CloudPiercer: Bypassing Cloud-based Security Providers (by Thomas Vissers, iMinds-DistriNet-KU Leuven)
The goal of the presentation was to show how the CBSP (Cloud Based Security Providers) are protecting the applications and how this protections can be circumvented.
The most common attacks on the web applications are the DDOS.
2 types of DDOS attacks:
volumetric attacks – no more network bandwidth
application level attacks – servers are targeted
How the CBSP are protecting the web application ?
CBSP reroute and filter the customer traffic through their cloud (see the following picture).
The secrecy of the origin server IP address is crucial because, (if discovered) the server can be hit directly and the CBSP protection is useless.
Vulnerabilities, or how the origin server IP can be found
subdomains – administrators can create a specific subdomain, such as origin.example.com, that directly resolves to the origin’s IP address; they need it in order to easily connect to the server for non http services (SSH, FTP)
dns records – other DNS records might still reveal your origin.; ex TXT records, MX records
SSL certificates – it concerns the https connection between CBSP and origin server. If an attacker is able to scan all IP addresses and retrieve all SSL certificates, he can find the IP addresses of hosts with certificates that are associated with the domain he is trying to expose.
IP history – companies constantly track DNS changes
sensitive files on the (target) web application; error messages, files containing IP information
outbound connections – force the origin to connect to you.
Defenses/what can i do to protect ?
request a new ip address when activating the CBSP.
block all non-CBSP requests with your firewall
choose a CBSB that assignes a dedicated IP address to you
I will start with the conclusion because it’s maybe the most important part of this review.
For me this is a must read book if you want to write more robust (web and non web) applications in Java, it covers a very large panel of topics from the basics of securing a web application using HTTP/S response headers to handling the encryption of sensitive informations in the right way.
Chapter 1: Web Application Security Basics
This chapter is an introduction to the security of web application and it can be split in 2 different types of items.
The first type of items is what I would call “low-hanging fruits” or how you could improve the security of your application with a very small effort:
The use of HTTP/S POST request method is advised over the use of HTTP/S GET. In the case of POST the parameters are embedded in the request body, so the parameters are not stored and visible in the browser history and if used over HTTPS are opaques to a possible attacker.
The use of the HTTP/S response headers:
Cache-Control – directive that instructs the browser how should cache the data.
X-Frame-Options – response header that can be used to indicate whether or not a browser should be allowed to render a page in a <frame>, <iframe> or <object> . Sites can use this to avoid clickjacking attacks, by ensuring that their content is not embedded into other sites.
X-XSS-Protection – response header that can help stop some XSS atacks (this is implemented and recognized only by Microsoft IE products).
The second types of items are more complex topics like the input validation and security controls. For this items the authors just scratch the surface because all of this items will be treated in more details in the future chapters of the book.
Chapter 2: Authentication and Session Management
This chapter is about how a secure authentication feature should work; under the authentication topic is included the login process, session management, password storage and the identity federation.
The first part is presenting the general workflow of login and session management (see next picture) and for every step of the workflow some dos and don’t are described.
login and session management workflow
The second part of the chapter is about common attacks on the authentication and for each kind of attack a solution to mitigated is also presented. This part of the chapter is strongly inspired from the OWASP Session Management Cheat Sheet which is rather normal because one of the authors (Jim Manico) is the project manager of the OWASP Cheat Sheet Series.
Even if you are not implementing an authentication framework for you application, you could still find good advices that can be applied to other web applications; like the use of the use of the secured and http-only attributes for cookies and the increase of the session ID length.
Chapter 3: Access Control
The chapter is about the advantages and pitfalls of implementing an authorization framework and can be split in three parts.
The first part describes the goal of an authorization framework and defines some core terms:
subject : the service making the request
subject attributes : the attributes that defines the service making the request.
group : basic organizational structure
role : a functional abstraction that uniquely describe system collaborators with similar or unique duties.
object : data being operating on.
object attributes : the attributes that defines the type of object being operating on.
access control rules : decision that need to be made to determine if a subject is allowed to access an object.
policy enforcement point : the place in code where the access control check is made.
policy decision point : the engine that takes the subject, subject attributes, object, object attributes and evaluates them to make an access control decision.
policy administration point : administrative entry in the access control system.
The second part of the chapter describes some access control (positive) patterns and anti-patterns.
Some of the (positive) access control patterns: have a centralized policy enforcement point and policy decision point (not spread through the entire code), all the authorization decisions should be taken on server-side only (never trust the client), the changes in the access control rules should be done dynamically (should not be necessary to recompile or restart/redeploy the application).
For the anti-patterns, some of then are just opposite of the (positive) patterns : hard-coded policy (opposite of “changes in the access control rules should be done dynamically”), adding the access control manually to every endpoint (opposite of have a centralized policy enforcement point and policy decision point)
Others anti-patterns are around the idea of never trusting the client: do not use request data to make access control policy decisions and fail open (the control access framework should cope with wrong or missing parameters coming from the client).
The third part of the chapter is about different approaches (actually two) to implement an access control framework. The most used approach is RBAC (Role Based Access Control) and is implemented by some well knows Java access control frameworks like Apache Shiro and Spring Security. The most important limitation of RBAC is the difficulty of implementing data-specific/contextual access control. The use of ABAC (Attribute Based Access Control) paradigm can solve the data-specific/contextual access control but there are no mature frameworks on the market implementing this.
Chapter 4: Cross-Site Scripting Defense
This chapter is about the most common vulnerability found across the web and have two parts; the presentation of different types of cross-site scripting (XSS) and the way to defend against it.
XSS is a type of attack that consists in including untrusted data into the victim (web) browser. There are three types of XSS:
reflected XSS (non persistent) – the attacker tampers the HTTP request to submit malicious JavaScript code.Reflected attacks are delivered to victims via e-mail messages, or on some other web site. When a user clicks on a malicious link, submitting a specially crafted form the injected code travels to the vulnerable web site, which reflects the attack back to the user’s browser. The browser then executes the code because it came from a “trusted” server.
stored XSS (persistent XSS) – the malicious script is stored on the server hosting the vulnerable web application (usually in the database) and it is served later to other users of the web application when the users are loading the vulnerable page. In this case the victim does not require to take any attacker-initiated action.
DOM-based XSS – the attack payload is executed as a result of modifying the DOM “environment” in the victim’s browser.
For the defense techniques the big picture is that the input validation and output encoding should fix (almost) all the problems but very often various factors needs to be considered when deciding the defense technique.
Chapter 5: Cross-Site Request Forgery Defense and Clickjacking
The chapter dedicated to the Cross-Site Request Forgery (CSRF) have the same structure as the previous chapter (dedicated to the XSS); the first part defines the CSRF and how it works and the second part defines mitigations strategies.
CSRF is an attack that can be used to force the victim to trigger unwanted actions on a web application in which they’re currently authenticated.
CSRF and XSS can be related in the sense that a XSS vulnerability could be used in order to embed a CSRF attack in the victim web site but most importantly a XSS vulnerability can be used to avoid the CSRF defenses; XSS can be used to read any (CSRF) tokens from any page or a XSS vulneariblity can be used to access cookies not having the HTTPOnly flag.
The following mitigations techniques are presented:
synchronizer token pattern – an anti-CSRF token is created and stored in the user session and in a hidden field on subsequent form submits. At every submit the server checks the token from the session matches the one submitted from the form. Tomcat 6+ implements this pattern; for more infos please see CSRF Protection Filter.
double-cookie submit pattern – when a user authenticates to a site, the site should generate a (cryptographically strong) pseudo-random value and set it as a cookie on the user’s machine separate from the session id. The site does not have to save this value in any way, thus avoiding server side state. The site then requires that every transaction request include this random value as a hidden form value (or other request parameter). A cross origin attacker cannot read any data sent from the server or modify cookie values, per the same-origin policy. The AngularJS framework implements this pattern out of the box; see Cross Site Request Forgery (XSRF) Protection
challenge/response pattern – the solution consists in forcing the user a value known only to him in order to complete the action.
Chapter 6: Protecting Sensitive Data
This chapter is articulated around three topics; how to protect (sensitive) data in transit, how to protect (sensitive) data at rest and the generation of secure random numbers.
How to protect the data in transit
The standard way to protect data in transit is by use of cryptographic protocol Transport Layer Security (TLS). In the case of web applications all the low level details are handled by the web server/application server and by the client browser but if you need a secure communications channel programmatically you can use the Java Secure Sockets Extension (JSSE). The authors recommendations for the cipher suites is to use the JSSE defaults.
Another topic treated by the authors is about the certificate and key management in Java. The notions of trustore and keystore are very well explained and examples about how to use the keytool tool are provided. Last but not least examples about how to manipulate the trustores and keystores programmatically are also provided.
How to protect data at rest
The goal is how to securely store the data but in a reversible way, so the data must be wrapped in protection when is stored and the protection must be unwrapped later when it is used.
For this kind of scenarios, the authors are focusing on Keyczar which is a (open source) framework created by Google Security Team having as goal to make it easier and safer the use cryptography for the developers. The developers should not be able to inadvertently expose key material, use weak key lengths or deprecated algorithms, or improperly use cryptographic modes.
Examples are provided about how to use Keyczar for encryption (symmetric and asymmetric) and for signing purposes.
Generation of secure random numbers
Last topic of the chapter is about the Java support for the generation of secure random numbers like the optimal way of using the java.security.SecureRandom (knowing that the implementation depends on the underlying platform) and the new cryptographic features of Java8 (enhance of the revocation certificate checking, TLS Server name indication extension).
Chapter 7: SQL Injection and other injection attacks
This chapter is dedicated to the injections attacks; the sql injection being treated in more details that the other types of injection.
SQL injection
The sql injection mechanism and the usual defenses are very well explained. What is interesting is that the authors are proposing solutions to limit the impact of SQL injections when the “classical” solution of query parametrization cannot be applied (in the case of legacy applications for example): the use of input validation, the use of database permissions and the verification of the number of results.
Other types of injections
XML injection, JSON-Based injection and command injection are very briefly presented and the main takeaways are the following ones:
use a safe parser (like JSON.parse) when parsing untrusted JSON
when received untrusted XML, an XML schema should be applied to ensure proper XML structure.
when XML query language (XPath) is intermixed with untrusted data, query parametrization or encoding is necessary.
Chapter 8: Safe File Upload and File I/O
The chapter speaks about how to safety treat files coming from external sources and to protect against attacks like file path injection, null byte injection, quota overloaded Dos.
The main takeaways are the following ones: validate the filenames (reject filenames containing dangerous characters like “/” or “\”), setting a per-user upload quota, save the file to a non-accessible directory, create a filename reference map to link the actual file name to a machine generated name and use this generated file name.
Chapter 9: Logging, Error Handling and Intrusion Detection
Logging
What should be be logged: what happened, who did it, when it happened, what data have been modified, and what should not be logged: sensitive information like sessions IDs, personal informations.
Some logging frameworks for security are presented like OWASP ESAPI Logging and Logback. If you are interested in more details about the security logging you can check OWASP Logging Cheat Sheet.
Error Handling
On the error handling the main idea is to not leak to the external world stacktraces that could give valuable information about your application/infrastructure to an attacker. It is possible to prevent this by registering to the application level static pages for each type of error code or by exception type.
Intrusion Detection
The last part of the chapter is about techniques to help monitor end detect and defend against different types of attacks. Besides the “craft yourself” solutions, the authors also re presenting the OWASP AppSensor application.
Chapter 10: Secure Software Development Lifecycle
The last chapter is about the SSDLC (Secure Software Development Life Cycle) and how the security could be included in each steps of development cycle. For me this chapter is not the best one but if you are interested about this topic I highly recommend the Software Security: Building Security in book (you can read my own review of the book here, here and here).
A few months ago (during BeneLux OWASP Days 2016) I’ve seen a presentation of the OWASP Security Knowledge Framework. I found the presentation very interesting so I decided to dig a little bit to learn more about OWASP Security Knowledge Framework a.k.a SKF. I found the official documentation a little bit sparse so after playing with SKF a few days I decided to write on paper what I have learned.
Introduction
SKF is a tools that helps the software developers to ease the integration of security into SDLC (Software Development Lifecycle). For the end-user, SKF can be used as web application which can be accessed after creating an account.
SKF web site have deployed a demo application, that can be accessed here SKF demo site (the username is admin and the password is test-skf. (be aware that the site content is scratched every hour).
Installation
If you want to install SKF in-house, then you can follow the installation instructions (installation instructions under Ubuntu, MacOS and Windows are provided and also Chef and AWS). Another installation option would be to use Docker; in this case you could use the following Docker image that I created. (the image is based on Ubuntu 14.04 64 bits version).
Once the application is running (in the case of Ubuntu manual installation it will run over HTTPS on port 5443) you have to unlock the default admin account (I will speak later about user and group management in SKF). This procedure is described in First run page; what is important to note is that on the “first login” page you must use the pincode 1234 and the email [email protected] (these values are hard-coded).
introduction of the security requirements in the SDLC.
The knowledge base
The SKF knowledge base contains the descriptions and the solutions to over 200 vulnerabilities, attacks and security best practices: API responses security headers, Access Control patterns, Command injection and many, many more.
The code examples
SKF also contains a few dozens of code examples of best practices to write secure code; the examples are written in PHP and C# languages.
Security Checklists
SKF offers also the possibility to create projects and users, the idea being that the users can be part of one or more projects and each project can contains a list of security checklists and security requirements.
The admin user (the user that have been unlocked after the installation) can create projects and users. For the user creation, a unique pincode is generated and the new user need to use this pincode the first time when he connects to the application.
The security checklists are representing a way to testing web application technical security controls and also provides developers with a list of requirements for secure development. SKF uses the OWASP Application Security Verification Standard (ASVS) checklists. SKF shows the checklists in a very user friendly way and the checklists can be customized in case your project have special security requirements. It is possible to add as many checklists as wanted end every checklists can be downloaded as a .docx document.
The OWASP ASVS contains the following verification criteria:
Architecture, design ant threat modeling.
Authentication.
Session management.
Access control.
Malicious input handling.
Cryptography at rest.
Error handling and logging.
Data protection.
Communications.
HTTP security configuration.
Malicious controls.
Business logic.
Files and resources.
Mobile
Web services
Configuration
Security requirements
For me, the most interesting feature of the SFK is the ability to create and attach to each project multiple items called functions. The basic idea is that the user can choose from a list of security requirements depending of the feature that should be implemented; for example you if for implementing a new feature, an eternal library will be used then you can add as security requirement the “third party software” function. Each security requirement contains a description and a solution about how to be handled.
The OWASP SKF contains the following security requirements:
third party software
sub-domains
Access controls or Login systems
User registration
Form
Sessions
Password forget functions
Forward or redirect
GET variables or parameters
XML files
File Download
File upload
Regular expressions
Eval type functions
Private user data
System commands
SSI commands
XSLT input and output
HTTP headers
LDAP commands
User-input in HTML output
X-Path
File inclusion
Path or Filename
SQL commands
(My) Conclusion
What I like about OWASP SKF is that it tries to introduce the secure coding practices into the SDLC in a easy and customizable way; ideally you should use all the features of the SKF but it’s up to each team/project to choose how SKF could help to have a more secure code.
On the negative side I would have the following remarks:
the application looks unstable; very often I have “Internal server error” on my Docker instance.
the code examples for Java are in the “Coming Soon” status for the last (at least) 8 months; maybe should be removed to not set-up unreasonable expectations.
I (personally) do not appreciate the ergonomy of the user interface; the actions linked projects (project creation, results) are mixed with the user management actions (user and group creation) and with other actions which are independent of projects and groups (code examples and knowledge base). As a new user I was very confused and I didn’t understood right away that the 4 SKF features can be used independently.
This is a review of the third part of the Software Security: Building Security in book. This part is dedicated to how to introduce a software security program in your company; it’s something that I’m much less interested than the previous topics, so the review will be quite short.
Chapter 10: An Enterprise Software Security Program
The chapter contains some ideas about how to ignite a software security program in a company. The first and most important idea is the software security practices must have a clear and explicit connection with the with the business mission; the goal of (any) software is to fulfill the business needs.
In order to adopt a SDL (Secure Development Lifeycle) the author propose a roadmap of five steps:
Build a plan that is tailored for you. Starting from how the software is done in present, then plan the building blocks for the future change.
Roll out individual best practice initiatives carefully. Establish champions to take ownership of each initiative.
Train your people. Train the developers and (IT) architects to be aware of security and the central role that they play in the SDL (Secure Development Lifeycle).
Establish a metric program. In order to measure the progress some metrics a are needed.
Establish and sustain a continuous improvement capability. Create a situation in which continuous improvement can be sustained by measuring results and refocusing on the weakest aspect of the SDC.
Chapter 11: Knowledge for Software Security
For the author there is a clear difference between the knowledge and the information; the knowledge is information in context, information put to work using processes and procedures. Because the knowledge is so important, the author prose a way to structure the software security knowledge called “Software Security Unified Knowledge Architecture” :
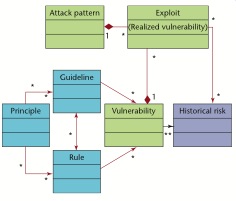
Software Security Unified Knowledge Architecture
The Software Security Unified Knowledge Architecture has seven catalogs in three categories:
category prescriptive knowledge includes three knowledge catalogs: principles, guidelines and rules. The principles represent high-level architectural principles, the rules can contains tactical low-level rules; the guidelines are in the middle of the two categories.
category diagnostic knowledge includes three knowledge catalogs: attack patterns, exploits and vulnerabilities. Vulnerabilities includes descriptions of software vulnerabilities, the exploits describe how instances of vulnerabilities are exploited and the attack patterns describe common sets of exploits in a form that can be applied acc
category historical knowledge includes the catalog historical risk.
Another initiative that is with mentioning is the Build Security In which is an initiative of Department of Homeland Security’s National Cyber Security Division.
Chapter 3: Introduction to Software Security Touchpoints
This is an introductory chapter for the second part of the book. A very brief description is made for every security touch point.
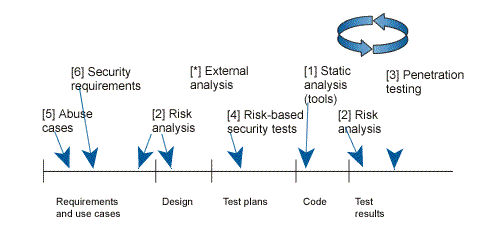
Each one of the touchpoints are applied on a specific artifact and each touchpoints represents either a destructive or constructive activity. Based on the author experience, the ideal order based on effectiveness in which the touch points should be implemented is the following one:
Another idea to mention that is worth mentioning is that the author propose to add the securty aspects as soon as possible in the software development cycle;moving left as much as possible (see the next figure that pictures the applicability of the touchpoints in the development cycle); for example it’s much better to integrate security in the requirements or architecture and design (using the risk analysis and abuse cases touchpoints) rather than waiting for the penetration testing to find the problems.
Security touchpoints
Chapter 4: Code review with a tool
For the author the code review is essential in finding security problems early in the process. The tools (the static analysis tools) can help the user to make a better job, but the user should also try to understand the output from the tool; it’s very important to not just expect that the tool will find all the security problems with no further analysis.
In the chapter a few tools (commercial or not) are named, like CQual, xg++, BOON, RATS, Fortify (which have his own paragraph) but the most important part is the list of key characteristics that a good analysis tool should have and some of the characteristics to avoid.
The key characteristics of a static analysis tool:
be designed for security
support multi tiers architecture
be extensible
be useful for security analysts and developers
support existing development processes
The key characteristics of a static analysis tool to avoid:
too many false positives
spotty integration with the IDE
single-minded support for C language
Chapter 5: Architectural Risk Analysis
Around 50% of the security problems are the result of design flows, so performing an architecture risk analysis at design level is an important part of a solid software security program.
In the beginning of the chapter the author present very briefly some existing security risk analysis methodologies: STRIDE (Microsoft), OCTAVE (Operational Critical Threat, Asset and Vulnerability Evaluation), COBIT (Control Objectives for Information and Related Technologies).
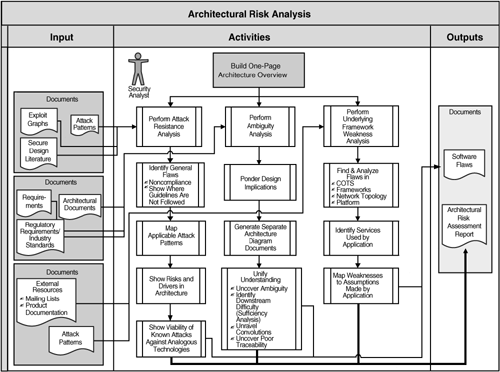
In the last part of the chapter the author present the Cigital way of making architectural risk analysis. The process has 3 steps:
attack resistance analysis – have as goal to define how the system should behave against known attacks.
ambiguity analysis – have as goal to discover new types of attacks or risks, so it relies heavily on the experience of the persons performing the analysis.
weakness analysis – have as goal to understand end asses the impact of external software dependencies.
Process diagram for architectural risk analysis
Chapter 6: Software Penetration Testing
The chapter starts by presenting how the penetration testing is done today. For the author, the penetration tests are misused and are used as a “feel-good exercise in pretend security”. The main problem is that the penetration tests results cannot guarantee that the system is secured after all the found vulnerabilities had been fixed and the findings are treated as a final list of issues to be fixed.
So, for the author the penetration tests are best suited to probing (live like) configuration problems and other environmental factors that deeply impact software security. Another idea is to use the architectural risk analysis as a driver for the penetration tests (the risk analysis could point to more weak part(s) of the system, or can give some attack angles). Another idea, is to treat the findings as a representative sample of faults in the system and all the findings should be incorporated back into the development cycle.
Chapter 7: Risk-Based Security Testing
Security testing should start as the feature or component/unit level and (as the penetration testing) should use the items from the architectural risk analysis to identify risks. Also the security testing should continue at system level and should be directed at properties of the integrated software system. Basically all the tests types that exist today (unit tests, integration tests) should also have a security component and a security mindset applied.
The security testing should involve two approaches:
functional security testing: testing security mechanism to ensure that their functionality is properly implemented (kind of white hat philosophy).
adversarial security testing: tests that are simulating the attacker’s approach (kind of black hat philosophy).
For the author the penetration tests represents a outside->in type of approach, the security testing represents an inside->out approach focusing on the software products “guts”.
Chapter 8: Abuse Case Development
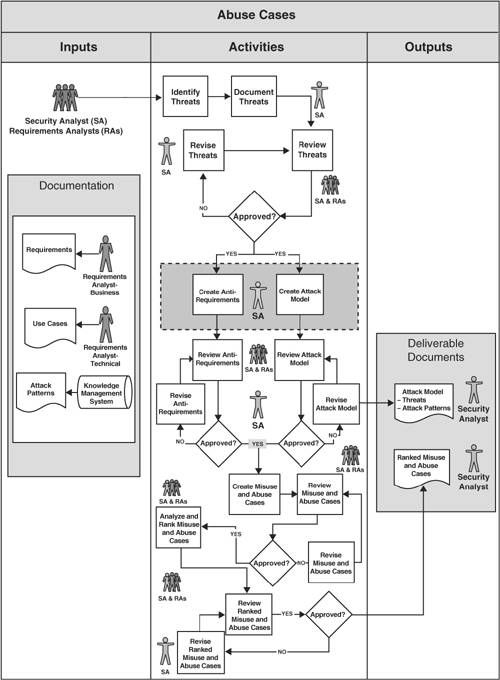
The abuse case development is done in the requirements phase and it is intimately linked to the requirements and use cases. The basic idea is that as we define requirements that suppose to express how the system should behave under a correct usage, we should also define how the system should behave if it’s abused.
This is the process that is proposed by the author to build abuse cases.
Diagram for building abuse cases
The abuse cases are creating using two sources, the anti-requirements (things that you don’t want your software to do) and attack models, which are known attacks or attack types that can apply to your system. Once they are done, the abuse cases can be used as entry point for security testing and especially for the architectural risk analysis.
The main idea is that the security operations peoples and software developers should work together and each category can (and should) learn from the other (category).
The security operation peoples have the security mindset and can use this mindset and their experience in some of the touchpoints presented previously; mainly abuse cased, security testing, architectural risk analysis and penetration testing.






You must be logged in to post a comment.