This is a review of the third part of the Software Security: Building Security in book. This part is dedicated to how to introduce a software security program in your company; it’s something that I’m much less interested than the previous topics, so the review will be quite short.
Chapter 10: An Enterprise Software Security Program
The chapter contains some ideas about how to ignite a software security program in a company. The first and most important idea is the software security practices must have a clear and explicit connection with the with the business mission; the goal of (any) software is to fulfill the business needs.
In order to adopt a SDL (Secure Development Lifeycle) the author propose a roadmap of five steps:
Build a plan that is tailored for you. Starting from how the software is done in present, then plan the building blocks for the future change.
Roll out individual best practice initiatives carefully. Establish champions to take ownership of each initiative.
Train your people. Train the developers and (IT) architects to be aware of security and the central role that they play in the SDL (Secure Development Lifeycle).
Establish a metric program. In order to measure the progress some metrics a are needed.
Establish and sustain a continuous improvement capability. Create a situation in which continuous improvement can be sustained by measuring results and refocusing on the weakest aspect of the SDC.
Chapter 11: Knowledge for Software Security
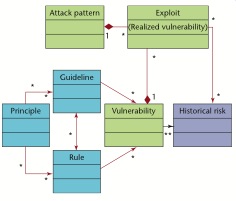
For the author there is a clear difference between the knowledge and the information; the knowledge is information in context, information put to work using processes and procedures. Because the knowledge is so important, the author prose a way to structure the software security knowledge called “Software Security Unified Knowledge Architecture” :
Software Security Unified Knowledge Architecture
The Software Security Unified Knowledge Architecture has seven catalogs in three categories:
category prescriptive knowledge includes three knowledge catalogs: principles, guidelines and rules. The principles represent high-level architectural principles, the rules can contains tactical low-level rules; the guidelines are in the middle of the two categories.
category diagnostic knowledge includes three knowledge catalogs: attack patterns, exploits and vulnerabilities. Vulnerabilities includes descriptions of software vulnerabilities, the exploits describe how instances of vulnerabilities are exploited and the attack patterns describe common sets of exploits in a form that can be applied acc
category historical knowledge includes the catalog historical risk.
Another initiative that is with mentioning is the Build Security In which is an initiative of Department of Homeland Security’s National Cyber Security Division.
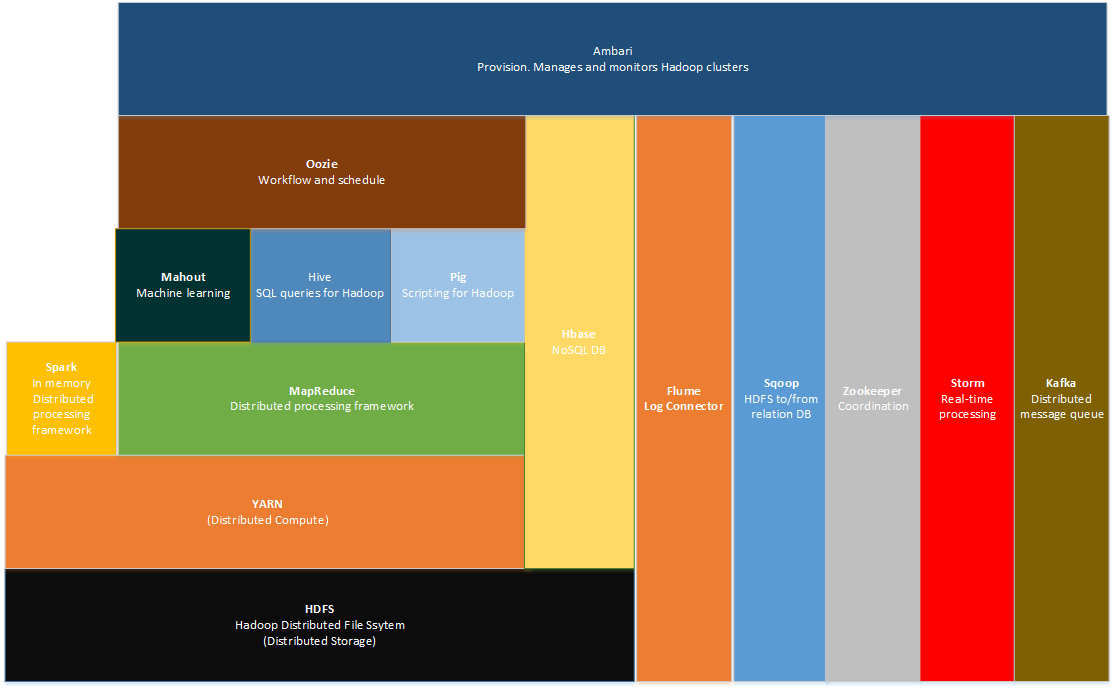
The goal of this ticket is to briefly present the most important components of the Apache Hadoop ecosystem.
Apache Hadoop – software library is a framework that allows for the distributed processing of large data sets across clusters of computers using simple programming models.
The overall picture of the Hadoop technology stack is the following one:
Apache Hadoop technology stack
Hadoop Distributed File System (HDFS)
A distributed file system that provides high-throughput access to application data.
Files are splitted and written in “blocks” across different cluster machines.
All files “blocks” are replicated to at least 3 nodes of the cluster.
Replication factor can be changed for each file or folder.
HDFS architecture follows the master-slave model
name node:
it handles the files metadatas, names, sizes, paths.
it knows on which date nodes each file “block” was written.
data node
it stores the data itself (file “blocks”) and have no concept of file.
the writing of a file follows the following workflow:
the client ask to the name node where it can write file/s.
data node it answers with a list of data nodes.
client writes the files to the data nodes.
the data nodes are taking care of the “blocks” replication.
YARN is moving the processes (usually Java classes) to the machine that stores the data that the process needs; this is the opposite comparing with what happens in the classical client-server architecture where the server sends the needed data to the process.
This architecture have the following advantages:
data can be processed on the node where it is stored.
the process capacity of the cluster is not restricted by the transfer capacity of the network.
Chapter 3: Introduction to Software Security Touchpoints
This is an introductory chapter for the second part of the book. A very brief description is made for every security touch point.
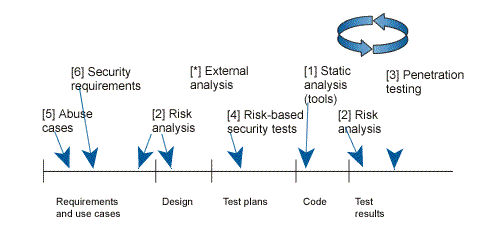
Each one of the touchpoints are applied on a specific artifact and each touchpoints represents either a destructive or constructive activity. Based on the author experience, the ideal order based on effectiveness in which the touch points should be implemented is the following one:
Another idea to mention that is worth mentioning is that the author propose to add the securty aspects as soon as possible in the software development cycle;moving left as much as possible (see the next figure that pictures the applicability of the touchpoints in the development cycle); for example it’s much better to integrate security in the requirements or architecture and design (using the risk analysis and abuse cases touchpoints) rather than waiting for the penetration testing to find the problems.
Security touchpoints
Chapter 4: Code review with a tool
For the author the code review is essential in finding security problems early in the process. The tools (the static analysis tools) can help the user to make a better job, but the user should also try to understand the output from the tool; it’s very important to not just expect that the tool will find all the security problems with no further analysis.
In the chapter a few tools (commercial or not) are named, like CQual, xg++, BOON, RATS, Fortify (which have his own paragraph) but the most important part is the list of key characteristics that a good analysis tool should have and some of the characteristics to avoid.
The key characteristics of a static analysis tool:
be designed for security
support multi tiers architecture
be extensible
be useful for security analysts and developers
support existing development processes
The key characteristics of a static analysis tool to avoid:
too many false positives
spotty integration with the IDE
single-minded support for C language
Chapter 5: Architectural Risk Analysis
Around 50% of the security problems are the result of design flows, so performing an architecture risk analysis at design level is an important part of a solid software security program.
In the beginning of the chapter the author present very briefly some existing security risk analysis methodologies: STRIDE (Microsoft), OCTAVE (Operational Critical Threat, Asset and Vulnerability Evaluation), COBIT (Control Objectives for Information and Related Technologies).
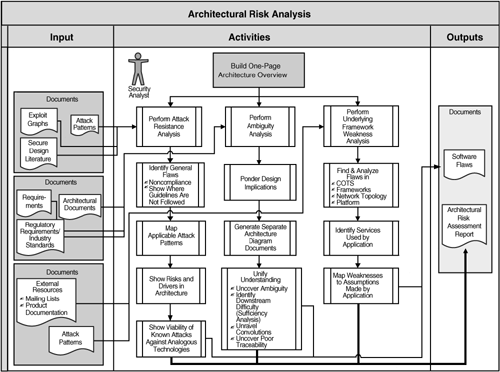
In the last part of the chapter the author present the Cigital way of making architectural risk analysis. The process has 3 steps:
attack resistance analysis – have as goal to define how the system should behave against known attacks.
ambiguity analysis – have as goal to discover new types of attacks or risks, so it relies heavily on the experience of the persons performing the analysis.
weakness analysis – have as goal to understand end asses the impact of external software dependencies.
Process diagram for architectural risk analysis
Chapter 6: Software Penetration Testing
The chapter starts by presenting how the penetration testing is done today. For the author, the penetration tests are misused and are used as a “feel-good exercise in pretend security”. The main problem is that the penetration tests results cannot guarantee that the system is secured after all the found vulnerabilities had been fixed and the findings are treated as a final list of issues to be fixed.
So, for the author the penetration tests are best suited to probing (live like) configuration problems and other environmental factors that deeply impact software security. Another idea is to use the architectural risk analysis as a driver for the penetration tests (the risk analysis could point to more weak part(s) of the system, or can give some attack angles). Another idea, is to treat the findings as a representative sample of faults in the system and all the findings should be incorporated back into the development cycle.
Chapter 7: Risk-Based Security Testing
Security testing should start as the feature or component/unit level and (as the penetration testing) should use the items from the architectural risk analysis to identify risks. Also the security testing should continue at system level and should be directed at properties of the integrated software system. Basically all the tests types that exist today (unit tests, integration tests) should also have a security component and a security mindset applied.
The security testing should involve two approaches:
functional security testing: testing security mechanism to ensure that their functionality is properly implemented (kind of white hat philosophy).
adversarial security testing: tests that are simulating the attacker’s approach (kind of black hat philosophy).
For the author the penetration tests represents a outside->in type of approach, the security testing represents an inside->out approach focusing on the software products “guts”.
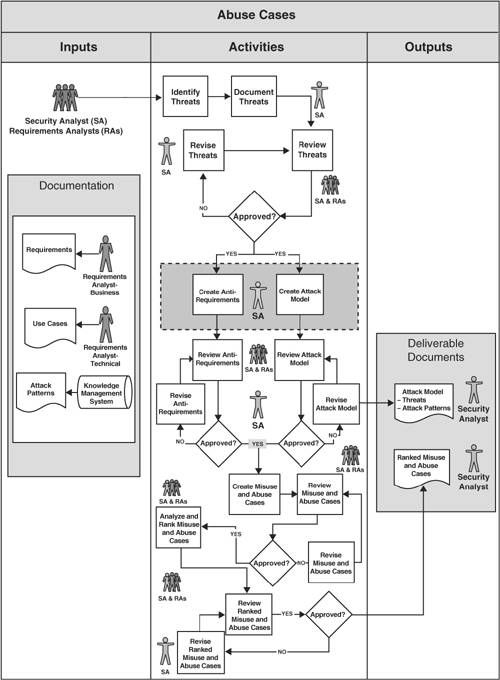
Chapter 8: Abuse Case Development
The abuse case development is done in the requirements phase and it is intimately linked to the requirements and use cases. The basic idea is that as we define requirements that suppose to express how the system should behave under a correct usage, we should also define how the system should behave if it’s abused.
This is the process that is proposed by the author to build abuse cases.
Diagram for building abuse cases
The abuse cases are creating using two sources, the anti-requirements (things that you don’t want your software to do) and attack models, which are known attacks or attack types that can apply to your system. Once they are done, the abuse cases can be used as entry point for security testing and especially for the architectural risk analysis.
The main idea is that the security operations peoples and software developers should work together and each category can (and should) learn from the other (category).
The security operation peoples have the security mindset and can use this mindset and their experience in some of the touchpoints presented previously; mainly abuse cased, security testing, architectural risk analysis and penetration testing.
This presentation was about how to educate the teenagers to be aware of the dangers installing cracked video games.
The first part of the presentation was an practical example of what a system containing cracked video games is doing in background:the system was connected to external IP addresses from different countries, various ports were open to the target machine, even an cloud hard drive data backup software it was silently operating.
The second part of the presentation was about a process that could be applied in order to reduce the risk of transforming the pc in a botnet client. This process implied:
the use of an intermediary pc on which a scan of the downloaded games could be done.
a virtual machine on which the Wireshark is installed. On this VM, the game could be eventually installed.
Top 10 privacy risks in web applications
The goal of this presentation was to present the OWASP Top 10 Privacy Risks Project which have as goal to identify the most important technical and organizational privacy risks for web applications and to propose some mitigations techniques.
The top 10 privacy risks:
Web Application Vulnerabilities
Operator-sided Data Leakage
Insufficient Data Breach Response
Insufficient Deletion of personal data
Non-transparent Policies, Terms and Conditions
Collection of data not required for the primary purpose
Sharing of data with third party
Outdated personal data
Missing or Insufficient Session Expiration
Insecure Data Transfer
LangSec meets State Machines
For me this presentation contained two separate and independent tracks.
The first track was around LANGSEC: Language-theoretic Security The LangSec idea (which sounds very appealing) is to treat all inputs of an applcation (valid or invalid) as a formal language. In this case then the input validation would be done using a a recognizer for that language.
LangSec principle: no more handwriter parsers but:
precisely defined input languages
generated parsers
complete parsing before processing
keep the input language simple & clear
The second track was around the use of state diagrams in order to detect security flows in different protocols (GSM, SSH). Lot of protocols have states and it is possible to compute the state machine of a protocol using a black box testing approach.
The Tales of a Bug Bounty Hunter
The author is participating to the Facebook Bug Bounty Program and the presentation was about the different security vulnerabilities found in the Instagram application. For each vulnerability, a detailed description was made.
The most surprising fact was that the impact of the vulnerabilities found was not at all linked to the time/effort spent to find the vulnerabilities :).
OWASP Secure Knowledge Framework (SKF)
The OWASP SKF is intended to be a tool that is used as a guide for building and verifying secure software.
Security knowledge reference (Code examples/ Knowledge Base items) in PHP and C# (not yet in Java)
Security as part of design with the pre-development functionality. The developer can choose the type of functionality taht he wants to implement and SKF will make a reports with all the security hints/infos that he should be aware.
Security post-development functionality for verification with the OWASP ASVS
The application is an web application and can be runned on local systems of developers or on a server.
Challenges in Android Malware Detection
A traditional way of malware detection:
collect suspicious samples
analyze the samples (usually manually)
extract the signature
A smarter solution could be that given a set of known malwares + known goodwares + use data mining techniques to detect unknown samples.
The main problem of this approach is that :
there are a few small sets of known malwares
there are no set of known goodwares
The conclusion is that is very difficult to build the wright set of malwares and goodwares so there is not possible to have an automatic malware detection process.
Serial Killer: Silently Pwning your Java Endpoints
This presentation is about the Java deserialization vulnerability. Tha authors explains how the vulnerability works, what products/frameworks are affected and also what are the possible mitigations. The best mitigations is to not use at all the serialization/deserialization process and/or replace it by JSON or XML.
The slides of this presentation can be found here.
Definition of threat modeling: activity of identifying and managing application threats. Threat Modeling should be ideally done on requirements phase of the project. The goal of threat modeling is to uncover flaws in the design of different features.
Threat modeling stages:
diagram
usually the Data Flow Diagrams are used.
different diagram layers
context diagram – very high level; entire component
rank the threats by risk, to be sure that you are focus on mitigating the most important ones.
how the STRIDE elements are applied to each element of the Data flow Diagram:
mitigate the threats
mitigation advice : keep it simple and do not reinvent the wheel.
leverage proven best practices
validate
does the diagram match final code ?
is each threat mitigated ?
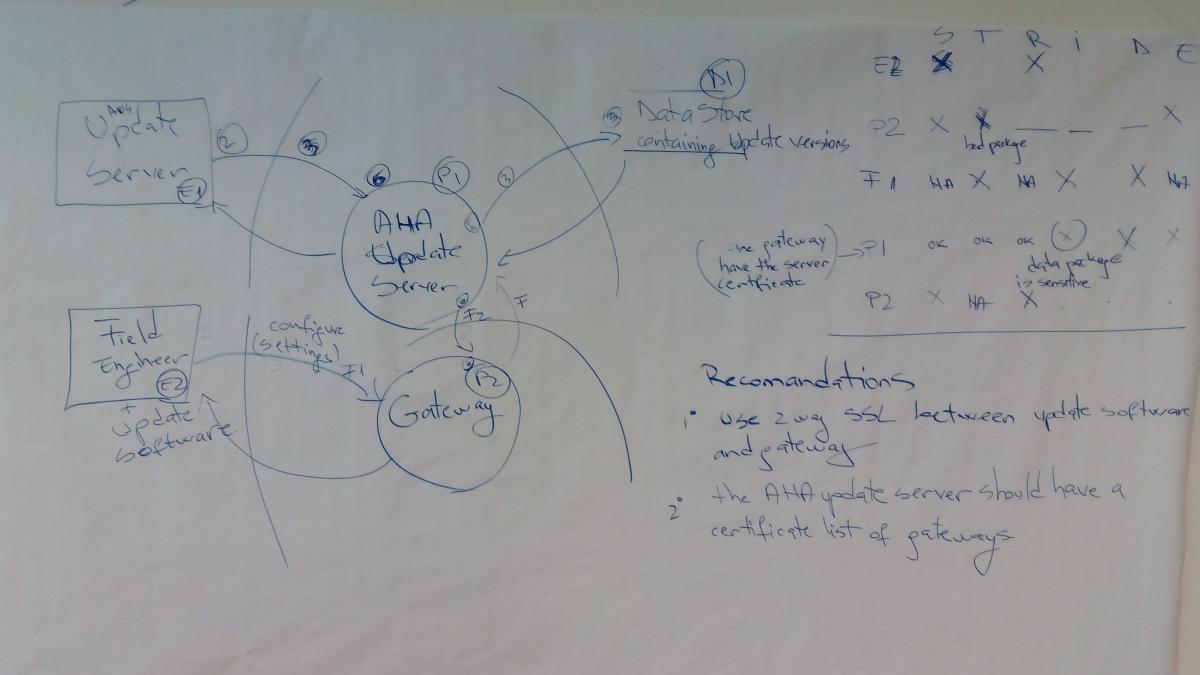
The training also had some hands-on exercises. I just upload here the last exercise representing the STRIDE analysis of an Internet of Things (IoT) deployment:




You must be logged in to post a comment.