This is a review of the first part of the Software Security: Building Security in book.
Chapter 1: Defining a discipline

This chapter lands out the landscape for the entire book; the author presents his view on the today challenges in having secure holes free software.
In the today world, the software is everywhere, from microwaves oven to nuclear power-stations, so the “old view” of seeing the software applications as “black boxes” than can be protected using firewalls and IDS/IPS it’s not valid anymore.
And just to make the problem even harder, the computing systems and the software applications are more and more interconnected must be extensible and have more and more complex features.
The author propose a taxonomy of the security problems that can be affected the software applications:
- defect: a defect is a problem that may lie dormant in software only to surface in a fielded system with major consequences.
- bug: an implementation-level software problem; only fairy simple implementations errors. A large panel of tools are capable to detect a range of implementation bugs.
- flaw: a problem at a deeper level; a flow is something that can be present at the code level but it can be also present or absent at the design level. What is very important to remark is that the automated technologies to detect design-level flows do not yet exist, through manual risk-analysis can identity flows.
- risk: flaws and bugs lead to risk. Risk capture the chance that a flaw or a bug will impact the purpose of a software.
In order to solve the problem of the software security, the author propose a cultural shift based on three pillars: applied risk management, software security touchpoints and knowledge.
Pillar 1 Applied Risk Management
For the author under the risk management names there 2 different parts; the application of risk analysis at the architectural level (also known as threat modeling or security design analysis or architectural risk analysis) and tracking and mitigating risks as a full life-cycle activity (the author call this approach, the risk management framework – RMF).
Pillar 2 Software security Touchpoints.
Touchpoint it’s just a fancy word for “best practices”. Today there are best practices for design and coding of software system and as the security became a property of a software system, then best practices should also be used to tackle the security problems.Here are the (seven) touch points and where exactly are applied in the development process.
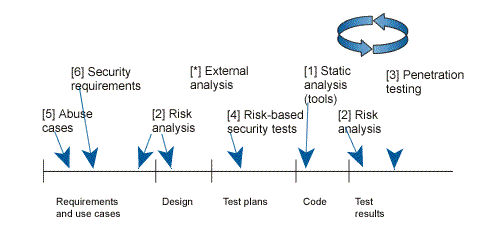
The idea is to introduce as deeply as possible the touch points in the development process. The part 2 of the book is dedicated to the touchpoints.
Pillar 3 Knowledge
For the author the knowledge management and training should play a central role in encapsulation and sharing the security knowledge.The software security knowledge can be organized into seven knowledge catalogs:
- principles
- guideline
- rules
- vulnerabilities
- exploits
- attack patterns
- historical risks
How to build the security knowledge is treated in the part 3 of the book.
Chapter 2: A risk management framework
This chapter presents in more details a framework to mitigate the risks as a full lifecycle activity; the author calls this framework the RMF (risk Management Framework).
The purpose of the RMF is to allow a consistent and repeatable expert-driven approach to risk management but the main goal is to find, rank, track and understand the software security risks and how these security risks can affect the critical business decisions.
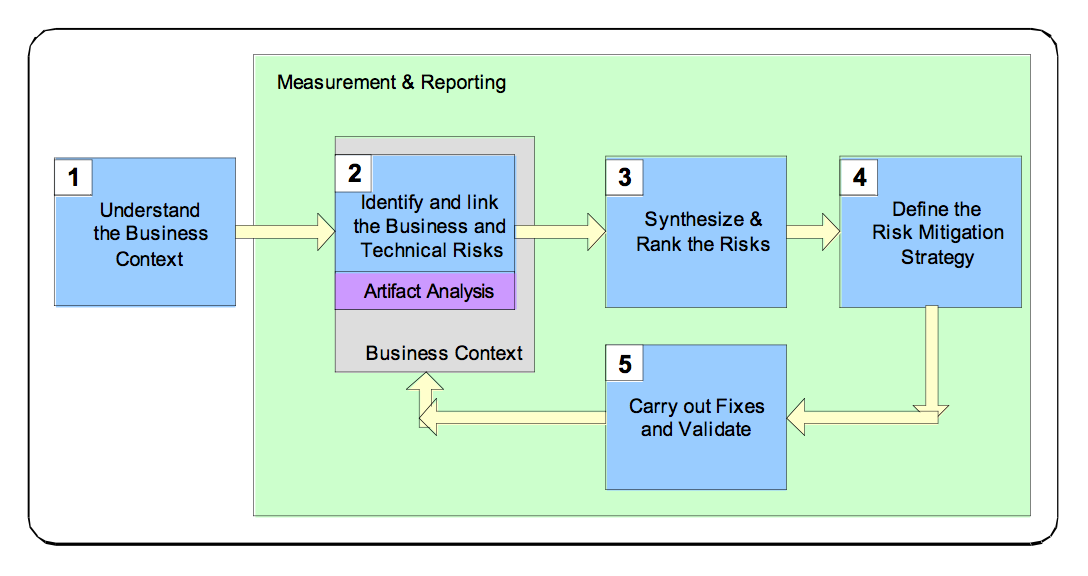
The RMF consists of five steps:
- understand the business context The goal of this step is describe the business goals in order to understand the types of software risks to care about.
- identify the business and technical risks. Business risk identification helps to define and steer the use of particular technological methods for measuring and mitigating software risk.The technical risks should be identified and mapped (through business risk) to business goals.
- synthesize and rank the risks. The ranking of the risks should take in account which business goals are the most important, which business goals are immediately threatened and how the technical risks will impact the business.
- define a risk mitigation strategy. Once the risks have been identified, the mitigation strategy should take into account cost, implementation time, likelihood of success and the impact
- carry out required fixes and validate that they are correct. This step represents the execution of the risk mitigation strategy; some metrics should be defined to measure the progress against risks, open risks remaining.
Even if the framework steps are presented sequentially, in practice the steps can overlap and can occur in parallel with standards software development activities. Actually the RMF can be applied at several different level; project level, software lifecycle phase level, requirement analysis, use case analysis level.



You must be logged in to post a comment.