 This ticket was triggered by a “simple” requirement: “Change all the package names in the logs of a Java application (especially the stacktraces) from ‘abc.efg’ (put here whatever you want as name) to ‘hij.klm’ (put here also whatever you want as name) “. The first idea that popped in my mind was to change the packages names at the code level, but this was not feasible because of (rather) big codebase, the use of the (Java) reflexion and the tight timeline.
This ticket was triggered by a “simple” requirement: “Change all the package names in the logs of a Java application (especially the stacktraces) from ‘abc.efg’ (put here whatever you want as name) to ‘hij.klm’ (put here also whatever you want as name) “. The first idea that popped in my mind was to change the packages names at the code level, but this was not feasible because of (rather) big codebase, the use of the (Java) reflexion and the tight timeline.
In the following lines, I will discuss possible solutions to implement this (weird) requirement.
Extend the log4j ThrowableRenderer
If the project is using log4j1x as log library, then a solution would be to create your own throwable renderer by extending the org.apache.log4j.spi.ThrowableRenderer. The (log4j) renderers are used to render instances of java.lang.Throwable (exceptions and errors) into a string representation.
The custom renderer that replaces the packages starting with “org.github.cituadrian” by “xxx.yyy” will look like this:
package org.github.cituadrian.stacktraceinterceptor.log4j;
import org.apache.log4j.DefaultThrowableRenderer;
import org.apache.log4j.spi.ThrowableRenderer;
public class CustomThrowableRenderer implements ThrowableRenderer {
private final DefaultThrowableRenderer defaultRenderer =
new DefaultThrowableRenderer();
@Override
public String[] doRender(Throwable t) {
String[] initialResult = defaultRenderer.doRender(t);
for (int i = 0; i < initialResult.length; i++) {
String line = initialResult[i];
if (line.contains("org.github.cituadrian")) {
initialResult[i] = line.replaceAll("org.github.cituadrian", "xxx.yyy");
}
}
return initialResult;
}
}
Basically, the custom renderer is delegating the task of creating a String from a Throwable to a DefaultThrowableRenderer and then it checks and replace the desired package names.
In order to be used, the renderer should be defined in the log4j.xml file:
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE log4j:configuration SYSTEM "log4j.dtd">
<log4j:configuration debug="true"
xmlns:log4j='http://jakarta.apache.org/log4j/'>
<throwableRenderer class=
"org.github.cituadrian.stacktraceinterceptor.log4j.CustomThrowableRenderer"/>
...
Use a log4j2 pattern layout
If your project is using log4j2 as logging library, then you can use a (log4j2) layout pattern. The layout pattern will look like:
<?xml version="1.0" encoding="UTF-8"?>
<Configuration>
<Appenders>
<Console name="STDOUT" target="SYSTEM_OUT">
<PatternLayout pattern=
"%replace{%class %log %msg %ex}{org\.github\.cituadrian}{xxx\.yyy}"/>
</Console>
...
Modify (a.k.a. Weaving) the java.lang.StackTraceElement class with AOP
Before even explaining what it really means, I have to warn you that weaving JDK classes is rarely necessary (and usually a bad idea) even if it’s possible using an AOP framework like AspectJ.
For this case I used the AspectJ as AOP framwork because the weaver (aop compiler) is able to do binary weaving, meaning the weaver takes classes and aspects in .class form and weaves them together to produce binary-compatible .class files that run in any Java VM. The command line to obtain a weaved jar is the following one:
ajc -inpath rt.jar Aspect.java -outjar weavedrt.jar
In the case of weaving JDK classes one extra step is necessary in order to make the application work; we must create a new version of the rt.jar file or create just a small JAR file with the JDK woven classes which then must be appended to the boot-classpath of the JDK/JRE when firing up the target application. The command line to execute the target application is the following one:
java -Xbootclasspath/<path to weavedrt.jar>;<path to aspectjrt.jar> TargetApplication
If you don’t want to worry about all the technical details of weaving and executing the application and you are using Maven then you can use the (marvelous) SO_AJ_MavenWeaveJDK project from gitHub (that handles everything using Maven)
The aspect that will modify the stacktrace packages looks like:
package org.github.cituadrian.stacktraceinterceptor.app;
import org.aspectj.lang.ProceedingJoinPoint;
import org.aspectj.lang.annotation.Around;
import org.aspectj.lang.annotation.Aspect;
import org.aspectj.lang.annotation.Pointcut;
@Aspectpublic class StackTraceInterceptorAspect {
@Pointcut("execution(String java.lang.StackTraceElement.getClassName()) "
+ "&& !within(StackTraceInterceptorAspect)")
public void executeStackTraceElementGetClassNamePointcut() {}
@Around("executeStackTraceElementGetClassNamePointcut()")
public Object executeStackTraceElementGetClassNameAdvice(
final ProceedingJoinPoint pjp) throws Throwable {
Object initialResponse = pjp.proceed();
if (initialResponse instanceof String
&& ((String)initialResponse).startsWith("org.github.cituadrian")) {
return ((String)initialResponse).replaceFirst("org.github.cituadrian", "xxx.zzz");
}
return initialResponse;
}
}
In a nutshell, the StackTraceInterceptorAspect will intercept all the calls to the java.lang.StackTraceElement#getClassName method and it will change the returned result of the method if the class name contains the string “org.github.cituadrian”.
If you are interested to learn more about AspectJ I really recommend you to buy a copy of the AspectJ in action (second edition) book.
Modify and shadow the java.lang.StackTraceElement class
Using AOP just to intercept and modify a single method of a single class is a little bit over-killing. In this case there is another solution; the solution would be create a custom version of the java.lang.StackTraceElement class and add this custom class in the boot-classpath of the JDK/JRE when firing up the target application, so the initial version will be shadowed by the custom version.
An implementation of StacktraceElement class can be found here. So you can modify by hand the java.lang.StackTraceElement#getClassName method or the java.lang.StackTraceElement#toString method.
To execute the target application, you must create a jar with the modified class and add it into the boot-classpath (something similar to the AspectJ solution):
java -Xbootclasspath/<path to custom class.jar> TargetApplication

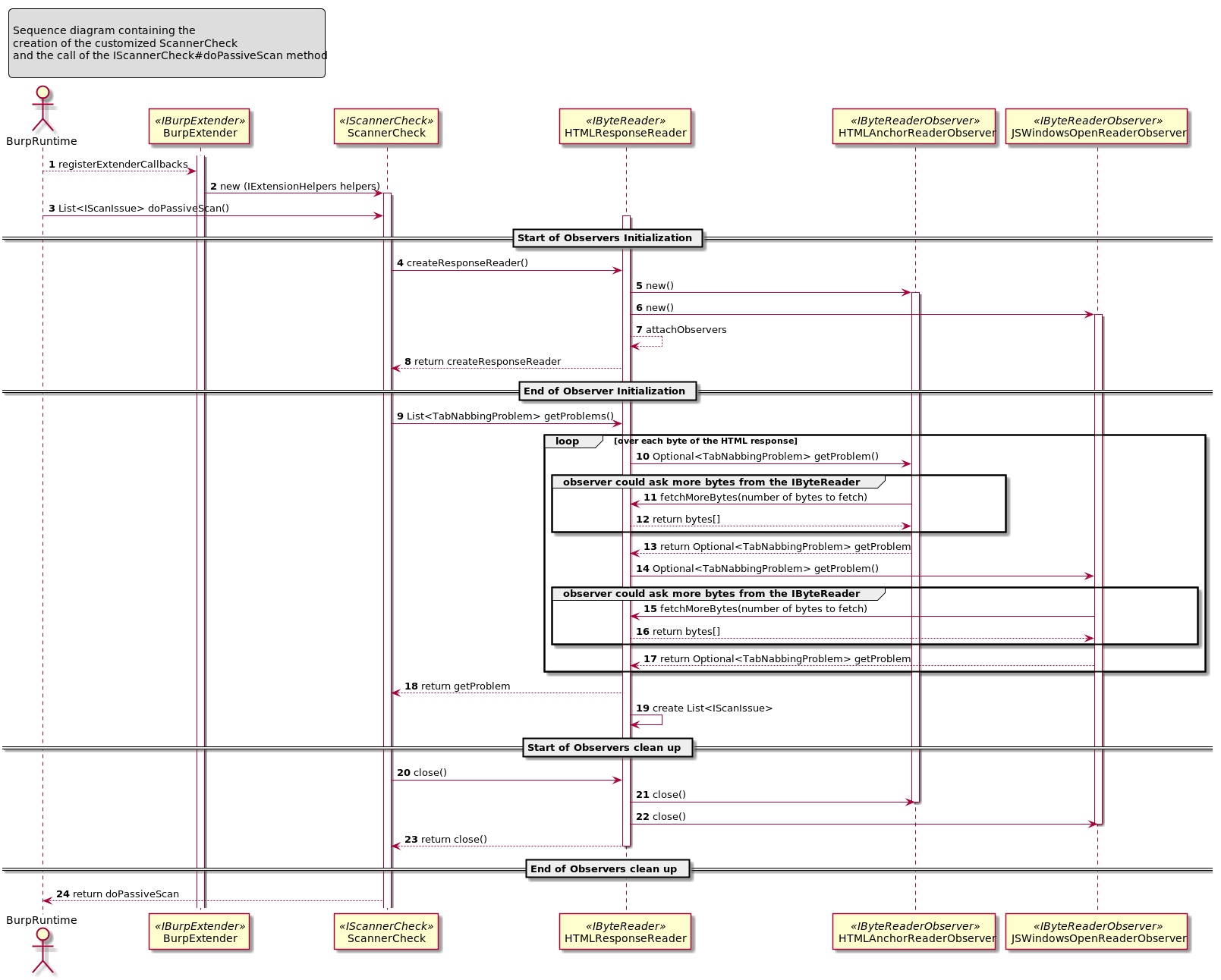
 The goal of this ticket is to explain how to create an extension for the Burp Suite Professional taking as implementation example the “Reverse Tabnabbing” attack.
The goal of this ticket is to explain how to create an extension for the Burp Suite Professional taking as implementation example the “Reverse Tabnabbing” attack.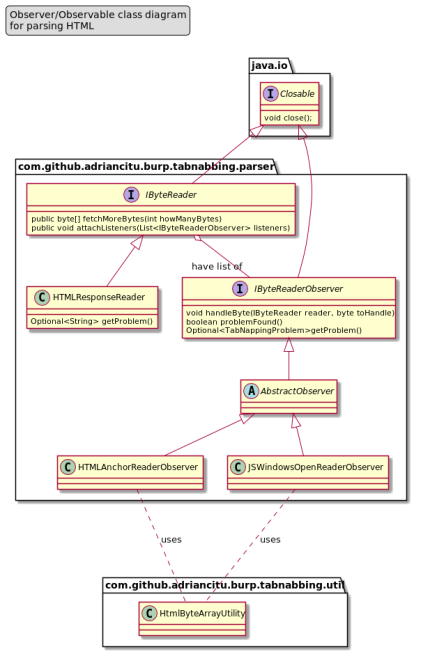








You must be logged in to post a comment.