Here are my quick notes from the BruCON 2018 conference. All the slides of the conference can be found here.
2018 conference. All the slides of the conference can be found here.
$SignaturesAreDead = “Long Live RESILIENT Signatures” wide ascii nocase (by Daniel Matthew)
Background
Signatures and indicators: what is a good signature ? A good signature depends of the context but the main properties are:
- More resilient than rigid (resist evasion and normal changes).
- More methodology-based than specific (capture methods or techniques).
- More proactive than reactive (identifies new technologies )
Process
- Define detection
- what. where, when to find.
- Assemble a sample set
- collected sample set.
- generated sample set.
- try to enumerate the entire problem set.
- Test existing detection/s
- Test existing detection capabilities for any free wins.
- Adjust priorities of existing applicable existing detections.
- Generate data
- logs.
- binary metadata.
- Write detection
- start broad and tune after.
- Test and tune
Process Walk-through for binaries
It applies the previous process to binaries.Malware binaries changes very often. In this case can’t rely on anti-viruses.
Process Walk-through for regsvr32.exe
It applies the previous process to the regsvr32.exe. It shows that is rather difficult to detect the regsvr32 arguments or process name
because there are multiple possibilities for the parameters for ex: /s or -s /u or -s or /us or -us.
Approaches that payed off to detect the execution of regsvr32.:
- Handle obfuscation separately.
- Handle renamed .exe/.dll separately
Takeaways
- Know what you are detecting today and HOW you are detecting it.
- Capture result of hunts as new detections.
All Your Cloud Are Belong To Us – Hunting Compromise in Azure (by Nate Warfield)
| Traditional network (old days) | Cloud Network |
|---|---|
| server restriction was restricted | every vm exposed to internet |
| many layers of ACLs + segmentation | VM’s deployed with predefined firewall |
| dedicated deployment teams | anyone with access can expose bad things |
| well-defined patch cadence | patch management decentralized |
NoSQL problem
NoSQL solutions were never intended for internet exposure
BUT (naturally) peoples exposed them to internet.
Hunting NoSql Compromise in Azure
Port scans are slow and each NoSQL solution runs on different ports.
The author used shodan:
- rich metadata for each IP
- DB names are indexed
- JSON export allows for automated hunting
The code was added to shodan in dec 2017 but requires shodan enterprise api access.
Network Security Group
Network Security Group is the VM firewall.
- Configurable during deployment (optional)
- 46% of images expose ports by default
- 96% expose more than management
Your Iaas security is your responsibility
Pass and Saas are shared responsibility
- Patches handled by Microsoft:
- sas 100% transparent for you
- paas requires configuration
Cloud marketplaces are supply chains
- supply chain attacks are increasingly common.
- cloud marketplaces are the next targets
- minimal validation of 3rs party images
- 3rd party iaas imaged are old
- average azure age 140 days
- average AWS Age: 717 days
2018 year of the cryptominer
- cryptomining is the new ransomware
- open s3 buckets are attacked
- any vulnerable system is a target
Disrupting the Kill Chain (by Vineet Bhatia)
What is this talk about:
- how to make the adversaries intrusion cost prohibitive.
- how to monitor and secure Windows 10 environments.
- how to recover from an intrusion.
Computer scientists at Lockheed-Martin corporation described a new “intrusion kill chain” framework; see KillChain.
PRE-ATT&CK: Adversarial Tactics, Techniques & Common Knowledge for Left-of-Exploit is a curated knowledge base and model for cyber adversary behavior, reflecting the various phases of an adversary’s lifecycle and the platforms they are known to target.
PRE-ATT&CK consists of 15 tactics and 151 techniques.
ATT&CK: Adversarial Tactics, Techniques, and Common Knowledge for Enterprise is an adversary model and framework for describing the actions an adversary may take to compromise and operate within an enterprise network. The model can be used to better characterize and describe post-compromise adversary behavior.
Summary of the adversary behavior:
- know when they are coming, use PRE-ATT&CK
- see them when they operate on your infrastructure, use ATT&CK.
- map their activities, use the “kill chain”.
Don’t jump directly to attacker remediation; If an adversary perceives you as hostile (e.g.: hacking back), they will react differently.
How to make intrusions cost prohibitive:
- reduce attack surface area.
- detect early and remediate swiftly.
- deceive, disrupt and deteriorate.
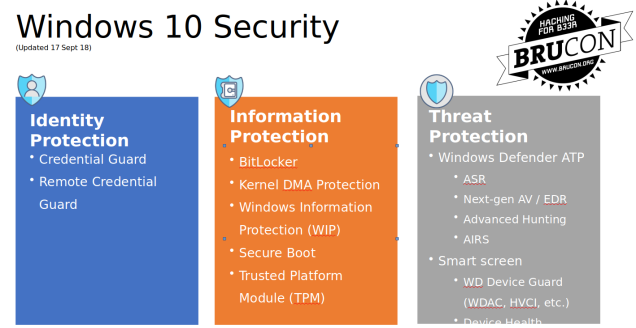
The rest of the talk was about the windows10 security:
Hunting Android Malware: A novel runtime technique for identifying malicious applications (by Christopher Leroy)
Malware is a constant threat to the Android ecosystem. How to protect from the malware:
- have to look to the APK file/s:
- statically
- or in a sandbox
- looking for:
- (code) signatures
- hashes
- permissions reputations
What are the shortcomings of the current detection techniques:
- static analysis is hard and it only can reveal a subset of the functionality.
- bypass the AV products is easy.
- cannot do forensics on realtime.
Idea: look to the application heap because the Android apps make us of objects. But the novelty is that should instrument the code before the execution:
- objects exist on the heap so they are accessible.
- trace calls and monitor the behavior.
- great way to gain insight into applications
The authors presented his own framework called UITKYK. Uitkyk is a framework that allows you to identify Android malware according to the instantiated objects on the heap for a specific Android process.
The framework is also integrates with Frida framework which is a “dynamic instrumentation toolkit for developers, reverse-engineers, and security researchers”.
Exploits in Wetware (by Robert Sell)
This was also a talk about social engineering. From my point of view it does not bring new things comparing to the talk “Social engineering for penetration testers” from previous day.
Dissecting Of Non-Malicious Artifacts: One IP At A Time (by Ido Naor and Dani Goland)
The talk was about how can find very valuable information that is uploaded (accidentally or not) on different public cloud services.
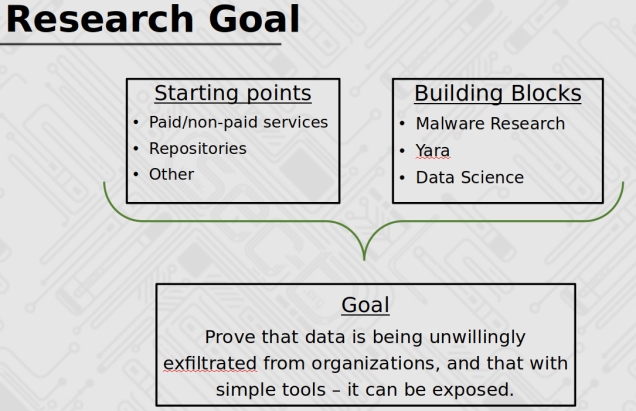
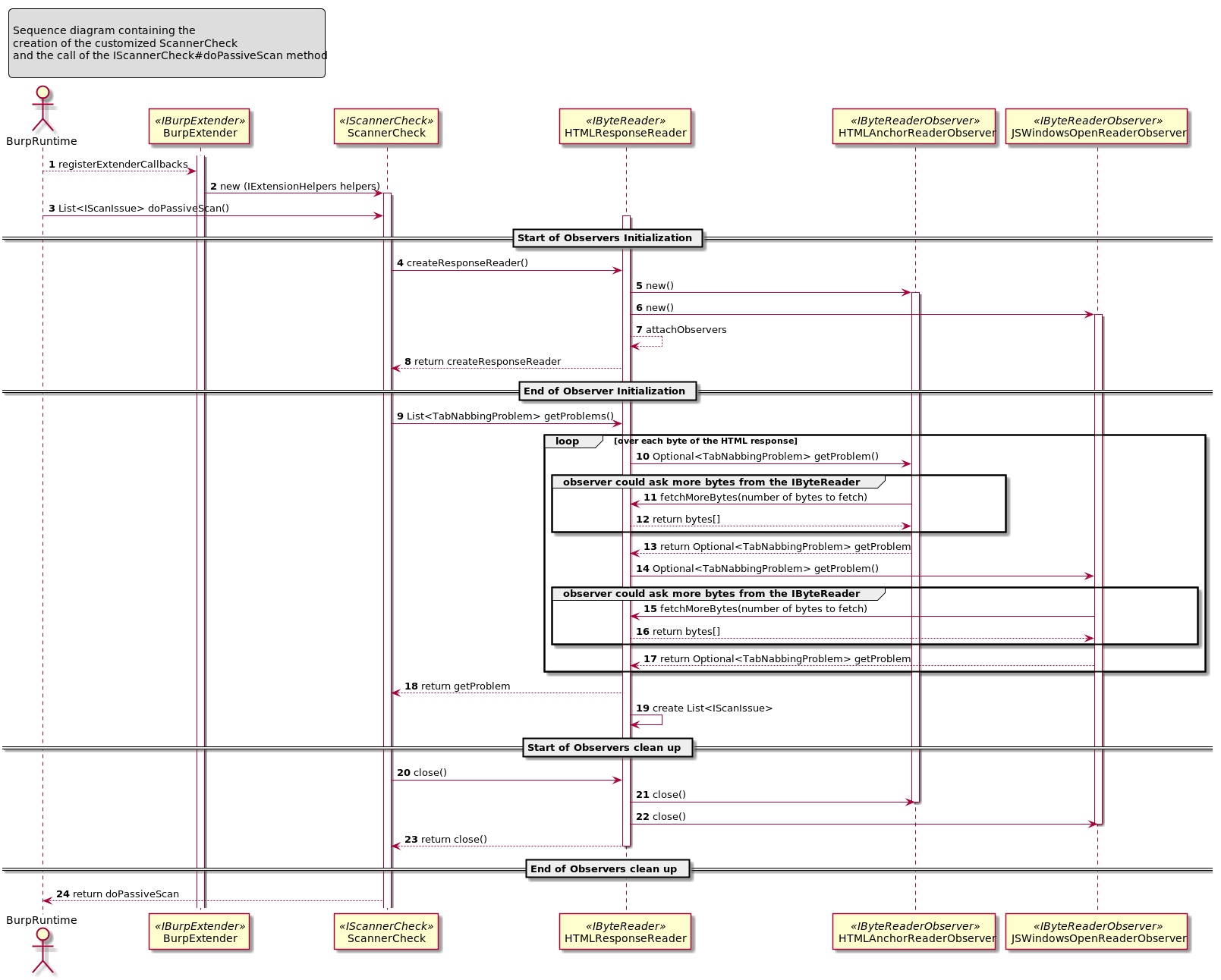
 The goal of this ticket is to explain how to create an extension for the Burp Suite Professional taking as implementation example the “Reverse Tabnabbing” attack.
The goal of this ticket is to explain how to create an extension for the Burp Suite Professional taking as implementation example the “Reverse Tabnabbing” attack.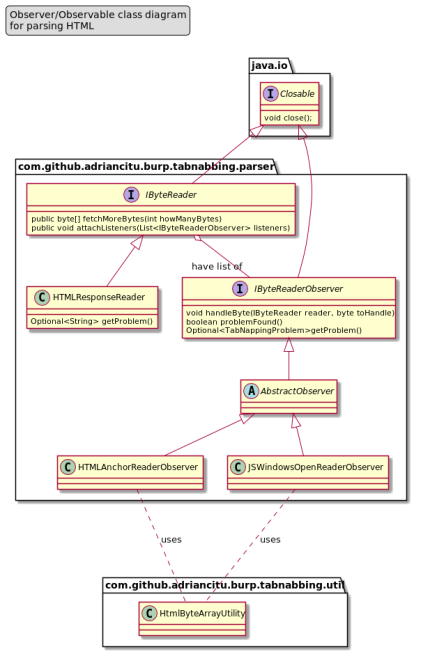


You must be logged in to post a comment.