Crée des nœuds et les attachent au VFS pour un des fichiers générés par le framework Volatility.
Utilisation :
volatility –file pathToFile
Accessible par IHM :
Oui
Accessible par shell :
Oui
Lien vers la documentation :
Pas d’informations disponibles sur le site de DFF.
Modules DFF qui modifient les contenu du VFS
Nom :
carvergui
Description :
Cherche des fichiers utilisant des patterns prédéfinis ou des patterns définis par l’utilisateur. La recherche peut être par type de fichier et/ou la présence d’un pattern dans le header ou footer du fichier.
Utilisation :
Accessible par IHM :
Oui
Accessible par shell :
Non
Lien vers la documentation :
Pas d’informations disponibles sur le site de DFF.
Nom :
find
Description :
Cherche des fichiers utilisant un regexp Python.
Utilisation :
Accessible par IHM :
Oui
Accessible par shell :
Oui
Lien vers la documentation :
Pas d’informations disponibles sur le site de DFF.
Nom :
carver
Description :
Même fonctionnalité que le module « carvergui » mais pour le shell
Utilisation :
Accessible par IHM :
Non
Accessible par shell :
Oui
Lien vers la documentation :
Pas d’informations disponibles sur le site de DFF.
Nom :
carverui
Description :
?
Utilisation :
Accessible par IHM :
Non
Accessible par shell :
Oui
Lien vers la documentation :
Pas d’informations disponibles sur le site de DFF.
Pas d’informations disponibles sur le site de DFF.
Nom :
K800i
Description :
Permet de browser le contenu d’un téléphone k800i.
Utilisation :
Accessible par IHM :
Oui
Accessible par shell :
Oui
Lien vers la documentation :
Pas d’informations disponibles sur le site de DFF.
Nom :
K800i-Recover
Description :
Permet de récupérer une version précédente du système de fichiers d’un téléphone k800i.
Utilisation :
Accessible par IHM :
Oui
Accessible par shell :
Oui
Lien vers la documentation :
Pas d’informations disponibles sur le site de DFF.
Nom :
timeline
Description :
Isole des données concernant un nœud isolé dans un intervalle de temps spécifique.
Utilisation :
Accessible par IHM :
Oui
Accessible par shell :
Non
Lien vers la documentation :
Pas d’informations disponible sur le site de DFF.
Nom :
fileschart
Description :
Affiche des statistiques graphiques sur un nœud et ses enfants. Il est conçu pour indiquer quelle proportion de chaque type de données est stockée dans le nœud.
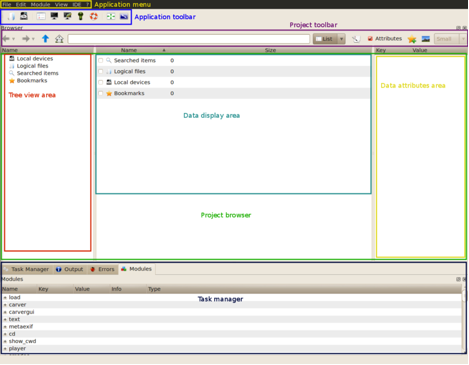
L’interface graphique de DFF est développée utilisant le framework PyQt qui est un framework graphique multi-plateformes donc DFF est capable de fonctionner sur plusieurs plateformes : Linix, FreeBSD, Windows(XP, Vista), MacOS. L’interface principale est composée de 4 zones principales :
« Application menus » – Les menus de l’application. Pour la définition détaillée de tous les menus, veuillez consulter la page suivante du wiki DFF.
« Application toolbar » – La barre d’outils est utilisée pour effectuer des actions telles que l’ajout d’un container des données ou d’un disc en DFF, ou l’ouverture de vues graphiques. Pour la définition détaillée de la barre d’outils, veuillez consulter la page suivante du wiki DFF.
« Project Browser » – La zone où les résultats des analyses seront affichés. Il peut être comparé à un navigateur de fichiers sur un système d’exploitation. Pour la définition détaillée du « project bowser », veuillez consulter la page suivante du wiki DFF.
« Project Toolbar » Cette zone serve à modifier l’affichage des résultats d’analyse et de naviguer dans les résultats de l’analyse.
« Task Manager » – Zone qui montre l’historique des tâches exécutées, les messages d’erreurs et d’information générés par l’exécution des différents modules et la liste des modules qui peuvent être utilisés, avec la liste des paramètres, qu’ils peuvent prendre en entrée. Pour la définition détaillée du « task manager », veuillez consulter la page suivante du wiki DFF.
L’interface graphique de DFF
Cas pratique IHM (chercher des fichiers d’images dans un container EWF)
Ce cas pratique a comme but de charger un container de données EWF et de chercher des fichiers de type JPG.
Les étapes du cas pratique sont les suivantes :
charger le container des données ;
monter le système de fichiers contenu dans le container ;
chercher des fichiers d’images sur le système de fichiers ;
sauver les fichiers retrouvés sur le disque.
Charger le container de données
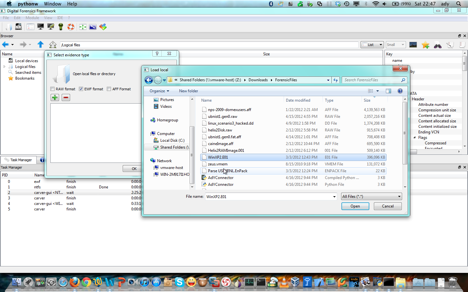
Dans le menu File-> « Open evidence file(s) » ou dans la barre d’outils click sur l’icône . Ensuite on choisit le container de données a charger (voir la figure suivante).
Chargement d’un container de données dans l’IHM de DFF
Même si c’est n’est pas visible, l’IHM de DFF a utilisé le module ewf pour créer n VFS.
Monter le système de fichiers contenu dans le container
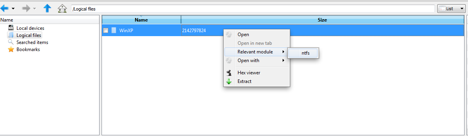
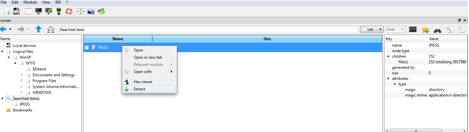
Une fois le container chargé, il faut monter le système de fichiers. DFF est capable de savoir que le container chargé contient un système de fichiers NTFS et vas automatiquement utiliser le module ntfs. Pour appliquer le module ntfs sur le container il faut aller dans le « Data display area » et faire un click droit ensuite choisir l’option « Relevant module » (voir la figure suivante). On voit ensuite apparaitre l’arborescence du disque après le traitement par le module NTFS.
Chargement d’un système de fichiers NTFS dans l’IHM de DFF
Chercher des fichiers d’images sur le système de fichiers
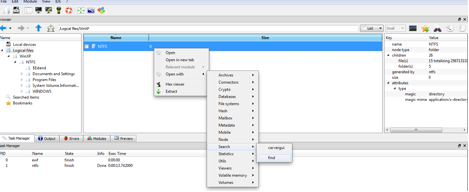
Une fois le système de fichiers chargé, on peut naviguer sur ce système de fichiers ou on peut appliquer des modules pour récupérer d’informations. On appliquera le module find sur le nœud NTFS (voir figure suivante) :
L’utilisation du module “find” sur un noeud NTFS
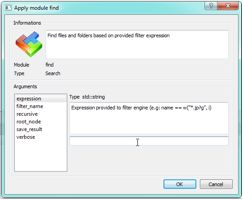
Le module find accepte quelques paramètres comme le nom du filtre (ce nom sera utilisé pour créer un nouveau nœud dans le VFS contenant les résultats de la recherche), si la recherche est récursive ou pas, l’expression utilisée pour rechercher des fichiers (dans notre cas l’expression sera name == w(“*.jp?g”, i)).
Les paramètres du module “find”
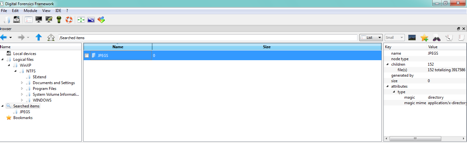
Le module find a trouvé des fichiers et a stocké les résultats dans le nouveau nœud du VFS nommé comme le nom du filtre. Ce nouveau nœud est attaché au noeud « Searched Items » (voir la figure suivante).
Le résultats de l’exécution du module “find”
Sauver les fichiers retrouvés sur le disque
La dernière étape consiste à extraire les résultats trouvés a l’étape précédente sur le disque. Pour transformer un nœud du VFS en fichier (physique) sur le disque, il faut utiliser le module extract.
L’utilisation du module “extract”
L’interface en ligne de commande de DFF
A part l’interface graphique, DFF a aussi une interface en ligne de commande (CLI). Il y a deux façons de démarrer l’interface en ligne de commande :
a partir de l’IHM de DFF en cliquant sur l’icône (shell) dans la barre d ‘outils
en exécutant la commande dff.py à partir d’une console.
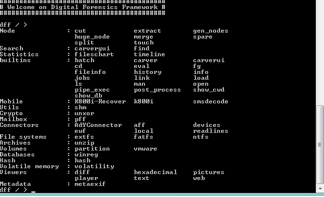
L’utilisation de l’interface en ligne de commande suit le même patron de conception (‘’pattern’’) que l’utilisation de l’IHM. Dans la figure suivante, on peut voir tous les modules disponibles à partir de la ligne de commande.
L’interface en ligne de commande de DFF
Les scripts sont une des nouvelles fonctionnalités de la version 1.2 de DFF. Les scripts sont des fichiers contenant des commandes shell DFF et peuvent être exécutés utilisant la ligne de commande suivante dff.py –b leFichierDeScript.
Cas pratique scripting (chercher des fichiers d’images dans un container EWF)
On prend le même cas pratique que celui utilisé pour illustrer l’utilisation de l’IHM. Le script qui exécute les mêmes actions que celles de l’IHM est le suivant :
#charger le container de données utilisant le module ewf ewf WinXP2.E01#monter le système de fichiers utilisant le module ntfsntfs WinXP#utiliser le module find pour chercher des fichiersfind /WinXP/NTFS --filter_name jpg_images --recursive --save_result
--expression 'name==w("*.jp?g",i)'
#utiliser le module extract pour stocker sur disque les images
#retrouvées par le module find extract --recursive --files Searched\ items/jpg_images --syspath ./
L’idée des scripts DFF semble être très bonne, pourtant dans la version actuelle, l’implémentation ne semble pas totalement achevée. Parmi les principaux défauts de cette implémentation, le plus évident est le fait de ne pas pouvoir récupérer le code de retour de l’exécution d’une commande (module). La deuxième faiblesse est l’absence totale d’instructions conditionnelles et des boucles. Ces deux défauts rendent impossible la création et l’exploitation des scripts automatiques pour la plateforme DFF.
Le produit commercial DFF Live
Depuis le mois de Juin 2012, ArxSys commercialise un produit basé sur DFF, appelé « DFF Live » [DFFLIVE]. DFF Live est livré sur une clé USB et est présenté comme un laboratoire d’investigation digitale nomade.
D’après la société ArxSys, le produit « DFF Live » a des fonctionnalités d’investigation numérique des systèmes vivants (liste de connexions réseaux, extraction des fichiers de temporaires, collection des données volatiles) et des fonctionnalités d’investigation numérique a froid (analyse des différents systèmes des fichiers, analyse des journaux d’évènements Windows, récupération des données cachées et supprimées).
Conclusion
Le framework DFF est un produit assez nouveau, mais pourtant il commence à avoir une certaine reconnaissance internationale. Le produit est présent dans certaines distributions numériques comme DEFT, BackTrack et SAN SIFT. DFF est facile à installer et l’interface graphique est ergonomique et facile a utiliser. Techniquement parlant, DFF a certains atouts : il est multi-plateformes, la notion de système de fichiers virtuel (VFS) rend la compréhension du framework plus facile, la possibilité d’étendre les fonctionnalités de base par l’ajout des modules écrits en Python. Par contre, DFF manque cruellement d’une documentation claire et précise, surtout pour les développeurs (il n’y a pas de documentation de l’api Python concernant le VFS).
Very short chapter (2 pages and 1/2) in which the author gives his definition of a hacker; person that find unusual solutions to any kind of problems, not only technical problems. The author also expresses very clearly the goal of his book: “The intent of this book is to teach you the true spirit of hacking. We will look at various hacking techniques, from the past to the present, dissecting them to learn how and why they work”.
Chapter 0x200 Programming
The chapter is an introduction to C programming language and to assembler for Intel 8086 processors. The entry level is very low, it starts by explaining the use of pseudo-code and then very gradually introduces many of the structures of the C language: variables, variables scopes, control structures, structs, functions, pointers (don’t expect to have a complete introduction to C or to find advanced material).
The chapter contains a lot of code examples very clearly explained using the GDB debugger. Since all the examples are running under Linux, the last part of the chapter contains some basics about the programming on Linux operating system like file permissions, uid, guid, setuid.
Chapter 0x300 Exploitation
This chapter it builds on the knowledge learned in the previous one and it’s dedicated to the buffer overflow exploits. The most part of the chapter treats the stack-based buffer overflow in great detail using gradual complexity examples. Overflow vulnerabilities on other memory segments are also presented, overflows on the heap and on the BSS.
The last part of the chapter is about format string exploits. Some of the string vulnerabilities use specific GNU C compiler structures (.dtors and .ctors). In almost all the examples, the author uses the GDB to explain the details of the vulnerabilities and of the exploits.
One negative remark is that in some of the exploits the author use shell codes without explaining how these shell codes have been crafted (on the other side an entire chapter is devoted to shell codes).
Chapter 0x400 Networking
This chapter is dedicated to the network hacking(s) and can be split in 3 parts. The first part is rather theoretical, the ISO OSI model is presented and some of the layers (data-link layer, network layer and transport layer) are explained in more depth.
The second part of the chapter is more practical; different network protocols are presented like ARP, ICMP, IP, TCP; the author explains the structure of the packets/datagrams for the protocols and the communication workflow between the hosts. On the programming side, the author makes a very good introduction to sockets in the C language.
The third part of the chapter is devoted to the hacks and is build on the top of the first two parts. For the package sniffing hacks the author introduces the libpcap library and for the package injection hacks the author uses the libnet library (ARP cache poisoning, SYN flooding, TCP RST hijacking). Other networking hacks are presented like different port scanning techniques, denial of service and the exploitation of a buffer overflow over the network. In most of the hacks the authors it’s crafting his own tools but sometimes he uses tools like nemesis and nmap.
This chapter is an introduction to the shellcode writing. In order to be injected in the target program the shelcode must be as compact as possible so the best suitable programing language for this task is the assembler language.
The chapter starts with an introduction to the assembler language for the Linux platform and continues with an example of a “hello word” shellcode. The goal of the “hello word” shellcode is to present different techniques to make the shellcode memory position-independent.
The rest of the chapter is dedicated to the shell-spawning(local) and port-binding (remote) shellcodes. In both cases the same presentation pattern is followed: the author starts with an example of the shellcode in C and then he translates and adapts (using GDB) the shellcode in assembler language.
Chapter 0x600 Countermeasures
The chapter is about the countermeasures that an intruder should apply in order to cover his tracks and became as undetectable as possible but also the countermeasures that a victim should apply in order reduce or nullify the effect of an attack.
The chapter is organized around the exploits of a very simple web server. The exploits proposed are increasingly complex and stealthier; from the “classical” port-biding shellcode that can be easily detected to more advanced camouflage techniques like forking the shellcode in order to keep the target program running, spoofing the logged IP address of the attacker or reusing an already open socket for the shellcode communication.
In the last part of the chapter some defensive countermeasures are presented like non-executable stack and randomized stack space. For each of this hardening countermeasures some partial workarounds are explained.
Chapter 0x700 Cryptology
The last chapter treats the cryptology, an subject very hard to explain to a neophyte. The first part of the chapter contains information about the algorithmic complexity, the symmetric and asymmetric encryption algorithms; the author brilliantly demystifies the operation of the RSA algorithm.
On the hacking side the author presents some attacks linked to the cryptography like the man-in-the-middle attack of an SSL connection (using the mitm-ssh tool and THC Fuzzy Fingerprint) and cracking of passwords generated by Linux crypt function (using dictionary attacks, brute-force attacks and rainbow tables attacks).
The last part of the chapter is quite outdated in present day (the book was edited in 2008) and is dedicated to the wireless 802.11 b encryption and to the weaknesses of the WEP.
Chapter 0x800 Conclusion
As for the introduction chapter, this chapter is very short and as in the first chapter the authors repeats that the hacking it’s state of mind and the hackers are people with innovative spirits.
(My) Conclusion
The book it’s a very good introduction to different technical topics of IT security. Even if the author tried to make the text easy for non-technical peoples (the chapter about programming starts with an explanation about pseudo-codes) some programming experience is required (ideally C/C++) in order to get the best of this book.
Digital Forensic Framework [DFF] est un logiciel open source développé par ArxSys[ARXSYS]. C’est un nouvel arrivant dans le monde des logiciels d’investigation numérique. Il se veut être multiplateforme, automatisable, portable et modulaire.
DFF est un outil d’analyse et présentation de données et il est capable d’extraire, analyser et mettre en corrélation des traces suspectes et des données de différents fichiers, provenant d’acquisitions de supports numériques, tels que les disques durs, la mémoire vive ou les téléphones cellulaires. Il peut également être utilisé pour récupérer des données supprimées.
Écrit en Python et C++, il est multi-plateforme, hautement modulaire et personnalisable. L’interface graphique est développée avec PyQt [PYQT]. L’interfaçage et les transformations entre Python et C++ sont obtenus grâce à Swig [SWIG].
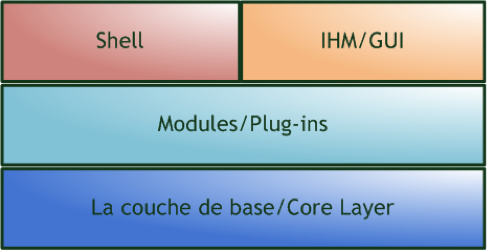
DFF est divisé en quatre différentes couches logicielles (voir la figure suivante), communiquant entre elles par une interface de programmation applicative (API) : la couche de base (Core Layer), les modules, l’interface utilisateur et le shell.
Les couches logicielles de DFF
La couche de base de DFF
Cette couche peut être considérée comme le cœur du framework. Elle fait l’interface avec le système d’exploitation et est utilisée pour charger et exécuter les modules. L’exécution des modules est automatique car la couche de base est conçue pour savoir quel module est requis et ensuite l’exécuter. Cette couche offre également aux modules la possibilité de renvoyer les données analysées sous la forme de nœuds (dans un arbre).
L’espace mémoire où ces nœuds sont créés est appelé un Système de Fichiers Virtuel (VFS pour Virtual File System). Chaque nœud peut être généré par un module différent et avoir des attributs spécifiques. Ce mécanisme permet à la couche de base de générer des rapports en mettant en corrélation toutes les données en provenance des modules, tout en restant indépendant des modules eux-mêmes. Même si un module plante après la création des nœuds, la couche de base sera en mesure d’exploiter ces nœuds. Les modules étant conçus pour l’investigation numérique, ils permettent aussi de révéler les données non allouées et cachées.
DFF offre aux utilisateurs une vue arborescente des données analysées. Par exemple, si un système de fichiers NTFS est analysé, tout son contenu sera visible dans l’interface graphique DFF, sous la forme d’un arbre: chaque répertoire contenant des fichiers et des répertoires, eux-mêmes contenant des fichiers et des répertoires, et ainsi de suite. DFF agit plus ou moins comme un navigateur de fichiers sur n’importe quel système d’exploitation. Dans DFF ces fichiers et répertoires sont appelés nœuds. Les nœuds sont créés par des modules suite à une analyse des données.
Les nœuds sont stockés dans un espace mémoire appelé VFS (Virtual File System). Le VFS peut être vu comme un système de fichiers en lecture seule utilisés par DFF pour stocker les nœuds. Lorsque DFF est lancé, une et une seule instance de VFS est créée ; dans d’autres termes, VFD est un singleton.
Les VFS contient la liste de tous les nœuds et chacun des nœuds contient un pointeur vers le nœud de son parent (ou NULL pour le nœud racine) et une liste de pointeurs vers ses enfants (le cas échéant).
Un nœud peut représenter pratiquement n’importe quel type de données. Une fois qu’il est créé, il devrait être ajouté au VFS afin qu’il puisse être visible dans l’interface graphique ou shell. Les deux caractéristiques importantes d’un nœud sont son nom et sa taille Si rien n’est défini, les valeurs par défaut sont une chaîne vide pour le nom et 0 octet pour la taille.
Mais ces informations pourraient ne pas suffire. Nous avons dit qu’un nœud peut représenter n’importe quel type de données. Si l’on prend comme exemple, un fichier d’un système de fichiers, le nœud aura un nom et une taille (donnés par le système de fichiers) mais aussi beaucoup d’autres informations telles que les métadonnées, les pointeurs pour indiquer la position de son contenu sur le système de fichiers, etc.
Dans DFF, ces informations supplémentaires sont appelées des attributs étendus. Ces attributs sont composés d’une liste de paires clé/valeur, où la clé doit être une chaîne de caractères.
Les modules DFF
Chaque module DFF est conçu pour analyser un type spécifique de données, tels que les systèmes de mémoire RAM de fichiers, ou des cadres du réseau. Les modules créent des nœuds, les attachent au VFS, et en fonction du type de données, génèrent des informations supplémentaires telles que les indications de temps ou métadonnées d’extraction.
La version actuelle de la DFF (1.2 au moment de la rédaction du présent rapport) est livrée avec de nombreux modules qui effectuent des tâches diverses : le traitement des images mémoire des téléphones mobiles, la visualisation des films et des images, la génération des statistiques sur un nœud ou un ensemble de nœuds. Comme toutes les tâches d’analyse dans DFF sont effectuées via des modules, l’interface de programmation (API) a un grand nombre de fonctionnalités disponibles. Des modules supplémentaires peuvent être écrits en C++ ou Python.
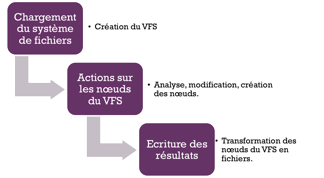
Les modules contenus en DFF peuvent être classées en 3 catégories (voir le schéma suivant):
les modules qui chargent des systèmes de fichiers/volumes/partitions.
les modules qui actionnent sur les nœuds du VFS.
les modules qui matérialisent les nœuds du VFS en fichiers sur disque.
Classification des modules DFF
Modules qui chargent des systèmes de fichiers/volumes/partitions
Le tableau suivant liste les modules DFF.
Fonctionnalité
Module
Shell
IHM
Commentaire
Container de données
local
Oui
Oui
ewf
Oui
Oui
aff
Oui
Oui
Pas d’information disponible
device
Oui
Oui
readlines
Oui
Oui
Pas d’information disponible
Partition
partition
Oui
Oui
vmware
Oui
Oui
Système des fichiers
fat
Oui
Oui
ntfs
Oui
Oui
efs
Oui
Oui
Contenu du RAM
volatility
Oui
Oui
Pas d’information disponible
Modules qui actionnent sur les nœuds du VFS
Une fois que le système de fichiers est chargé, DFF offre une vue arborescente du système de fichiers, arborescence sur laquelle d’autres modules sont capables de travailler. Parmi les fonctionnalités offerts, on peut trouver des modules qui affichent le contenu d’un nœud (hexadecimal, diff, picture, text, web, player), des modules qui sont capables des chercher des nœuds ayant certains caractéristiques (find, carver).
Le tableau suivant liste les modules DFF.
Fonctionnalité
Module
Shell
IHM
Commentaire
Chercher
find
Oui
Oui
carver
Oui
Non
carverui
Oui
Non
Pas d’information disponible
carvergui
Non
Oui
Pas d’information disponible
Visualiser
hexadecinal
Oui
Oui
diff
Oui
Oui
pictures
Non
Oui
text
Oui
Oui
player
Non
Oui
Pas d’information disponible
web
Non
Oui
Pas d’information disponible
Archiver
unzip
Oui
Oui
Chiffrement
unxor
Oui
Oui
Base de données
Winreg
Oui
Oui
Hachage
hash
Oui
Oui
Métadonnées pour les images
metaexif
Oui
Oui
Téléphones mobiles
smsdecode
Oui
Oui
Pas d’information disponible
k800i
Oui
Oui
Pas d’information disponible
K800-i-Recover
Oui
Oui
Pas d’information disponible
Statistiques
timeline
Non
Oui
fileschart
Non
Oui
Pas d’information disponible
Modules qui matérialisent les nœuds du VFS en fichiers sur disque
La dernière étape d’une analyse avec DFF est la récupération des résultats qui consistent donc à matérialiser un ou plusieurs nœuds du VFS dans des fichiers sur disque.
Fonctionnalité
Module
Shell
IHM
Commentaire
Ecrire nœuds sur disque
extract
Oui
Oui
Pas d’information disponible
Modules définis par l’utilisateur
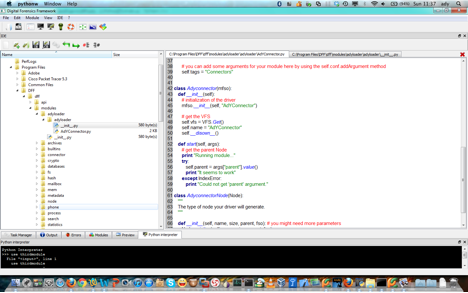
DFF offre la possibilité à l’utilisateur de créer ses propres modules utilisant l’IDE inclus dans DFF. L’IDE de DFF peut être utilisé pour générer des squelettes des scripts DFF, de modules ou de modules graphiques. Pour le lancer, vous pouvez utiliser l’icône de la barre d’outils d’application ou à partir du menu IDE -> Open.
La figure suivante présente une capture d’écran de l’IDE de DFF :
L’ide de DFF
La partie gauche est utilisée pour naviguer sur le système de fichiers et pour sélectionner le fichier à ouvrir (seuls les fichiers Python peut être ouvert). Pour ouvrir un fichier cliquez deux fois sur son nom et son contenu sera affiché.
Voici la description des différentes icônes de la barre d’outils:
New empty file : Ouvre un fichier vide dans l’IDE.
Generate skeleton : Lance l’assistant pour générer le squelette d’un nouveau module.
Open file : Ouvre un fichier existant.
Save : Sauve le fichier.
Save as : Sauve un fichier sous un nom choisi par l’utilisateur.
Load : Compile le module et le charge dynamiquement en DFF.
Undo : Annule l’action précédente.
Redo : Répete l’action precedente.
Comment : Commente la ligne sur laquelle le curseur de la souris se trouve.
Uncomment : « Dé-commente » la ligne sur laquelle le curseur de la souris se trouve.
L’IDE de DFF permet de créer très rapidement un squelette d’un module et donc facilite la tâche du développeur. Par contre, pour créer un module ayant une certaine utilité, il faut aussi connaître l’API (Python) de DFF.
Some (big) Excel files generated using Apache POI cannot be correctly open by Excel (none of the styles applied to the cells are rendered). The error message shown by Excel is the following one :
Removed Feature: Format from /xl/styles.xml part (Styles)
Repaired Records: Cell information from /xl/worksheets/sheet1.xml part
Cell information from /xl/worksheets/sheet2.xml part
Repaired Records: Cell information from /xl/worksheets/sheet3.xml part
The cause
The root cause is that Excel can handle only a limited number of cell styles by workbook; Excel 2010 for example can handle 4000 cell style by workbook (see Excel specifications and limits).













You must be logged in to post a comment.