Goal of this article

The goal of this article is to present an implementation of the “double submit cookie” pattern used to mitigate the Cross Site Request Forgery (CSRF) attacks. The proposed implementation is a Java filter plus a few auxiliary classes and it is (obviously) suitable for projects using the Java language as back-end technology.
Definition of CSRF and possible mitigations
In the case of a CSRF attack, the browser is tricked into making unauthorized requests on the victim’s behalf, without the victim’s knowledge. The general attack scenario contains the following steps:
- the victim connects to the vulnerable web-site, so it have a real, authenticated session.
- the hacker force the victim (usually using a spam/fishing email) to navigate to another (evil) web-site containing the CSRF attack.
- when the victim browser execute the (evil) web-site page, the browser will execute a (fraudulent) request to the vulnerable web-site using the user authenticated session. The user is not aware at all of the fact that navigating on the (evil) web-site will trigger an action on the vulnerable web-site.
For deeper explanations I strongly recommend to read chapter 5 of Iron-Clad Java: Building Secure Applications book and/or the OWASP Cross-Site Request Forgery (CSRF) Prevention Cheat Sheet.
Definition of “double submit cookie” pattern
When a user authenticates to a site, the site should generate a (cryptographically strong) pseudo-random value and set it as a cookie on the user’s machine separate from the session id. The server does not have to save this value in any way, that’s why this patterns is sometimes also called Stateless CSRF Defense.
The site then requires that every transaction request include this random value as a hidden form value (or other request parameter). A cross origin attacker cannot read any data sent from the server or modify cookie values, per the same-origin policy.
In the case of this mitigation technique the job of the client is very simple; just retrieve the CSRF cookie from the response and add it into a special header to all the requests:
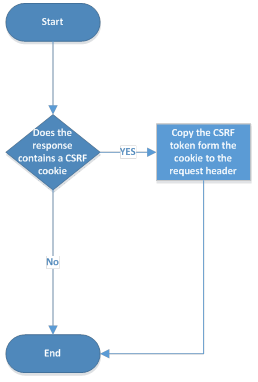
The job of the server is a little more complex; create the CSRF cookie and for each request asking for a protected resource, check that the CSRF cookie and the CSRF header of the request are matching:
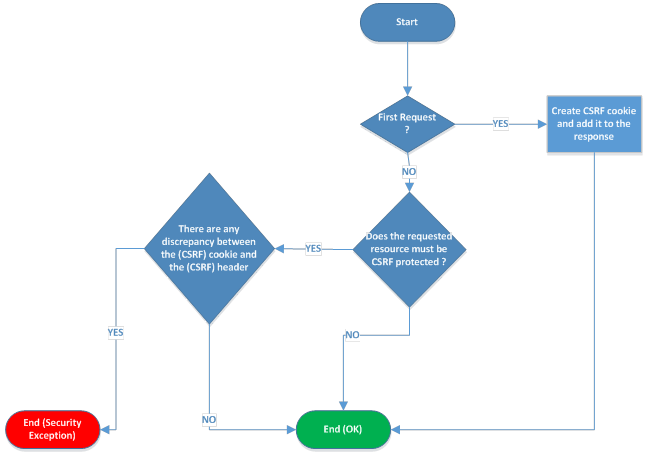
Note that some JavaScript frameworks like AngularJS implements the client worflow out of the box; see Cross Site Request Forgery (XSRF) Protection
Java implementation of “double submit cookie” pattern
The proposed implementation is on the form of a (Java) Servlet filter and can be found here: GenericCSRFFilter GitHub.
In order to use the filter, you must define it into you web.xml file:
<filter> <filter-name>CSRFFilter</filter-name> <filter-class>com.github.adriancitu.csrf.GenericCSRFStatelessFilter</filter-class> <filter> <filter-mapping> <filter-name>CSRFFilter</filter-name> <url-pattern>/*</url-pattern> </filter-mapping>
The filter can have 2 optional initialization parameters: csrfCookieName representing the name of the cookie that will store the CSRF token and csrfHeaderName representing the name of the HTTP header that will be also contains the CSRF token.
The default values for these parameters are “XSRF-TOKEN” for the csrfCookieName and “X-XSRF-TOKEN” for the csrhHeaderName, both of them being the default values that AngularJS is expecting to have in order to implement the CSRF protection.
By default the filter have the following features:
- works with AngularJS.
- the CSRF token will be a random UUID.
- all the resources that are NOT accessed through a GET request method will be CSRF protected.
- the CSRF cookie is replaced after each non GET request method.
How it’s working under the hood
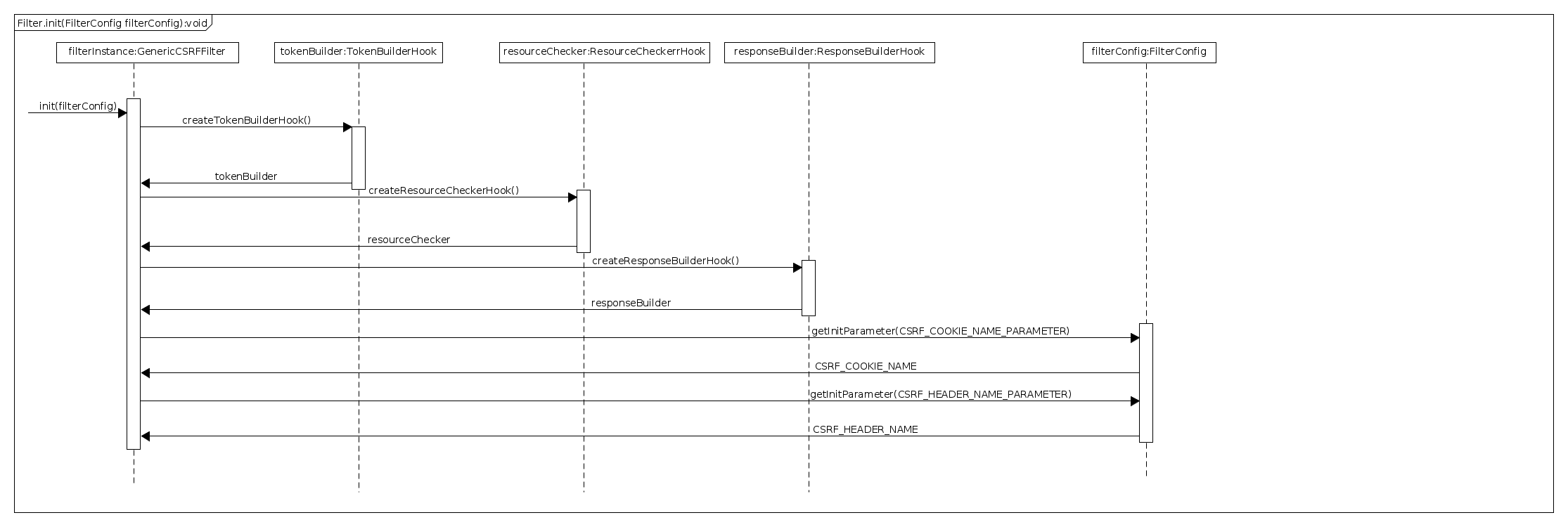
The most of the functionality is in the GenericCSRFStatelessFilter#doFilter method; here is the sequence diagram that explains what’s happening in this method:

The doFilter method is executed on each HTTP request:
- The filter creates an instance of ExecutionContext class; this class is a simple POJO containing the initial HTTP request, the HTTP response, the CSRF cookies (if more than one cookie with the csrfCookieName is present) and implementation of the ResourceCheckerHook , TokenBuilderHook and ResponseBuilderHook .(see the next section for the meaning of this classes).
- The filter check the status of the HTTP resource, that status can be:MUST_NOT_BE_PROTECTED, MUST_BE_PROTECTED_BUT_NO_COOKIE_ATTACHED,MUST_BE_PROTECTED_AND_COOKIE_ATTACHED (see ResourceStatus enum) using an instance of ResourceCheckerHook.
- If the resource status is ResourceStatus#MUST_NOT_BE_PROTECTED
ResourceStatus#MUST_BE_PROTECTED_BUT_NO_COOKIE_ATTACHED then
the filter creates a CSRF cookie having as token the token generated by an instance of TokenBuilderHook. - if the resource status ResourceStatus#MUST_BE_PROTECTED_AND_COOKIE_ATTACHED
then compute the CSRFStatus of the resource and then use an instance of ResponseBuilderHook to return the response to the client.
How to extend the default behavior
It is possible to extend or overwrite the default behavior by implementing the hooks interfaces. All the hooks implementations must be thread safe.
- The ResourceCheckerHook is used to check the status of a requested resource. The default implementation is DefaultResourceCheckerHookImpl and it will return ResourceStatus#MUST_NOT_BE_PROTECTED for any HTTP GET method, for all the other request types, it will return {@link ResourceStatus#MUST_BE_PROTECTED_BUT_NO_COOKIE_ATTACHED if any CSRF cookie is present in the query or ResourceStatus#MUST_BE_PROTECTED_BUT_NO_COOKIE_ATTACHED otherwise.The interface signature is the following one:
public interface ResourceCheckerHook extends Closeable { ResourceStatus checkResourceStatus(ExecutionContext executionContext); } - The TokenBuilderHook hook is used to generate the token that will be used to create the CSRF cookie. The default implementation is DefaultTokenBuilderHookImpl and it uses a call to UUID.randomUUID to fetch a token. The interface signature is the following one:
public interface TokenBuilderHook extends Closeable { String buildToken(ExecutionContext executionContext); } - The ResponseBuilderHook is used to generate the response to the client depending of the CSRFStatus of the resource. The default implementation is DefaultResponseBuilderHookImpl and it throws a SecurityException if the CSRF status is CSRFStatus#COOKIE_NOT_PRESENT, CSRFStatus#HEADER_TOKEN_NOT_PRESENT or CSRFStatus#COOKIE_TOKEN_AND_HEADER_TOKEN_MISMATCH. If the CSRF status is CSRFStatus#COOKIE_TOKEN_AND_HEADER_TOKEN_MATCH then the old CSRF cookies are deleted and a new CSRF cookie is created. The interface signature is the following one:
public interface ResponseBuilderHook extends Closeable { ServletResponse buildResponse(ExecutionContext executionContext, CSRFStatus status); }
The hooks are instantiated inside the GenericCSRFStatelessFilter#init method using the ServiceLoader Java 6 loading facility. So if you want to use your implementation of one of the hooks then you have to create a META-INF/services directory that contains a text file whose name matches the fully-qualified interface class name of the hook that you want to replace.
Here is the sequence diagram representing the hooks initializations:

 ElasticSeach index. I will take as example the
ElasticSeach index. I will take as example the 

You must be logged in to post a comment.