Context and goal
 The goal of this ticket is to explain how to create an extension for the Burp Suite Professional taking as implementation example the “Reverse Tabnabbing” attack.
The goal of this ticket is to explain how to create an extension for the Burp Suite Professional taking as implementation example the “Reverse Tabnabbing” attack.
“Reverse Tabnabbing” is an attack where an (evil) page linked from the (victim) target page is able to rewrite that page, such as by replacing it with a phishing site. The cause of this attack is the capacity of a new opened page to act on parent page’s content or location.
For more details about the attack himself you can check the OWASP Reverse Tabnabbing.
The attack vectors are the HTML links and JavaScript window.open function so to mitigate the vulnerability you have to add the attribute value: rel="noopener noreferrer" to all the HTML links and for JavaScriptadd add the values noopener,noreferrer in the windowFeatures parameter of the window.openfunction. For more details about the mitigation please check the OWASP HTML Security Check.
Basic steps for (any Burp) extension writing
The first step is to add to create an empty (Java) project and add into your classpath the Burp Extensibility API (the javadoc of the API can be found here). If you are using Maven then the easiest way is to add this dependency into your pom.xml file:
<dependency>
<groupId>net.portswigger.burp.extender</groupId>
<artifactId>burp-extender-api</artifactId>
<version>LATEST</version>
</dependency>
Then the extension should contain a class called BurpExtender (into a package called burp) that should implement the IBurpExtender interface.
The IBurpExtender interface have only a single method (registerExtenderCallbacks) that is invoked by burp when the extension is loaded.
For more details about basics of extension writing you can read Writing your first Burp Suite extension from the PortSwigger website.
Extend the (Burp) scanner capabilities
In order to find the Tabnabbing vulnerability we must scan/parse the HTML responses (coming from the server), so the extension must extend the Burp scanner capabilities.
The interface that must be extended is IScannerCheck interface. The BurpExtender class (from the previous paragraph) must register the custom scanner, so the BurpExtender code will look something like this (where ScannerCheck is the class that extends the IScannerCheck interface):
public class BurpExtender implements IBurpExtender {
@Override
public void registerExtenderCallbacks(
final IBurpExtenderCallbacks iBurpExtenderCallbacks) {
// set our extension name
iBurpExtenderCallbacks.setExtensionName("(Reverse) Tabnabbing checks.");
// register the custom scanner
iBurpExtenderCallbacks.registerScannerCheck(
new ScannerCheck(iBurpExtenderCallbacks.getHelpers()));
}
}
Let’s look closer to the methods offered by the IScannerCheck interface:
- consolidateDuplicateIssues – this method is called by Burp engine to decide whether the issues found for the same url are duplicates.
- doActiveScan – this method is called by the scanner for each insertion point scanned. In the context of Tabnabbing extension this method will not be implemented.
- doPassiveScan – this method is invoked for each request/response pair that is scanned. The extension will implement this method to find the Tabnabbing vulnerability. The complete signature of the method is the following one: List<IScanIssue> doPassiveScan(IHttpRequestResponse baseRequestResponse). The method receives as parameter an IHttpRequestResponse instance which contains all the information about the HTTP request and HTTP response. In the context of the Tabnabbing extension we will need to check the HTTP response.
Parse the HTTP response and check for Tabnabbing vulnerability
As seen in the previous chapter the Burp runtime gives access to the HTTP requests and responses. In our case we will need to access the HTTP response using the method IHttpRequestResponse#getResponse. This method returns a byte array (byte[]) representing the HTTP response as HTML.
In order to find the Tabnabbing vulnerability we must parse the HTML represented by the HTML response. Unfortunately, there is nothing in the API offered by Burp for parsing HTML.
The most efficient solution that I found to parse HTML was to create few classes and interfaces that are implementing the observer pattern (see the next class diagram ):
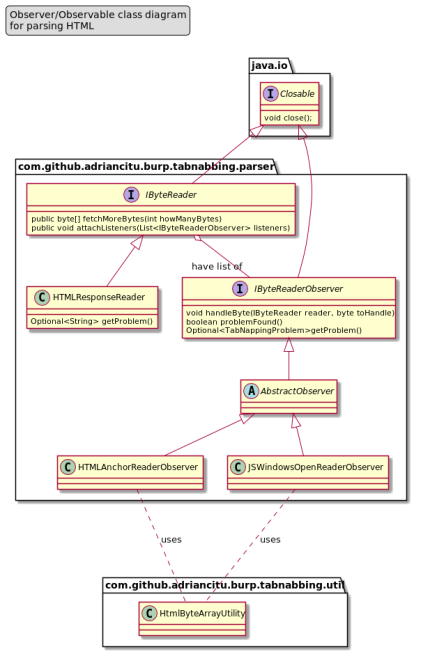
The most important elements are :
- IByteReader interface – this interface represents the Subject (or Observable) from the Observer pattern. This interface has methods for attach and notify the observers.
- HTMLResponseReader class – this class implements the IByteReader and for each byte of the HTML response will notify the attached observers. After each notification, the HTMLResponseReader will also ask each observer if they found a Tabnabbing problem (via IByteReaderObserver#problemFound method).
- IByteReaderObserver interface – this interface represents the Observer from the Observer pattern. The HTMLResponseReader will call the IByteReaderObserver#handleByte(reader, byte) for each byte from the HTML response. Each IByteReaderObserver implementation can call IByteReader#fetchMoreBytes(numberOfBytesToFetch) to fetch more bytes from the HTML byte array in advance if needed.
- HTMLAnchorReaderObserver class – this class implements the IByteReaderObserver interface and is capable to find the HTML anchor tag and check if it is vulnerable to Tabnabbing problem.
- JSWindowsOpenReaderObserver class – this class implements the IByteReaderObserver interface and is capable to find the
window.openfunction call and check if it is vulnerable to Tabnabbing problem.
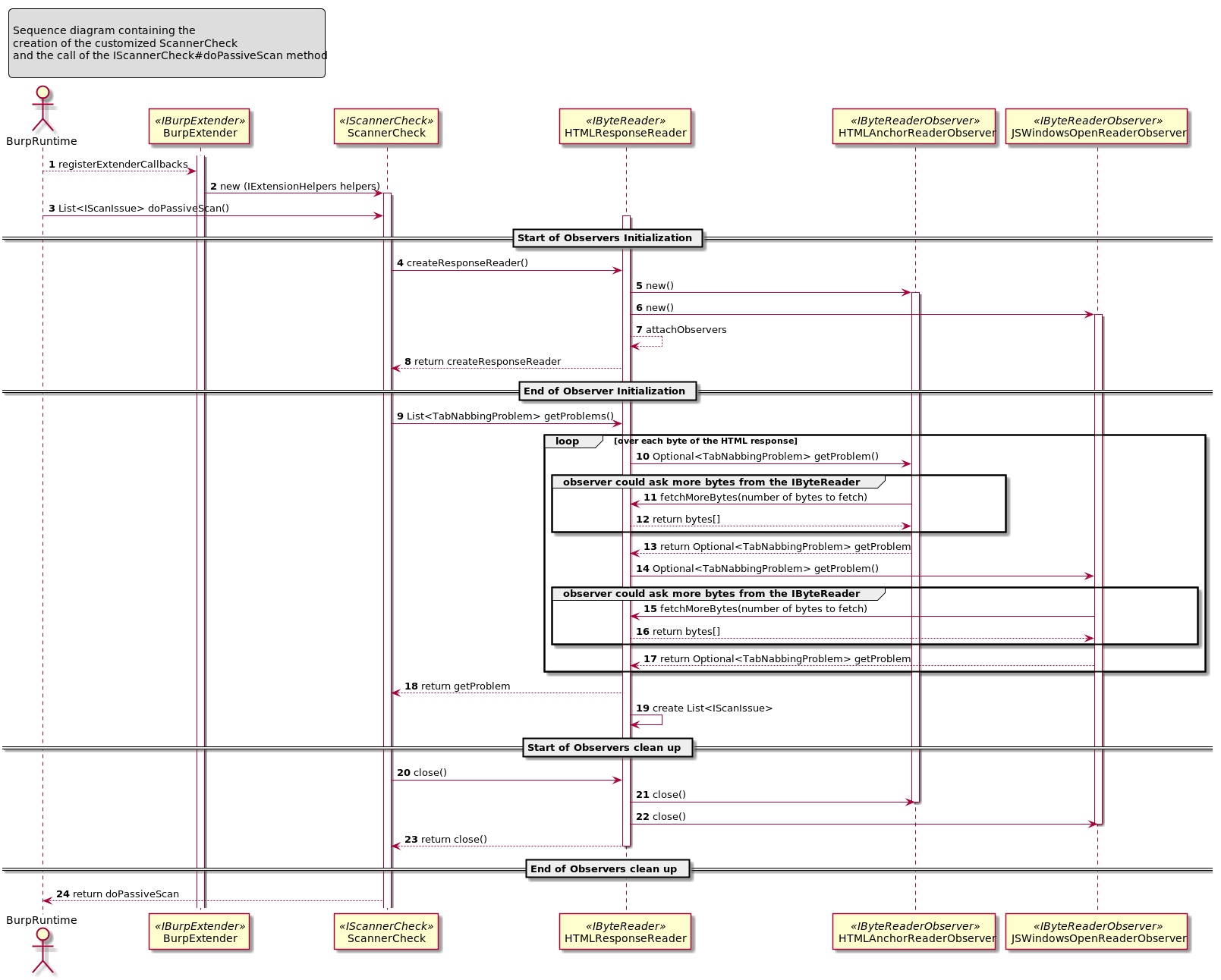
The following sequence diagram try to explains how the classes are interacting together in order to find the Tabnabbing vulnerability.
Final words
If you want to download the code or try the extension you can find all you need on github repository: tabnabbing-burp-extension.
If you are interested about some metrics about the code you can the sonarcloud.io: tabnnabing project.








You must be logged in to post a comment.