domain primitives are similar to value objects in Domain-Driven Design. Key difference is and they must be enforced at the point of creation. Also the usage of language primitives or generic types (including null ) are forbidden to represent concepts in the domain model because it could caused inexact, error-prone, and ambiguous code.
At the creation of the domain primitives the different validation steps could be applied as explained into the previous chapter; see (Input) Validation section of chapter 4: Code constructs promoting security
A typical example of a domain primitive is a quantity (see the example from the chapter 2: Intermission: The anti-Hamlet) that should not be defined as a primitive type (a float or an int) but as a distinguish type that will contains all the necessary logic for creation of valid (from the domain point of view) instances of quantity type.
For example in the context of a book shop a quantity which is negative or a not an integer greater is not valid from the business domain point of view.
Read-once objects
A read-once object is an object designed to be read once (or a limited number of times). This object usually represents a value or concept in your domain that’s considered to be sensitive (for example, passport numbers, credit card numbers, or passwords). The main purpose of the read-once object is to facilitate detection of unintentional use of the data it encapsulates.
Here’s a list of the key aspects of a read-once object:
Its main purpose is to facilitate detection of unintentional use.
It represents a sensitive value or concept.
It’s often a domain primitive.
Its value can be read once, and once only.
It prevents serialization of sensitive data.
It prevents sub-classing and extension.
6: Ensuring integrity of state
This chapter it’s about the integrity of the DDD entities objects.Entities contains the state that represents the business rules so it is important that a newly created entity follow the business rules.
The first goal is to have entities already consisted at the creation time. This can be done forcing the object creation through a constructor with all mandatory attributes and optional attributes set via method calls. This works very well for simple business rules; for more complex business rules the usage of the Builder pattern is advised.
The second goal is to keep the entities consistency after the creations time during the usage of the entities by other software components. The main idea is to share only final attributes (that cannot be changed), not share mutable objects and use immutable domain primitives.
In the case of attributes containing collections, should not expose a collection but rather expose a useful property of the collection (for example to add an item into a collection, add a method that receive as parameter the item to be added). Collection can be protected by exposing an non modifiable version (see Collections.unmodifiableCollection)
7: Reducing complexity of state
This chapter is extending the discussion from the previous chapter and it presents how to handle DDD entities objects that can have multiple states. For example an entity representing an order can have a few valid states like “paid”, “shipped”, “lost” or “delivered”. Keeping the state of entities controlled becomes hard when entities become complex, especially when there are lots of states with complex transitions between them.
The authors are proposing 3 patterns to handle the entities state complexity:
Entity state object
The proposal is to have entity state be explicitly designed and implemented as a class of its own. With this approach, the state object is used as a delegated helper object for the entity. Every call to the entity is first checked with the state object. This approach makes it easier to grasp what states the entity can have.
Entity Snapshot
The pattern consist of generating immutable objects called snapshots from the an entity. The clients will use the snapshots for the read only operations. For changing the state of the underlying entity, the clients will have to use a domain service to which they’ll have to send updates.
A drawback of this approach is that it violates some of the ideas of object orientation, especially the guideline to keep data and its accompanying behavior close together, preferably in the same class.
From the security point of view this pattern it improves the integrity because because the snapshot is immutable so there’s no risk at all of the representation mutating to a foul state.
Entity relay
This pattern is to be used in the case when the entity have a big number of possible states with a complex graph of changing states. The basic idea of entity relay is to split the entity’s lifespan into phases, and let each entity represent its own phase. When a phase is over, the entity goes away, and another kind of entity takes over—like a relay race.
8: Leveraging your delivery pipeline for security
The chapter treats different test strategies that could be applied in order to have a better security posture.
For the unit tests, the authors propose to divide the tests into:
normal testing – Verifies that the design accepts input that clearly passes the domain rules
boundary testing – Verifies that only structurally correct input is accepted. Examples of boundary checks are length, size, and quantity,
invalid input testing – Verifies that the design doesn’t break when invalid input is handled. Empty data structures, null, and strange characters are often considered invalid input.
extreme input testing – Verifies that the design doesn’t break when extreme input is handled. For example, such input might include a string of 40 million characters.
Other topics covered are :
testing of feature toggles that can cause security vulnerabilities. A good rule of thumb is to create a test for every existing toggle and should test all possible combinations using automated tests.
testing of the availability of the application by simulating DOS attacks.
9: Handling failures securely
The chapter treats different topics around handling failures and program exceptions.
It’s a good practice to separate business exceptions and technical exceptions. For business exception the best practice is to create exception having a business meaning.
As a practice to avoid, shouldn’t intermix technical and business exceptions using the same type and never include business data in technical exceptions, regardless of whether it’s sensitive or not.
Another interesting idea is to not handle business failures as exceptions. A failure should be modeled as a possible result of a performed operation in the same way a success is. By designing failures as unexceptional outcomes, it’s possible to avoid the problems that come from using exceptions including ambiguity between domain and technical exceptions, and inadvertently leaking sensitive information.
Resilience and responsiveness are attributes of a system that are improving the system availability. To achieve this attributes the authors are presenting 2 patterns:
circuit breaker pattern – Circuit Breaker allows graceful handling of failed remote services. It’s especially useful when all parts of an application are highly decoupled from each other, and failure of one component doesn’t mean the other parts will stop working.
bulkhead pattern – The Bulkhead pattern is a type of application design that is tolerant of failure. In a bulkhead architecture, elements of an application are isolated into pools so that if one fails, the others will continue to function.
10: Benefits of cloud thinking
This chapter is treating design concepts to be used for achieving a better security posture in the context of cloud deployments.
The most important concept it’s the “The three R’s of enterprise security“. The methodology of three Rs is: Rotate, Repave and Repair and it offers a simple approach towards greater security of cloud deployments.
The basic idea is to be proactive than be reactive as seen in traditional enterprise security. Speed is of essence. The longer a deployment stays in a given configuration, the greater is the opportunity for threats to exploit any vulnerabilities.
Rotate: Rotate secrets every few minutes or hours. Rotating secrets doesn’t improve the security of the secrets themselves, but it’s an
effective way of reducing the time during which a leaked secret can be misused.
Repave: Repave servers and applications every few hours.Recreating all servers and containers and the applications running on them from a known good state every few hours is an effective way of making it hard for malicious software to spread through the system.
Repair: Repair vulnerable software as soon as possible after a patch is available. This goes for both operating systems and applications third party dependencies. The reason for repairing as often as you can is that for every new version of the software, something will have changed so an attacker constantly needs to find new ways to break it.
11: Intermission: An insurance policy for free
This chapter is very similar with the chapter 2, Intermission: The anti-Hamlet. It presents a real case (of an insurance company) that migrated a monolithic application to a micro-service application.
Due to this migration, the application was split into 2 different micro-services handled by 2 different teams. Having 2 independent teams handling different parts of the application and some functional changes in one of the micro-services will have as impact that the notion of Payment will have different meanings for the 2 micro-services. This miss-match will generate some subtle bugs even if none of the 2 systems were not broken.
12: Guidance in legacy code
This chapter is a kind of review of all the practices described in previous chapters that are applicable to legacy code.
It treats about the usage of domain primitives (see chapter 5 Domain primitives) to replace ambiguous parameters in APIs which are a common source of security bugs, the usage of read-once objects (see chapter 5 Domain primitives) which limits the number of times a sensitive values can be accessed allowing it to detect unintentional access, the usage of security tests that are testing look for invalid and extreme inputs (see chapter 8 Leveraging your delivery pipeline for security)
13: Guidance in micro-services
This chapter is very similar with the previous one but the context is the new approach of writing applications using micro-services.
Implementing security for a micro-service architecture is more difficult that in a case of a monolithic architecture because of the loose coupling of micro-services.
Splitting a monolithic application to different micro-services is rather a difficult task but a good design principle is to think of each service as a bounded context (see chapter 3 Core concepts of Domain-Driven Design for definition of bounded context).
Analyzing confidentiality, integrity, availability, and traceability across all services and data sensitivity is more difficult than in a case of classical architecture. The only way to treat this security topics in a complete way is to have a broader view of the entire applications and not only on a subset of the micro-services.
14: A final world: Don’t forget about security!
The entire book was talking about how to not think about security, but still getting a good security posture anyway. This chapter speaks about how important is to think and learn about the security anyway and it gives advises that could be found in more “classical” security books:
Should use code security reviews as a recurring part of secure development lifecycle (SDLC)
It is important to invest in tooling that provides quick access to information about security vulnerabilities across the technological entire stack.
Penetration tests should be done recurrently and the feedback from this tests should be used as an opportunity to improve the application design.
Having a team and processes to handle security incidents and the security incident mechanism should focus on learning to become more resistant to attacks.
All the Linux security mechanisms that are used under the hood by containers are very well explained with multiple (valuable) examples; namespaces, cgroups, capabilities, system calls, AppArmor, SecComp. At the end of the day, container security is just a subset of Linux security.
No hidden (or un-hidden) publicity to any commercial tools, despite the fact that the author is working for AquaSecurity company.
A lot of references towards Internet accessible resources; unfortunately, the author is using url shortening so I wish you good luck to copy them into a browser if you have the paper version of the book.
Clear and concise writing style.
What I think could have been done better:
Even if the book is about security of/in containers, there is no general introduction of the container notion or the actual container landscape.
A lot of forward references in different chapters; usually in technical books you find backward references because (very often) the knowledge is build on top of the knowledge of previous chapters.
There are a few chapters which are very thin, especially toward the end; the last chapter (chapter 14) for example is just 2 pages long.
This chapter defines different attack vectors for the containers and the infrastructure that they are running on. This attack vectors specifically linked to containers are:
Application code vulnerabilities
Badly configured images
Badly configured containers
Build Image attack
Supply chain attack
Vulnerable hosts
Exposed secrets
Insecure networking
Container runtime vulnerabilities
Containers attack vectors
The containers very often are deployed on cloud infrastructures very often using a multi-tenant model which brings new threats and new attack vectors on top of previous ones.
After presenting and explaining the problems that usage of containers will bring the author is focusing on (security) general guidelines that should be used when implementing different mitigations controls:
least privilege
each container should have a minimum set of permissions to fulfill it’s function.
defense in depth
reducing the attack surface
split the monolithic application in smaller, simpler microservices that would imply a less complex architecture that would reduce the attack surface.
limiting the blast radius
if one container is compromised some controls should be put in place to not affect the others software components
segregation of duties
permissions and credentials can be passed only into the containers that need them
2. Linux System Calls, Permissions and Capabilities
This chapter it presents the basics of Linux System calls, the Linux file permissions (an extensive explanation is done on the usage of of setuid and getuid) and the Linux Capabilities. For each of this Linux features some examples are given and the author emphasizes that this capabilities are heavily used by the containers and the containers run-times because at the end of the day, a container is just a Linux process running on a host.
3. Control Groups
This chapter is very similar with the previous one in the sense that it does not speak about containers but about a Linux security feature that is heavily used by the containers. This chapter is dedicated to Linux control groups (a.k.a cgroups) which have as goal to limit the resources, such as memory, CPU, network input/output, that a process or a group of processes can use.
Containers runtimes are using cgroups behind the scene to limit resources used by containers, so cgroups provides protection against a class of attacks that attempt to disrupt running applications by consuming excessive resources, thereby starving legitimate applications.
4. Container Isolation
This chapter treats another Linux feature that is cornerstone for container security: Linux namespaces.
Linux namespaces are a feature of the Linux kernel that partitions kernel resources such that one or more processes sees one set of resources while another set of processes sees a different set of resources. If cgroups control the resources that a process can use, namespaces control what it can see.
For each of the existing namespaces (Unix Timesharing System, Process IDs, Mount Points, Network, Users and Group Ids, Inter-Process Communications) the author shows how can be created from command line. For some namespaces a comparison is done between the isolation implemented by a container runtime and the isolation offered just using the tools offered out of the box by Linux.
5. Virtual Machines
This chapter is an introduction to virtual machines. It is explained different types of hypervisors (a.k.a VMM – Virtual Machine Monitor):
Type1 – the hypervisor is installed directly on top of the hardware with no operating system underneath (ex: Hyper-V, Xen)
Type2 – the hypervisor is installed on top of a Host Os (ex: VirtualBox, Parallels, QEMU)
Kernel Based Virtual Machines – this is a kind of hybrid type because it consists in a hypervisor running within the kernel of the hos Os (ex: Linux KVM).
Different types of hypervisors
After describing the types of hypervisors the author explained how the hypervisors are achieving the virtualization via a mechanism called “trap and emulate“. When an OS is running as a virtual machine in a hypervisor, some of its instructions may conflict with the host operation system. So the hypervisor will emulates the effect of that specific instruction or action without carrying it out. In this way, the host OS is not effected by the guest’s actions.
The chapter is concluded with the advantages of hypervisors for process isolation compared with the kernel processes (which are the cornerstone of containers) and the main drawbacks of hypervisors.
From the process isolation point of view the hypervisors are offering a greater isolation and the difference is that hypervisors have a simpler job to fulfill comparing with OS kernels. In a kernel, user space processes are allowed some visibility of each other, but there is no sharing of memory or sharing of processes in the case of hypervisors.
On the drawback side, the VMs have start-up times that are several orders of magnitude greater than a container, containers give developers a convenient ability to “build once, run anywhere” quickly and efficiently, each virtual machine has the overhead of running a whole kernel compared with containers that are sharing a kernel so containers can be very efficient in both resource use and performance.
6. Container Images
This chapter is focusing on the images; it starts by explaining the OCI standards covering the image specification. In this chapter you will be able to see how different topics from previous chapters (namespaces, capabilities, control groups, root file system) are fitting together so the end user can define, build and execute a container.
The second par of the chapter is focusing on different attack vectors on an image:
Image Attack Vectors
Some of this attack vectors are not really linked to container technology (tamper source code, vulnerable dependencies, attack deployment via build machine) but others are container specific attack vectors (tamper the docker file, usage of vulnerable base images, modify images during build).
7. Software Vulnerabilities in Images
The chapter is dedicated to vulnerabilities managements in general and also in the context of containers. For the general/generic part, the author explains what is the workflow when a vulnerability is discovered:
after the discovery the person the new issue will get a unique identifier that begins with “CVE” (Common Vulnerabilities and Exposures) , followed by the year and an unique id.
A responsible security disclosure is agreed between the entity that found the vulnerability and the entity that “owns” the software. Both parties agree on a timeframe after which the researcher can publish their findings.
The entity that “owns” the software is fixing the vulnerability and delivers a patch.
Once the vulnerability can be disclosed, it receive a unique identifier that begins with “CVE,” which stands for Common Vulnerabilities and Exposures.
Strangely enough, the author does not mention the usage of CVSS (Common Vulnerability Scoring System) score of a vulnerability. Usually CVSS score is used to judge the impact of the vulnerability.
The second part of the chapter is focusing on ways to handle the vulnerability management in the context of containers. A few interesting and valuable ideas:
(always) use immutable containers :
If containers are downloading code at runtime, different instances of the container could be running different versions of that code, but it would be difficult to know which instance is running what version.
It’s harder to control and ensure the provenance of the software running in each container if it could be downloaded at any time and from anywhere.
Building a container image and storing it in a registry is very simple to automate in a CI/CD pipeline.
regular scan of images.
Regularly re-scanning container images allows the scanning tool to check the contents against its most up-to-date knowledge about vulnerabilities. A very common approach is to re-scan all deployed images every 24 hours, in addition to scanning new images as they are built, as part of an automated CI/CD pipeline.
use a tool that can do more than scanning for vulnerabilities (if possible). A (non-exhaustive) list of extra features that the scanner could have:
Known malware within the image
Executables with the setuid bit
Images configured to run as root
Secret credentials such as tokens or passwords
Sensitive data in the form of credit card or Social Security numbers or something similar
8. Strengthening Container Isolation
This chapter is an extension of the Chapter 4 (Container Isolation); it presents other ways to extend the container isolation using mechanisms and framework beyond the Linux kernel features.
The first part of the chapter presents mechanisms already present in Linux ecosystem that can be used in other contexts than containers, namely:
Seccomp is a mechanism for restricting the set of system calls that an application is allowed to make.
The Docker default seccomp profile blocks more than 40 of the 300+ syscalls (including all the examples just listed) without ill effects on the vast majority of containerized applications. Unless you have a reason not to do so, it’s a good default profile to use.
In AppArmor, a profile can be associated with an executable file, determining what that file is allowed to do in terms of capabilities and file access permissions.
AppArmor implement mandatory access controls. A mandatory access control is set by a central administrator, and once set, other users do not have any ability to modify the control or pass it on to another user.
SElinux lets you constrain what a process is allowed to do in terms of its interactions with files and other processes. Each process runs under an SELinux domain and every file has a type.
Every file on the machine has to be labeled with its SELinux information before you can enforce policies. These policies can dictate what access a process of a particular domain has to files of a particular type.
In the second part of the chapter the author presents container specific technologies that could be used to enforce the containers isolation:
gVisor provides a virtualized environment in order to sandbox containers. The system interfaces normally implemented by the host kernel are moved into a distinct, per-sandbox application kernel in order to minimize the risk of a container escape exploit.
To do this, a component of gVisor called the Sentry intercepts syscalls from the application. Sentry is heavily sandboxed using seccomp, such that it is unable to access filesystem resources itself. When it needs to make systemcalls related to file access, it off-loads them to an entirely separate process called the Gofer. Even those system calls that are unrelated to filesystem access are not passed through to the host kernel directly but instead are reimplemented within the Sentry. Essentially it’s a guest kernel, operating in user space.
The idea with Kata Containers is to run containers within a separate virtual machine. This approach gives the ability to run applications from regular OCI format container images, with all the isolation of a virtual machine.
Kata uses a proxy between the container runtime and a separate target host where the application code runs. The runtime proxy creates a separate virtual machine using QEMU to run the container on its behalf.
Is a virtual machine offering the benefits of secure isolation through a hypervisor and no shared kernel, but with startup times around 100ms.
Firecracker designers have stripped out functionality that is generally included in a kernel but that isn’t required in a container like enumerating devices. The main saving comes from a minimal device model that strips out all but the essential devices.
9. Breaking Container Isolation
After explaining in previous chapters what can be done to enhance the container isolation, this chapter is focusing on how a container could be misconfigured so this isolation is broken.
The following misconfigurations are explained:
Run containers using the default (root) user.
Unless your container image specifies a non-root user or you specify a non default user when you run a container, by default the container will run as root.
The best option is to define a custom user inside the container but if this option is not available then a few other options are presented:
override the user id; this is possible in Docker using the –user flag of the docker run command.
use user namespaces (covered in chapter 2) within the container, so that root inside the container is not the same as root on the host. You can enable the use of user namespaces in Docker, but it’s not turned on by default. If you’re interested about how to do it please take a look to Isolate containers with a user namespace
The use of —priviledged flag
The usage of priviledged flag give extended (Linux) capabilities to the process representing the running container. Docker introduced the –privileged flag to enable DinD (Docker in Docker) which can be used by build tools(very often in the CI/CD context) running as containers, which need access to the Docker daemon in order to use Docker to build container images.
Mounting sensitive directories
Mounting inside the containers the root file system or specific host folders is not a very good idea. List of folders to avoid mounting:
Mounting /etc would permit modifying the host’s /etc/passwd file from within the container.
Mounting /bin, /usr/bin or /usr/sbin would allow the container to write executables into the host directory.
Mounting host log directories into a container could enable an attacker to modify or erase the logs.
Mounting the Docker Socket
In a Docker environment, there is a Docker daemon process that essentially does all the work. When you run the docker command-line utility, this sends instructions to the daemon over the Docker socket that lives at /var/run/docker.sock . Any entity that can write to that socket can also send instructions to the Docker daemon. The daemon runs as root and will happily build and run any software of your choosing on your behalf.
Accessing the Docker Daemon via REST API with no authentication
This in not really mentioned in the book (even that I think that it should) but it’s very similar with the previous paragraph. The docker daemon can be also accessed via a REST API; by default the API is accessible with no authentication.
Sharing namespaces between the container and the host
Containerized processes are all visible from the host; thus, sharing the process namespace to a container lets that container see the other containerized processes.
10. Container Network Security
The chapter starts with an introduction to ISO/OCI networking model and this model is used during the chapter to explain different topics related to network security. The author is focusing on explaining the networking model for containers running under Kubernetes orchestrator but even if you’re not interested on K8s it is still possible to find some technology agnostic best practices:
Default Deny Ingress: define a network policy that denies ingress traffic by default and then add policies to permit traffic only where you expect it
Default Deny Egress: Same as the Ingress part.
Restricts ports: Restrict traffic so that it is accepted only to specific ports for each application.
11. Securely Connecting Components with TLS
Most of the chapter content have noting to do with containers (this is highlighted even by the author itself) and is treating the history of SSL/TLS protocol and the basics of PKI : Public/Private Key, X509 certificates, Certificate Signing Requests, Certificate Revocation and Certificate Authorities.
The only piece of information linked to containers that I found important is the that rather than writing your own code to set up secure connections, you can choose to use a service mesh to do it for you.
12. Passing Secrets to Containers
The chapter starts by enumerating properties that a secret must have:
it should be stored in encrypted form so that it’s not accessible to every user or entity.
it should never be written to disk unencrypted (and even better just held it in memory and never write it on disk).
it should be revocable (make them invalid in the event that the secret should no longer be trusted).
it should be able to rotate it.
it should be independent of the lifecycle of the consumers.
only software components that need the access to it should be able to read the secret
Next paragraph enumerates different ways of injecting information (secrets included) into containers:
store the information into the image
obviously this is not a very good idea for secrets because can be accessed by anyone having the image and it cannot be changed unless the images are rebuild.
use environment variables as part of the configuration that goes along with the image
same problems as the hard-coded secrets
pass the secret over the network
the running container will make the appropriate network calls to retrieve or receive the information.
in this case the date(secret) in transit should be encrypted, most probably using a service mesh
the principal drawback of this approach is how the container will be able to authenticate to this service offering the secret; the author does not offer any solution
pass the secrets at runtime using the environment variables.
environment variables defined for the container can be seen using different commands like docker inspect.
pass the secrets through files.
This option consists in write the secrets into files that the container can access through a mounted volume.
Combining this with a secure secrets store ensures that secrets are never stored “at rest” unencrypted.
I found this chapter rather strange because it explains how to not pass secrets to containers instead of presenting the good practices. Speaking about good practices, this are very briefly mentioned like the usage of a third-party (commercial) solution for secret storage. I would have preferred to have more insights on how this tools are working.
13. Container Runtime Protection
This chapter treats the controls to put in place in order to assure the protection of the running containers.
The first idea is to compute a container profile. This profile should be computed prior to the deployment of the container in live and should contains the normal behavior of the container. Once this profile is known, then at runtime a (container security)tool would be able to compare the profile with the real behavior of the container and detect any discrepancy.
This container profile could contains the following information:
network traffic – the other containers and or hosts that the container normally communicates with.
executable – what kind of commands the normal cunning container is executing. In this case the author suggests to use eBPF (which stands for extended Berkeley Packet Filter) technology.
file access – what files from the container file system are usually accessed.
user IDs – as a general rule, if the container is doing one job, it probably needs to operate under only one user identity.
(Linux) capabilities – the (minimal) list of capabilities the container needs in order to execute properly; any attempt to use a capability not present in the list should raise a red flag.
The second idea presented is the drift prevention. It’s considered best practice to treat containers as immutable. The container is instantiated from its image, and then the contents of the container should not change. In the case of drift prevention the (container security) tool will be able to make the difference between the software that came from the image, and the software that is running in the workload so it gives the ability to immediately stop any software that doesn’t belong to the (original) image.
14. Containers and the OWASP Top 10
This sounds a very interesting topic but unfortunately the author it expedite it very fast. In some of the cases the author is even confessing that the type of risk is not linked to containers and could be applied to non containers world also.
Same OWASP Top 10 (2017) have direct applicability in the container word:
This can be linked with the usage of secrets in container word. These secrets need to be stored with care and passed into containers at runtime, as discussed in Chapter 12.
The containerized applications that must communicate between them would need to identify each other using certificates, and communicate using secure connections. This can be handled directly by containers, or you can use a service mesh
This book is doing a very good job in covering different mechanisms that could be used in order to build secure (RESTful) APIs. For each security control the author explains what kind of attacks the respective control is able to mitigate.
The reader should be comfortable with Java and Maven because most of the code examples of the book (and there are a lot) are implemented in Java.
The diagram of all the security mechanism presented:
Part 1: Foundations
The goal of the first part is to learn the basics of securing an API. The author starts by explaining what is an API from the user and from developer point of view and what are the security properties that any software component (APIs included) should fill in:
Confidentiality – Ensuring information can only be read by its intended audience
Integrity – Preventing unauthorized creation, modification, or destruction of information
Availability – Ensuring that the legitimate users of an API can access it when they need to and are not prevented from doing so.
Even if this security properties looks very theoretical the author is explaining how applying specific security controls would fulfill the previously specified security properties. The following security controls are proposed:
Encryption of data in transit and at rest – Encryption prevents data being read or modified in transit or at rest
Authentication – Authentication is the process of verifying whether a user is who they say they are.
Authorization/Access Control – Authorization controls who has access to what and what actions they are allowed to perform
Audit logging – An audit log is a record of every operation performed using an API. The purpose of an audit log is to ensure accountability
Rate limiting – Preserves the availability in the face of malicious or accidental DoS attacks.
This different controls should be added into a specific order as shown in the following figure:
Different security controls that could/should be applied for any API
To illustrate each control implementation, an example API called Natter API is used. The Natter API is written in Java 11 using the Spark Java framework. To make the examples as clear as possible to non-Java developers, they are written in a simple style, avoiding too many Java-specific idioms. Maven is used to build the code examples, and an H2 in-memory database is used for data storage.
The same API is also used to present different types of vulnerabilities (SQL Injection, XSS) and also the mitigations.
Part 2: Token-based Authentication
This part presents different techniques and approaches for the token-based authentication.
Session cookie authentication
The first authentication technique presented is the “classical” HTTP Basic Authentication. HTTP Basic Authentication have a few drawbacks like there is no obvious way for the user to ask the browser to forget the password, the dialog box presented by browsers for HTTP Basic authentication cannot be customized.
But the most important drawback is that the user’s password is sent on every API call, increasing the chance of it accidentally being exposed by a bug in one of those operations. This is not very practical that’s why a better approach for the user is to login once then be trusted for a specific period of time. This is basically the definition of the Token-Based authentication:
Token Based authentication
The first presented example of Token-Based authentication is using the HTTP Base Authentication for the dedicated login endpoint (step number 1 from the previous figure) and the session cookies for moving the generated token between the client and the API server.
The author take the opportunity to explain how session cookies are working and what are the different attributes but especially he presents the attacks that are possible in the case of using session cookies. The session fixation attack and the Cross-Site Request Forgery attack (CSRF) are presented in details with different options to avoid or mitigate those attacks.
Tokens whiteout cookies
The usage of session cookies is tightly linked to a specific domain and/or sub-domains. In case you want to make requests cross domains then the CORS (Cross-Origin Resource Sharing) mechanism can be used. The last part of the chapter treating the usage of session cookies contains detailed explanations of CORS mechanism.
Using the session cookies as a mechanism to store the authentication tokens have a few drawbacks like the difficulty to share cookies between different distinguished domains or the usage of API clients that do not understand the web standards (mobile clients, IOT clients).
Another option that is presented are the tokens without cookies. On the client side the tokens are stored using the WebStorage API. On the server side the tokens are stored into a “classical” relational data base. For the authentication scheme the Bearer authentication is used (despite the fact that the Bearer authentication scheme was created in the context of OAuth 2.0 Authorization framework is rather popular in other contexts also).
In case of this solution the least secure component is the storage of the authentication token into the DB. In order to mitigate the risk of the tokens being leaked different hardening solutions are proposed:
store into the DB the hash of tokens
store into the DB the HMAC of the tokens and the (API) client will then send the bearer token and the HMAC of the token
This authentication scheme is not vulnerable to session fixation attacks or CSRF attacks (which was the case of the previous scheme) but an XSS vulnerability on the client side that is using the WebStorage API would defeat any kind of mitigation control put in place.
Self-contained tokens and JWTs
The last chapter of this this (second) part of the book treats the self-contained or stateless tokens. Rather than store the token state in the database as it was done in previous cases, you can instead encode that state directly into the token ID and send it to the client.
The most client-side tokens used are the Json Web Token/s (JWT). The main features of a JWT token are:
A standard header format that contains metadata about the JWT, such as which MAC or encryption algorithm was used.
A set of standard claims that can be used in the JSON content of the JWT, with defined meanings, such as exp to indicate the expiry time and sub for the subject.
A wide range of algorithms for authentication and encryption, as well as digital signatures and public key encryption.
A JWT token can have three parts:
Header – indicates the algorithm of how the JWT was produced, the key used to authenticate the JWT to or an ID of the key used to authenticate. Some of the header values:
alg: Identifies which algorithm is used to generate the signature
kid: Key Id; as the key ID is just a string identifier, it can be safely looked up in server-side set of keys.
jwk: The full key. This is not a safe header to use; Trusting the sender to give you the key to verify a message loses all security properties.
jku: An URL to retrieve the full key. This is not a safe header to use. The intention of this header is that the recipient can retrieve the key from a HTTPS endpoint, rather than including it directly in the message, to save space.
Payload/Claims – pieces of information asserted about a subject. The list of standard claims:
iss (issuer): Issuer of the JWT
sub (subject): Subject of the JWT (the user)
aud (audience): Recipient for which the JWT is intended
exp (expiration time): Time after which the JWT expires
nbf (not before time): Time before which the JWT must not be accepted for processing
iat (issued at time): Time at which the JWT was issued; can be used to determine age of the JWT
jti (JWT ID): Unique identifier; can be used to prevent the JWT from being replayed (allows a token to be used only once)
Signature – Securely validates the token. The signature is calculated by encoding the header and payload using Base64url Encoding and concatenating the two together with a period separator. That string is then run through the cryptographic algorithm specified in the header.
Example of JWT token
Even if the JWT could be used as self-contained token by adding the algorithm and the signing key into the header, this is a very bad idea from the security point of view because you should never trust a token sign by an external entity. A better solution is to store the algorithm as metadata associated with a key on the server.
Storing the algorithm and the signing key on the server side it also helps to implement a way to revoke tokens. For example changing the signing key it can revoke all the tokens using the specified key. Another way to revoke tokens more selectively would be to add to the DB some token metadata like token creation date and use this metadata as revocation criteria.
Part 3: Authorization
OAuth2 and OpenID Connect
A way to implement authorization using JWT tokens is by using scoped tokens. Typically, the scope of a token is represented as one or more string labels stored as an attribute of the token. Because there may be more than one scope label associated with a token, they are often referred to as scopes. The scopes (labels) of a token collectively define the scope of access it grants.
A scoped token limits the operations that can be performed with that token. The set of operations that are allowed is known as the scope of the token. The scope of a token is specified by one or more scope labels, which are often referred to collectively as scopes.
Scopes allow a user to delegate part of their authority to a third-party app, restricting how much access they grant using scopes. This type of control is called discretionary access control (DAC) because users can delegate some of their permissions to other users.
Another type of control is the mandatory access control (MAC), in this case the user permissions are set and enforced by a central authority and cannot be granted by users themselves.
OAuth2 is a standard to implement the DAC. OAuth uses the following specific terms:
The authorization server (AS) authenticates the user and issues tokens to clients.
The user also known as the resource owner (RO), because it’s typically their resources that the third-party app is trying to access.
The third-party app or service is known as the client.
The API that hosts the user’s resources is known as the resource server (RS).
To access an API using OAuth2, an app must first obtain an access token from the Authorization Server (AS). The app tells the AS what scope of access it requires. The AS verifies that the user consents to this access and issues an access token to the app. The app can then use the access token to access the API on the user’s behalf.
One of the advantages of OAuth2 is the ability to centralize authentication of users at the AS, providing a single sign-on (SSO) experience. When the user’s client needs to access an API, it redirects the user to the AS authorization endpoint to get an access token. At this point the AS authenticates the user and asks for consent for the client to be allowed access.
OAuth can provide basic SSO functionality, but the primary focus is on delegated third-party access to APIs rather than user identity or session management. The OpenID Connect (OIDC) suite of standards extend OAuth2 with several features:
A standard way to retrieve identity information about a user, such as their name, email address, postal address, and telephone number.
A way for the client to request that the user is authenticated even if they have an existing session, and to ask for them to be authenticated in a particular way, such as with two-factor authentication.
Extensions for session management and logout, allowing clients to be notified when a user logs out of their session at the AS, enabling the user to log out of all clients at once.
Identity-based access control
In this chapter the author introduces the notion of users, groups, RBAC (Role-Based Access Control) and ABAC (Access-Based Access Control). For each type of access control the author propose an ad-hoc implementation (no specific framework is used) for the Natter API (which is the API used all over the book to present different security controls.)
Capability-based security and macaroons
A capability is an unforgeable reference to an object or resource together with a set of permissions to access that resource. Compared with the more dominant identity-based access control techniques like RBAC and ABAC capabilities have several differences:
Access to resources is via unforgeable references to those objects that also grant authority to access that resource. In an identity-based system, anybody can attempt to access a resource, but they might be denied access depending on who they are. In a capability-based system, it is impossible to send a request to a resource if you do not have a capability to access it.
Capabilities provide fine-grained access to individual resources.
The ability to easily share capabilities can make it harder to determine who has access to which resources via your API.
Some capability-based systems do not support revoking capabilities after they have been granted. When revocation is supported, revoking a widely shared capability may deny access to more people than was intended.
The way to use capability-based security in the context of a REST API is via capabilities URIs. A capability URI (or capability URL) is a URI that both identifies a resource and conveys a set of permissions to access that resource. Typically, a capability URI encodes an unguessable token into some part of the URI structure. To create a capability URI, you can combine a normal URI with a security token.
The author adds the capability URI to the Netter API and implements this with the token encoded into the query parameter because this is simple to implement. To mitigate any threat from tokens leaking in log files, a short-lived tokens are used.
But putting the token representing the capability in the URI path or query parameters is less than ideal because these can leak in audit logs, Referer headers, and through the browser history. These risks are limited when capability URIs are used in an API but can be a real problem when these URIs are directly exposed to users in a web browser client.
One approach to this problem is to put the token in a part of the URI that is not usually sent to the server or included in Referer headers.
The capacities URIs can be also be mixed with identity for handling authentication and authorization.There are a few ways to communicate identity in a capability-based system:
Associate a username and other identity claims with each capability token. The permissions in the token are still what grants access, but the token additionally authenticates identity claims about the user that can be used for audit logging or additional access checks. The major downside of this approach is that sharing a capability URI lets the recipient impersonate you whenever they make calls to the API using that capability.
Use a traditional authentication mechanism, such as a session cookie, to identify the user in addition to requiring a capability token. The cookie would no longer be used to authorize API calls but would instead be used to identify the user for audit logging or for additional checks. Because the cookie is no longer used for access control, it is less sensitive and so can be a long-lived persistent cookie, reducing the need for the user to frequently log in
The last part of the chapter is about macaroons which is a technology invented by Google (https://research.google/pubs/pub41892/). The macaroons are extending the capabilities based security by adding more granularity.
A macaroon is a type of cryptographic token that can be used to represent capabilities and other authorization grants. Anybody can append new caveats to a macaroon that restrict how it can be used
For example is possible to add new capabilities that allows only read access to a message created after a specific date. This new added extensions are called caveats.
Part 4: Microservice APIs in Kubernetes
Microservice APIs in K8S
This chapter is an introduction to Kubernetes orchestrator. The introduction is very basic but if you are interested in something more complete then Kubernetes in Action, Second Edition is the best option. The author also is deploying on K8S a (H2) database, the Natter API (used as demo through the entire book) and a new API called Linked-Preview service; as K8S “cluster” the Minikube is used.
Having an application with multiple components is helping him to show how to secure communication between these components and how to secure incoming (outside) requests. The presented solution for securing the communication is based on the service mesh idea and K8s network policies.
A service mesh works by installing lightweight proxies as sidecar containers into every pod in your network. These proxies intercept all network requests coming into the pod (acting as a reverse proxy) and all requests going out of the pod.
Securing service-to-service APIs
The goal of this chapter is to apply the authentication and authorization techniques already presented in previous chapters but in the context of service-to-service APIs. For the authentication the API’s keys, the JWT are presented. To complement the authentication scheme, the mutual TLS authentication is also used.
For the authorization the OAuth2 is presented. A more flexible alternative is to create and use service accounts which act like regular user accounts but are intended for use by services. Service accounts should be protected with strong authentication mechanisms because they often have elevated privileges compared to normal accounts.
The last part of the chapter is about managing service credentials in the context of K8s. Kubernetes includes a simple method for distributing credentials to services, but it is not very secure (the secrets are Base64 encoded and can be leaked by cluster administrator).
Secret vaults and key management services provide better security but need an initial credential to access. Using secret vaults have the following benefits:
The storage of the secrets is encrypted by default, providing better protection of secret data at rest.
The secret management service can automatically generate and update secrets regularly (secret rotation).
Fine-grained access controls can be applied, ensuring that services only have access to the credentials they need.
The access to secrets can be logged, leaving an audit trail.
Part 5: APIs for the Internet of Things
Securing IoT communications
This chapter is treating how different IoT devices could communicate securely with an API running on a classical system. The IoT devices, compared with classical computer systems have a few constraints:
An IOT device has significantly reduced CPU power, memory, connectivity, or energy availability compared to a server or traditional API client machine.
For efficiency, devices often use compact binary formats and low-level networking based on UDP rather than high-level TCP-based protocols such as HTTP and TLS.
Some commonly used cryptographic algorithms are difficult to implement securely or efficiently on devices due to hardware constraints or threats from physical attackers.
In order to cope with this constraints new protocols have been created based on the existing protocols and standards:
Datagram Transport Layer Security (DTLS). DTLS is a version of TLS designed to work with connectionless UDP-based protocols rather than TCP based ones. It provides the same protections as TLS, except that packets may be reordered or replayed without detection.
JOSE (JSON Object Signing and Encryption) standards. For IoT applications, JSON is often replaced by more efficient binary encodings that make better use of constrained memory and network bandwidth and that have compact software implementations.
COSE (CBOR Object Signing and Encryption) provides encryption and digital signature capabilities for CBOR and is loosely based on JOSE.
In the case when the devices needs to use public key cryptography then the key distribution became a complex problem. This problem could be solved by generating random keys during manufacturing of the IOT device (device-specific keys will be derived from a master key and some device-specific information) or through the use of key distribution servers.
Securing IoT APIs
The last chapter of the book is focusing on how to secure access to APIs in Internet of Things (IoT) environments meaning APIs provided by the devices or cloud APIs which are consumed by devices itself.
For the authentication part, the IoT devices could be identified using credentials associated with a device profile. These credentials could be an encrypted pre-shared key or a certificate containing a public key for the device.
For the authorization part, the IoT devices could use the OAuth2 for IoTwhich is a new specification that adapts the OAuth2 specification for constrained environments .




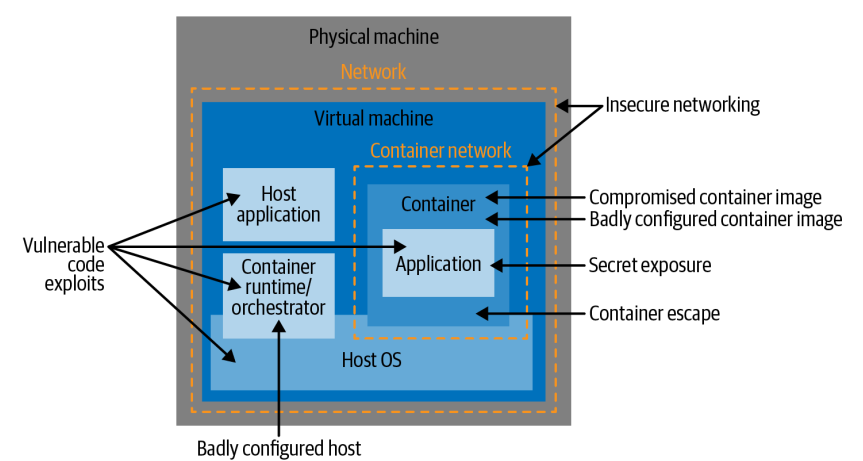
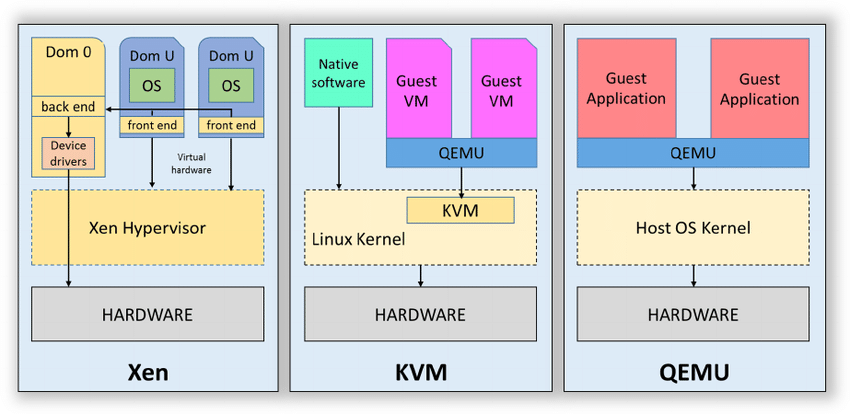
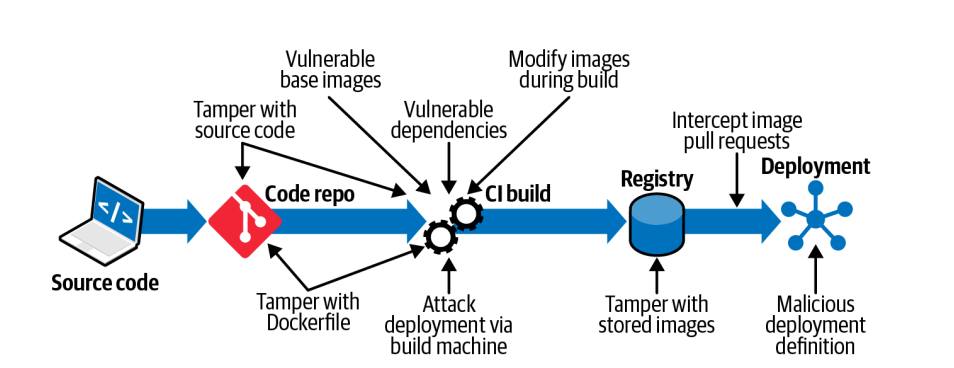

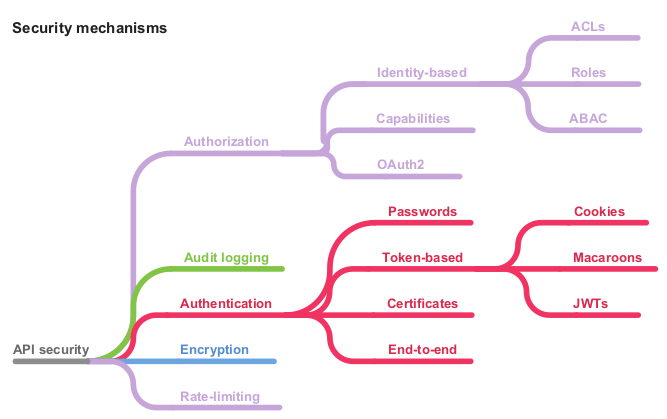
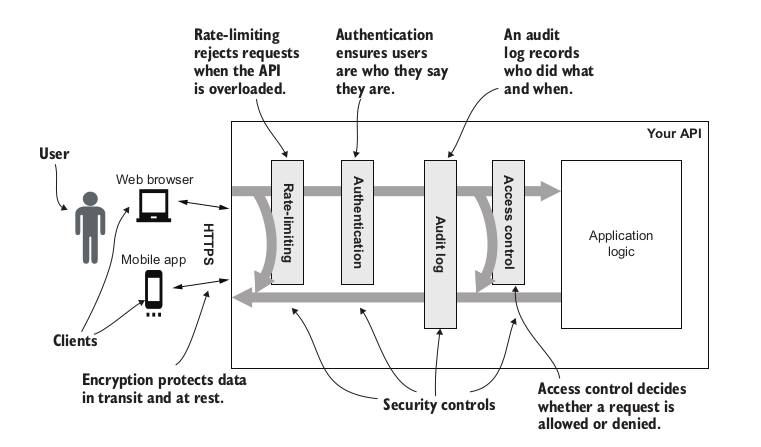
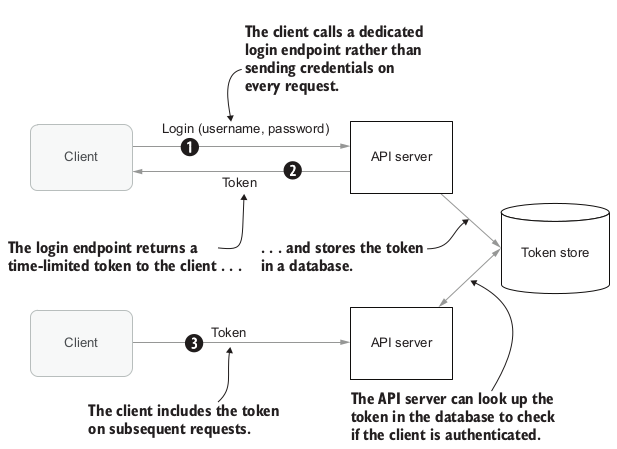
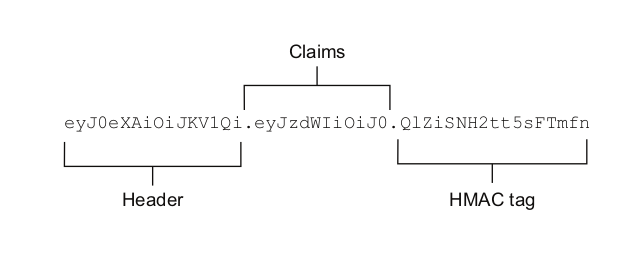
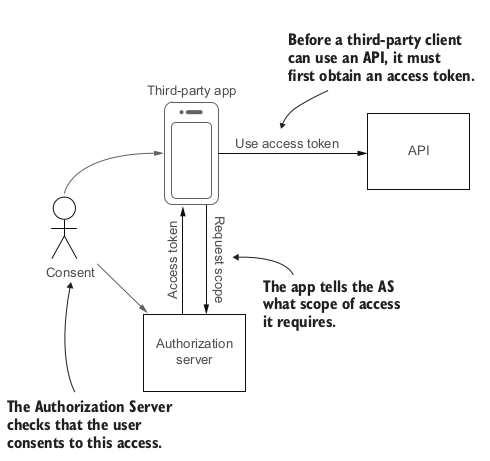

You must be logged in to post a comment.