This is the review of the Clean Architecture (A Craftsman’s Guide to Software Structure and Design) book.
(My) Conclusion
I personally have mixed feelings about this book; the first 4 parts of the book that presents the paradigms and different design principles are quite good (for me it contains all the theory that you need in order to tackle the IT architectural problems). You start reading from the first chapter and gradually you build knowledge on top of previous chapter/s.
On the other side, the part 5 and 6 of the book (which are representing the backbone of the book) have a different cognitive structure; the chapters are not really linked together, you cannot read and build on top of previous chapter/s because there is no coherency between chapters (some of the chapters are extended versions of blog tickets from https://8thlight.com/blog/).
The book explains very well the rules and patterns to apply in order to build an application easy to extend and test but the subjects like the scalability, availability and security that are qualities that an (every) application should have, are not treated at all.
Part I Introduction
The author tries to express the fact that good software design and (good) software architecture are intimately linked and that is very important to invest time and resources in having a good software design even if it looks like the project it advances slower.
The quality of the (software) design will influence the overall quality of the software product and to prove this the author comes with some figures/numbers (unfortunately there are reference to the source of this figures).
Part II Starting with the bricks: Programming Paradigms
The following programming paradigms are explained: Structured Programming, Object Oriented Programming and Functional Programming.
For each paradigm a brief history is done and also the author expresses how each paradigm characteristics can help and impact the software architecture.
- the immutability characteristic of Functional Programming can help to simplify the design in respect of concurrency issues.
- the polymorhism characteristic of Object Oriented Programming can help the design to not care about the implementation details of the used components.
- the Structured Programming helped us to decompose a (big) problem in smaller problems that can be then handled independently.
Part III Design Principles
This part is about the SOLID design principles; each one of these design principles are clearly explained using sometimes UML diagrams. The solid design principles are (usually) applied by software developers to write clean(er) code but the author also explains how these principles can be applied to an architecture level:
- SRP (Single Responsabilty Principle) for a software developer is “A class should have only one reason to change.” but for an architect became “A module should be responsible to one, and only one author”.
- OCP (Open-Closed principle) is translated in architectural terms by replacing the classes with high level components the goal being to arrange those components into a hierarchy that protects higher-level components from changes in lower-level components.
- LSP (Liskov Substitution Principle) is translated in architectural terms by extending the interface concept from a programming language structure to gateways that different system components are using to communicate. The violation of substitutability of these gateways (interfaces) are causing the system architecture to be poluted.
- ISP (Interface Segregation Principle) is translated in architectural terms by stating that generally is harmful that your systems depends on frameworks that has more features that you need.
- DIP (Dependency Inversion Principle) is used to create architectural boundaries between different system components.
Part IV Component Principles
The components principles are categorized in two types: (component) cohesion and coupling.
The component cohesion principles are :
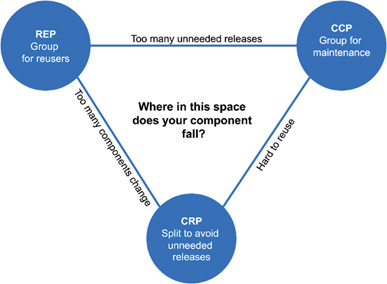
- (REP) The Reuse/Release Equivalence Principle : This principle states that “The unit of reuse is the unit of release”. Classes and modules that are formed into a component must belong to a cohesive group and should be released together.
- (CCP) The Common Closure Principle: This principle is actually the Single Responsibility Principle for components. The principle states that should gather into same component classes that changes for the same reason at the same time.
- (CRP) The Common Reuse Principle: This principle states that “should not depend on things that you don’t need it”. This principle rather tell which classes should not be put together in the same module; classes that are not tightly bound to each other should not be in the sane component.
This principles are linked together and applying them could be contradictory. The following diagram express this contradiction; each edge express the cost hat it must be payed to abandon the principle for the opposite vertex.
The component coupling principles are:
- (ADP) The Acyclic Dependencies Principle: The principle states that should have no cycle into the component dependency graph, the dependency graph should be a DAG (Directed Acyclic Graph). Solutions to eliminate dependencies cycles are: apply the Dependencies Injection Principle (DIP) or create a new component that will contain the classes that other components are depending on.
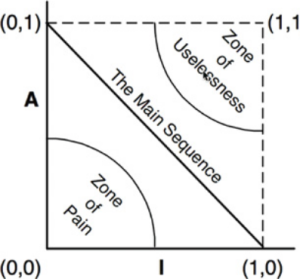
- (SDP) The Stable Dependencies Principle: This principle states that modules that are intended to be easy to change should not be dependent on by modules that are harder to change. The component stability metric, called I (for instability) is computed in the following way: I = Incoming dependencies / (Incoming dependencies + Outgoing dependencies). So SDP can be restated as :the I metric of a component should be larger than the I metric of the components that it depends on, a component should depend on more stable components only.
- (SAP)The Stable Abstraction Principle: For this principle, the author introduces a new metric called abstractness which is defined as follow: A = Number of classes in the component / Number of abstract classes and interfaces in the component. A value of 0 implies that the component have no abstract classes, a value of 1 implies that the component contains only abstract classes. The SAP principle sets up a relationship between stability (I) and abstractness (A) that have the form of a graph:
Part V Architecture
This part of the book is made of 14 chapters (almost 120 pages) and treats different aspects of a good architecture: how to define appropriate boundaries and layers (“Boundary Anatomy” chapter, “Partial Boundaries” chapter, “Layers and Boundaries” chapter, “The Test Boundary”), how to make a system that is easy to understand, develop (“The Clean Architecture” chapter, “Presenters and Humble Objects” chapter), maintain and deploy, how to organize components and services (“Screaming Architecture” chapter).
It would be very difficult to resume 120 pages in few phrases but the most important take-away would be the characteristics of a system produced by a good architecture:
- independent of any frameworks – must see the (technical) frameworks as tools and the architecture should not depend of this frameworks (“Screaming Architecture” chapter develops and argued more about this topic).
- testable – the business rules of the system should be testable without any external element.
- independent of the UI – the UI can change without affecting the use cases of the system.
- independent of the database – the business rules/ use cases should not be bounded to any database.
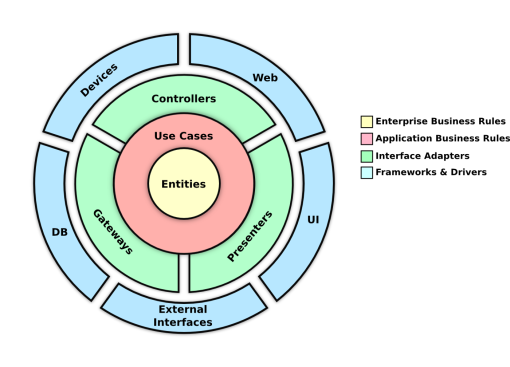
The golden rule for a clean architecture is: Source code dependencies must point only inward toward higher-level policies; any item from a circle should know nothing about the items from outer circle/s. (see the following image).
For more information for the earlier concept of Clean architecture you can check the Uncle Bob initial blog post: The Clean Architecture.
Part VI Details
The last part of the book tries to explain why some of the (technological) items used in it projects like the database, the UI technology or (technical) frameworks should not influence/contaminate the system architecture and it should always be positioned at the outer circle (see the previous image). This part also has a case study on which some of the rules and thoughts about architecture are put together and applied.









You must be logged in to post a comment.